Robust Text Classifier on Test-Time Budgets
Md Rizwan Parvez, Tolga Bolukbasi, Kai-Wei Chang, and Venkatesh Saligrama, in EMNLP (short), 2019.
Slides CodeDownload the full text
Abstract
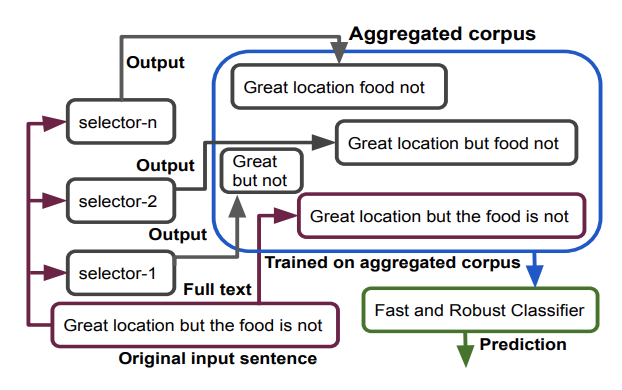
We propose a generic and interpretable learning framework for building robust text classification model that achieves accuracy comparable to full models under test-time budget constraints. Our approach learns a selector to identify words that are relevant to the prediction tasks and passes them to the classifier for processing. The selector is trained jointly with the classifier and directly learns to incorporate with the classifier. We further propose a data aggregation scheme to improve the robustness of the classifier. Our learning framework is general and can be incorporated with any type of text classification model. On real-world data, we show that the proposed approach improves the performance of a given classifier and speeds up the model with a mere loss in accuracy performance.
Bib Entry
@inproceedings{parvez2019robust,
author = {Parvez, Md Rizwan and Bolukbasi, Tolga and Chang, Kai-Wei and Saligrama, Venkatesh},
title = {Robust Text Classifier on Test-Time Budgets},
booktitle = {EMNLP (short)},
year = {2019}
}
Related Publications
- Efficient Contextual Representation Learning With Continuous Outputs, TACL, 2019
- Distributed Block-diagonal Approximation Methods for Regularized Empirical Risk Minimization, Machine Learning Journal, 2019
- Structured Prediction with Test-time Budget Constraints, AAAI, 2017
- A Credit Assignment Compiler for Joint Prediction, NeurIPS, 2016
- Learning to Search for Dependencies, Arxiv, 2015
- Learning to Search Better Than Your Teacher, ICML, 2015
- Structural Learning with Amortized Inference, AAAI, 2015