Retrofitting Contextualized Word Embeddings with Paraphrases
Weijia Shi, Muhao Chen, Pei Zhou, and Kai-Wei Chang, in EMNLP (short), 2019.
Slides CodeDownload the full text
Abstract
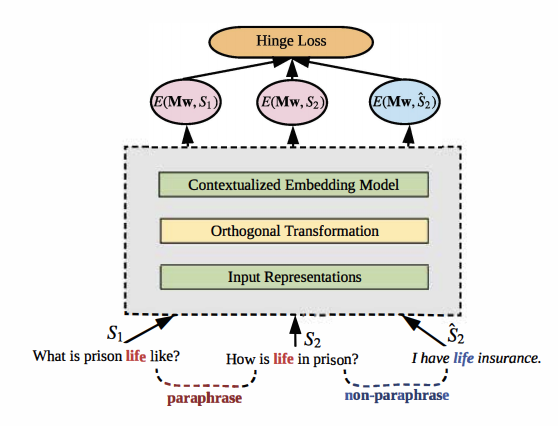
Contextualized word embedding models, such as ELMo, generate meaningful representations of words and their context. These models have been shown to have a great impact on downstream applications. However, in many cases, the contextualized embedding of a word changes drastically when the context is paraphrased. As a result, the downstream model is not robust to paraphrasing and other linguistic variations. To enhance the stability of contextualized word embedding models, we propose an approach to retrofitting contextualized embedding models with paraphrase contexts. Our method learns an orthogonal transformation on the input space, which seeks to minimize the variance of word representations on paraphrased contexts. Experiments show that the retrofitted model significantly outperforms the original ELMo on various sentence classification and language inference tasks.
In the same session, I just presented our work on Retrofitting Contextualized Word Embeddings with Paraphrases. https://t.co/57ye6WtjWm @emnlp2019 #emnlp pic.twitter.com/PuYoPtbLzF
— Muhao Chen (@muhao_chen) November 5, 2019
Bib Entry
@inproceedings{shi2019retrofitting,
author = {Shi, Weijia and Chen, Muhao and Zhou, Pei and Chang, Kai-Wei},
title = {Retrofitting Contextualized Word Embeddings with Paraphrases},
booktitle = {EMNLP (short)},
vimeo_id = {430797636},
year = {2019}
}
Related Publications
- VideoCon: Robust video-language alignment via contrast captions, CVPR, 2024
- CleanCLIP: Mitigating Data Poisoning Attacks in Multimodal Contrastive Learning, ICCV, 2023
- Red Teaming Language Model Detectors with Language Models, TACL, 2023
- ADDMU: Detection of Far-Boundary Adversarial Examples with Data and Model Uncertainty Estimation, EMNLP, 2022
- Investigating Ensemble Methods for Model Robustness Improvement of Text Classifiers, EMNLP-Finding (short), 2022
- Unsupervised Syntactically Controlled Paraphrase Generation with Abstract Meaning Representations, EMNLP-Finding (short), 2022
- Improving the Adversarial Robustness of NLP Models by Information Bottleneck, ACL-Finding, 2022
- Searching for an Effiective Defender: Benchmarking Defense against Adversarial Word Substitution, EMNLP, 2021
- On the Transferability of Adversarial Attacks against Neural Text Classifier, EMNLP, 2021
- Defense against Synonym Substitution-based Adversarial Attacks via Dirichlet Neighborhood Ensemble, ACL, 2021
- Double Perturbation: On the Robustness of Robustness and Counterfactual Bias Evaluation, NAACL, 2021
- Provable, Scalable and Automatic Perturbation Analysis on General Computational Graphs, NeurIPS, 2020
- On the Robustness of Language Encoders against Grammatical Errors, ACL, 2020
- Robustness Verification for Transformers, ICLR, 2020
- Learning to Discriminate Perturbations for Blocking Adversarial Attacks in Text Classification, EMNLP, 2019
- Generating Natural Language Adversarial Examples, EMNLP (short), 2018