Efficient Shapley Values Estimation by Amortization for Text Classification
Chenghao Yang, Fan Yin, He He, Kai-Wei Chang, Xiaofei Ma, and Bing Xiang, in ACL, 2023.
Download the full text
Abstract
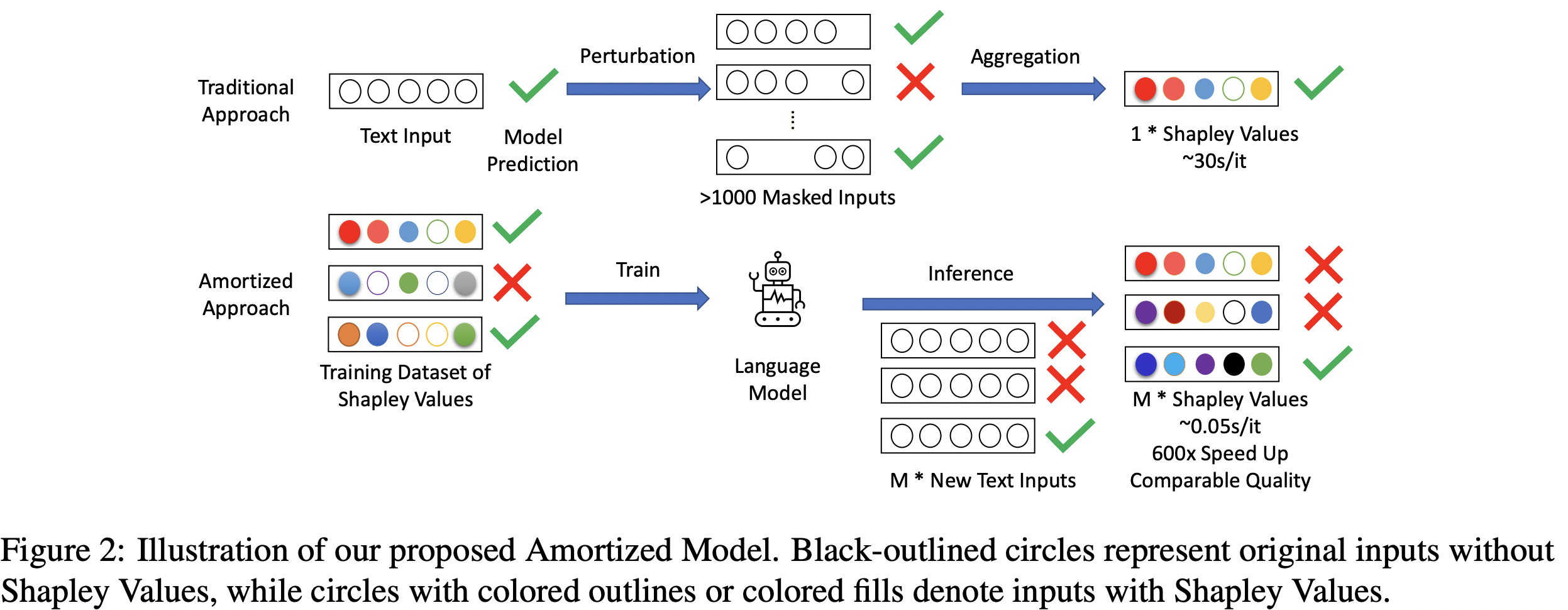
Despite the popularity of Shapley Values in explaining neural text classification models, computing them is prohibitive for large pretrained models due to a large number of model evaluations as it needs to perform multiple model evaluations over various perturbed text inputs. In practice, Shapley Values are often estimated stochastically with a smaller number of model evaluations. However, we find that the estimated Shapley Values are quite sensitive to random seeds – the top-ranked features often have little overlap under two different seeds, especially on examples with the longer input text. As a result, a much larger number of model evaluations is needed to reduce the sensitivity to an acceptable level. To mitigate the trade-off between stability and efficiency, we develop an amortized model that directly predicts Shapley Values of each input feature without additional model evaluation. It is trained on a set of examples with Shapley Values estimated from a large number of model evaluations to ensure stability. Experimental results on two text classification datasets demonstrate that, the proposed amortized model can estimate black-box explanation scores in milliseconds per sample in inference time and is up to 60 times more efficient than traditional methods.
Bib Entry
@inproceedings{yang2023efficient,
title = {Efficient Shapley Values Estimation by Amortization for Text Classification},
author = {Yang, Chenghao and Yin, Fan and He, He and Chang, Kai-Wei and Ma, Xiaofei and Xiang, Bing},
year = {2023},
presentation_id = {https://underline.io/events/395/sessions/15249/lecture/76179-efficient-shapley-values-estimation-by-amortization-for-text-classification},
booktitle = {ACL}
}
Related Publications
No related publications found.