SentiBERT: A Transferable Transformer-Based Architecture for Compositional Sentiment Semantics
Da Yin, Tao Meng, and Kai-Wei Chang, in ACL, 2020.
Slides CodeDownload the full text
Abstract
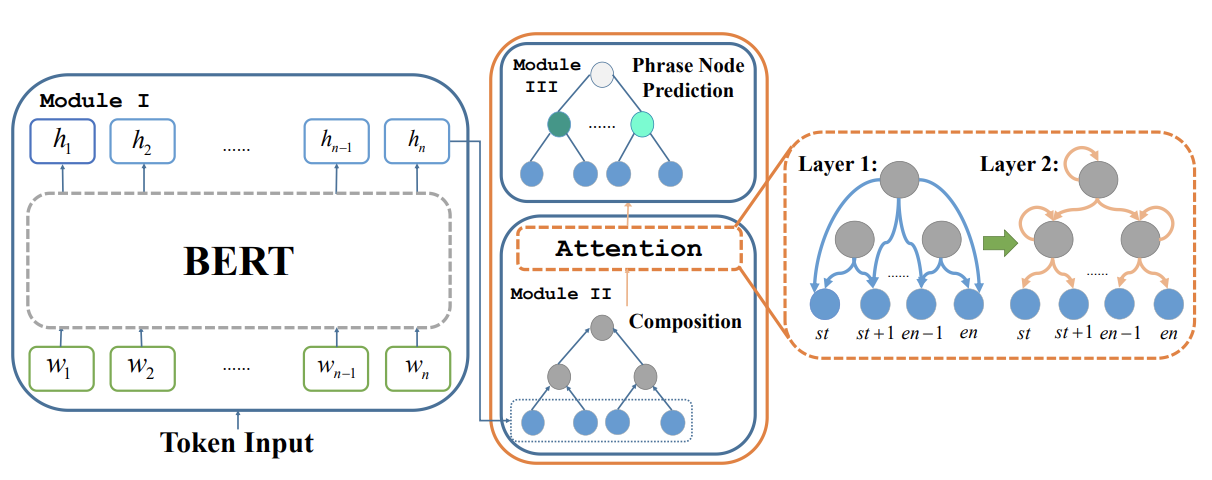
We propose SentiBERT, a variant of BERT that effectively captures compositional sentiment semantics. The model incorporates contextualized representation with binary constituency parse tree to capture semantic composition. Comprehensive experiments demonstrate that SentiBERT achieves competitive performance on phrase-level sentiment classification. We further demonstrate that the sentiment composition learned from the phrase-level annotations on SST can be transferred to other sentiment analysis tasks as well as related tasks, such as emotion classification tasks. Moreover, we conduct ablation studies and design visualization methods to understand SentiBERT. We show that SentiBERT is better than baseline approaches in capturing negation and the contrastive relation and model the compositional sentiment semantics.
Bib Entry
@inproceedings{yin2020sentibert,
author = {Yin, Da and Meng, Tao and Chang, Kai-Wei},
title = {SentiBERT: A Transferable Transformer-Based Architecture for Compositional Sentiment Semantics},
booktitle = {ACL},
year = {2020},
presentation_id = {https://virtual.acl2020.org/paper_main.341.html}
}
Related Publications
- Relation-Guided Pre-Training for Open-Domain Question Answering, EMNLP-Finding, 2021
- An Integer Linear Programming Framework for Mining Constraints from Data, ICML, 2021
- Generating Syntactically Controlled Paraphrases without Using Annotated Parallel Pairs, EACL, 2021
- Clinical Temporal Relation Extraction with Probabilistic Soft Logic Regularization and Global Inference, AAAI, 2021
- GPT-GNN: Generative Pre-Training of Graph Neural Networks, KDD, 2020
- PolicyQA: A Reading Comprehension Dataset for Privacy Policies, EMNLP-Finding (short), 2020
- Building Language Models for Text with Named Entities, ACL, 2018
- Learning from Explicit and Implicit Supervision Jointly For Algebra Word Problems, EMNLP, 2016