Learning to Discriminate Perturbations for Blocking Adversarial Attacks in Text Classification
Yichao Zhou, Jyun-Yu Jiang, Kai-Wei Chang, and Wei Wang, in EMNLP, 2019.
CodeDownload the full text
Abstract
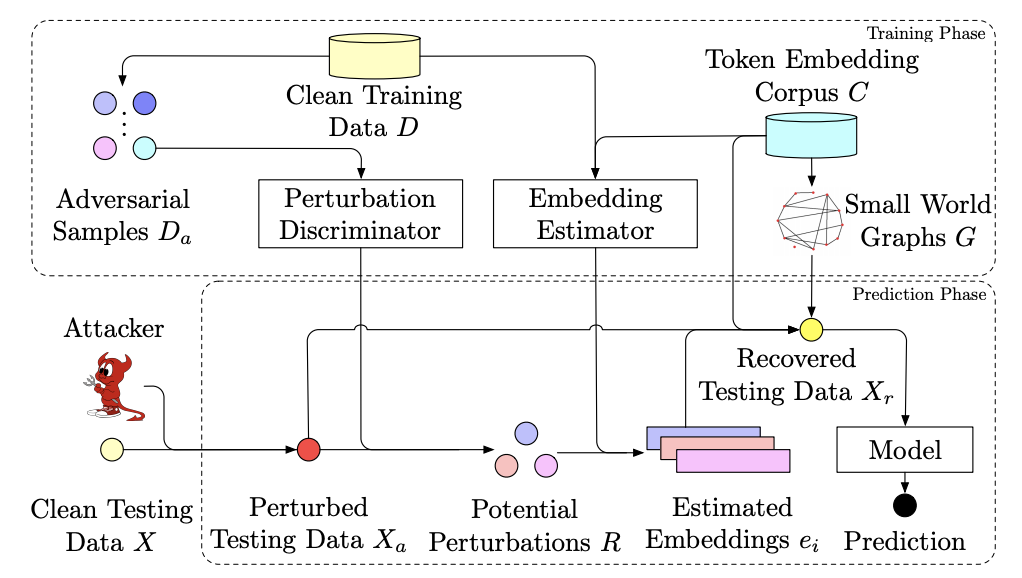
Adversarial attacks against machine learning models have threatened various real-world applications such as spam filtering and sentiment analysis. In this paper, we propose a novel framework, learning to DIScriminate Perturbations (DISP), to identify and adjust malicious perturbations, thereby blocking adversarial attacks for text classification models. To identify adversarial attacks, a perturbation discriminator validates how likely a token in the text is perturbed and provides a set of potential perturbations. For each potential perturbation, an embedding estimator learns to restore the embedding of the original word based on the context and a replacement token is chosen based on approximate kNN search. DISP can block adversarial attacks for any NLP model without modifying the model structure or training procedure. Extensive experiments on two benchmark datasets demonstrate that DISP significantly outperforms baseline methods in blocking adversarial attacks for text classification. In addition, in-depth analysis shows the robustness of DISP across different situations.
Bib Entry
@inproceedings{zhou2019learning,
author = {Zhou, Yichao and Jiang, Jyun-Yu and Chang, Kai-Wei and Wang, Wei},
title = {Learning to Discriminate Perturbations for Blocking Adversarial Attacks in Text Classification},
booktitle = {EMNLP},
year = {2019}
}
Related Publications
- VideoCon: Robust video-language alignment via contrast captions, CVPR, 2024
- CleanCLIP: Mitigating Data Poisoning Attacks in Multimodal Contrastive Learning, ICCV, 2023
- Red Teaming Language Model Detectors with Language Models, TACL, 2023
- ADDMU: Detection of Far-Boundary Adversarial Examples with Data and Model Uncertainty Estimation, EMNLP, 2022
- Investigating Ensemble Methods for Model Robustness Improvement of Text Classifiers, EMNLP-Finding (short), 2022
- Unsupervised Syntactically Controlled Paraphrase Generation with Abstract Meaning Representations, EMNLP-Finding (short), 2022
- Improving the Adversarial Robustness of NLP Models by Information Bottleneck, ACL-Finding, 2022
- Searching for an Effiective Defender: Benchmarking Defense against Adversarial Word Substitution, EMNLP, 2021
- On the Transferability of Adversarial Attacks against Neural Text Classifier, EMNLP, 2021
- Defense against Synonym Substitution-based Adversarial Attacks via Dirichlet Neighborhood Ensemble, ACL, 2021
- Double Perturbation: On the Robustness of Robustness and Counterfactual Bias Evaluation, NAACL, 2021
- Provable, Scalable and Automatic Perturbation Analysis on General Computational Graphs, NeurIPS, 2020
- On the Robustness of Language Encoders against Grammatical Errors, ACL, 2020
- Robustness Verification for Transformers, ICLR, 2020
- Retrofitting Contextualized Word Embeddings with Paraphrases, EMNLP (short), 2019
- Generating Natural Language Adversarial Examples, EMNLP (short), 2018