Disentangling Semantics and Syntax in Sentence Embeddings with Pre-trained Language Models
James Y. Huang, Kuan-Hao Huang, and Kai-Wei Chang, in NAACL (short), 2021.
CodeDownload the full text
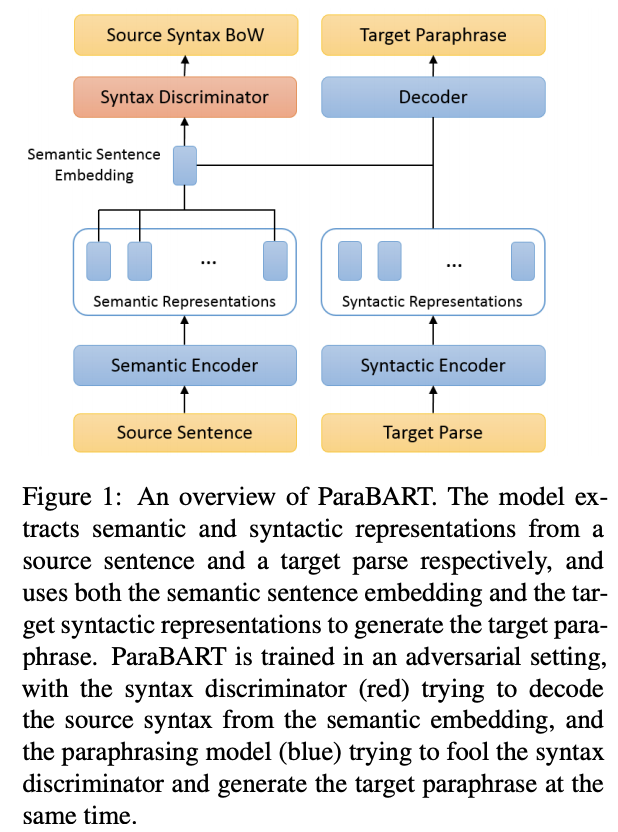
Abstract
Pre-trained language models have achieved huge success on a wide range of NLP tasks. However, contextual representations from pre-trained models contain entangled semantic and syntactic information, and therefore cannot be directly used to derive useful semantic sentence embeddings for some tasks. Paraphrase pairs offer an effective way of learning the distinction between semantics and syntax, as they naturally share semantics and often vary in syntax. In this work, we present ParaBART, a semantic sentence embedding model that learns to disentangle semantics and syntax in sentence embeddings obtained by pre-trained language models. ParaBART is trained to perform syntax-guided paraphrasing, based on a source sentence that shares semantics with the target paraphrase, and a parse tree that specifies the target syntax. In this way, ParaBART learns disentangled semantic and syntactic representations from their respective inputs with separate encoders. Experiments in English show that ParaBART outperforms state-of-the-art sentence embedding models on unsupervised semantic similarity tasks. Additionally, we show that our approach can effectively remove syntactic information from semantic sentence embeddings, leading to better robustness against syntactic variation on downstream semantic tasks.
Check out our #NAACL2021 paper on semantic sentence embeddings! By disentangling the semantics and the syntax of sentences, our ParaBART achieves better performance on semantic textual similarity tasks. (https://t.co/QspSh8W2XJ w/ James Huang and @kaiwei_chang) [1/2] #UCLANLP pic.twitter.com/XzgSmN0353
— Kuan-Hao Huang (@kuanhao_) April 15, 2021
Bib Entry
@inproceedings{huang2021disentangling,
title = {Disentangling Semantics and Syntax in Sentence Embeddings with Pre-trained Language Models},
author = {Huang, James Y. and Huang, Kuan-Hao and Chang, Kai-Wei},
booktitle = {NAACL (short)},
presentation_id = {https://underline.io/events/122/sessions/4151/lecture/19910-disentangling-semantics-and-syntax-in-sentence-embeddings-with-pre-trained-language-models},
year = {2021}
}
Related Publications
No related publications found.