MetaVL: Transferring In-Context Learning Ability From Language Models to Vision-Language Models
Masoud Monajatipoor, Liunian Harold Li, Mozhdeh Rouhsedaghat, Lin Yang, and Kai-Wei Chang, in ACL (short), 2023.
Download the full text
Abstract
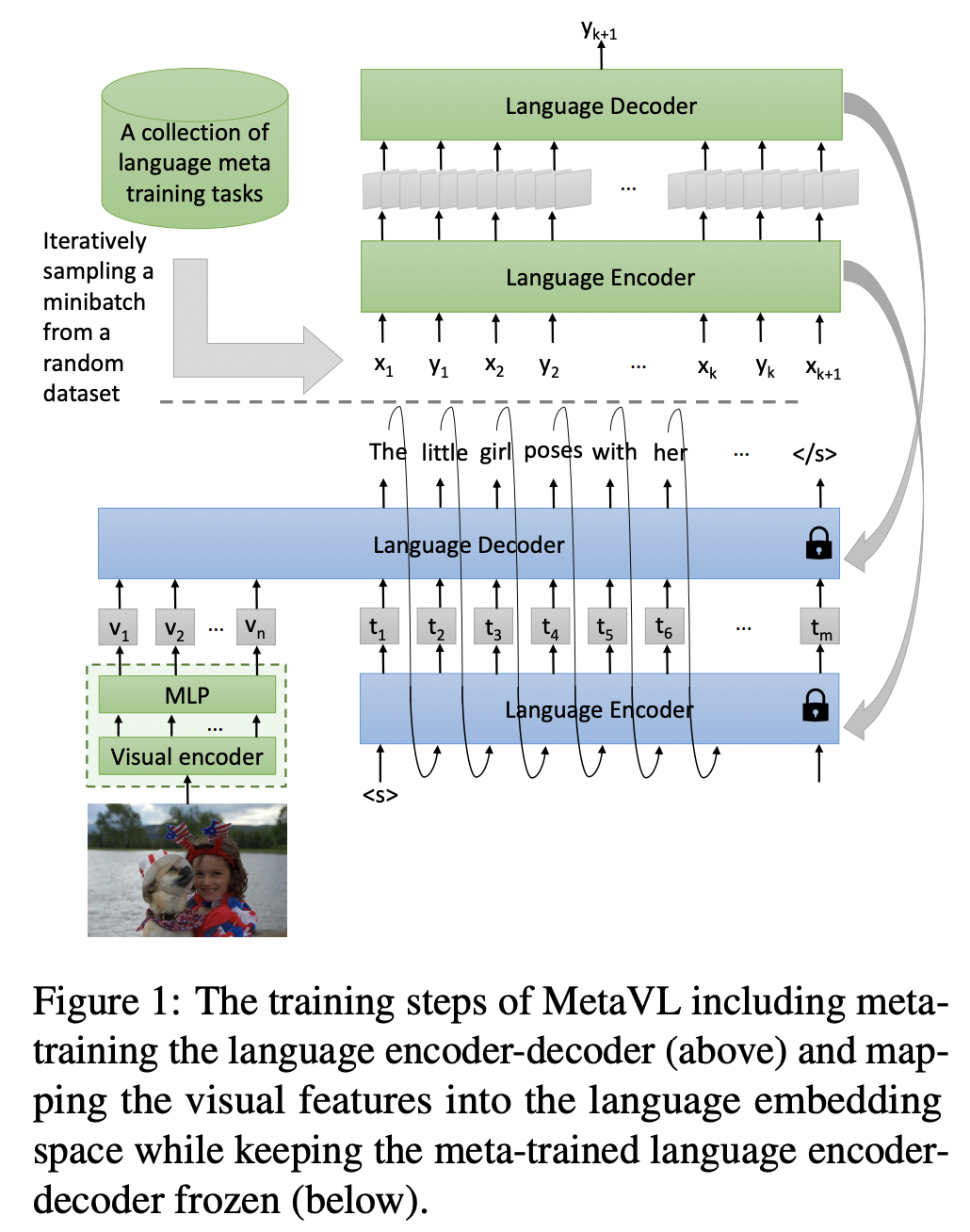
Large-scale language models have shown the ability to adapt to a new task via conditioning on a few demonstrations (i.e., in-context learning). However, in the vision-language domain, most large-scale pre-trained vision-language (VL) models do not possess the ability to conduct in-context learning. How can we enable in-context learning for VL models? In this paper, we study an interesting hypothesis: can we transfer the in-context learning ability from the language domain to VL domain? Specifically, we first meta-trains a language model to perform in-context learning on NLP tasks (as in MetaICL); then we transfer this model to perform VL tasks by attaching a visual encoder. Our experiments suggest that indeed in-context learning ability can be transferred cross modalities: our model considerably improves the in-context learning capability on VL tasks and can even compensate for the size of the model significantly. On VQA, OK-VQA, and GQA, our method could outperform the baseline model while having 20 times fewer parameters.
Bib Entry
@inproceedings{monajatipoor2023metavl,
author = {Monajatipoor, Masoud and Li, Liunian Harold and Rouhsedaghat, Mozhdeh and Yang, Lin and Chang, Kai-Wei},
title = {MetaVL: Transferring In-Context Learning Ability From Language Models to Vision-Language Models},
booktitle = {ACL (short)},
presentation_id = {https://underline.io/events/395/posters/15337/poster/76709-metavl-transferring-in-context-learning-ability-from-language-models-to-vision-language-models},
year = {2023}
}
Related Publications
- VisRet: Visualization Improves Knowledge-Intensive Text-to-Image Retrieval, ACL, 2026
- HoneyBee: Data Recipes for Vision-Language Reasoners, CVPR, 2026
- MotionEdit: Benchmarking and Learning Motion-Centric Image Editing, CVPR, 2026
- LaViDa: A Large Diffusion Language Model for Multimodal Understanding, NeurIPS, 2025
- PARTONOMY: Large Multimodal Models with Part-Level Visual Understanding, NeurIPS, 2025
- SlowFast-VGen: Slow-Fast Learning for Action-Driven Long Video Generation, ICLR, 2025
- Verbalized Representation Learning for Interpretable Few-Shot Generalization, ICCV, 2025
- STIV: Scalable Text and Image Conditioned Video Generation, ICCV, 2025
- Contrastive Visual Data Augmentation, ICML, 2025
- SYNTHIA: Novel Concept Design with Affordance Composition, ACL, 2025
- Towards a holistic framework for multimodal LLM in 3D brain CT radiology report generation, Nature Communications, 2025
- Enhancing Large Vision Language Models with Self-Training on Image Comprehension, NeurIPS, 2024
- CoBIT: A Contrastive Bi-directional Image-Text Generation Model, ICLR, 2024
- DesCo: Learning Object Recognition with Rich Language Descriptions, NeurIPS, 2023
- Text Encoders are Performance Bottlenecks in Contrastive Vision-Language Models, EMNLP, 2023
- "What's 'up' with vision-language models? Investigating their struggle to understand spatial relations.", EMNLP, 2023
- REVEAL: Retrieval-Augmented Visual-Language Pre-Training with Multi-Source Multimodal Knowledge, CVPR, 2023
- Grounded Language-Image Pre-training, CVPR, 2022
- How Much Can CLIP Benefit Vision-and-Language Tasks?, ICLR, 2022