Cross-lingual Dependency Parsing with Unlabeled Auxiliary Languages
Wasi Ahmad, Zhisong Zhang, Xuezhe Ma, Kai-Wei Chang, and Nanyun Peng, in CoNLL, 2019.
Poster CodeDownload the full text
Abstract
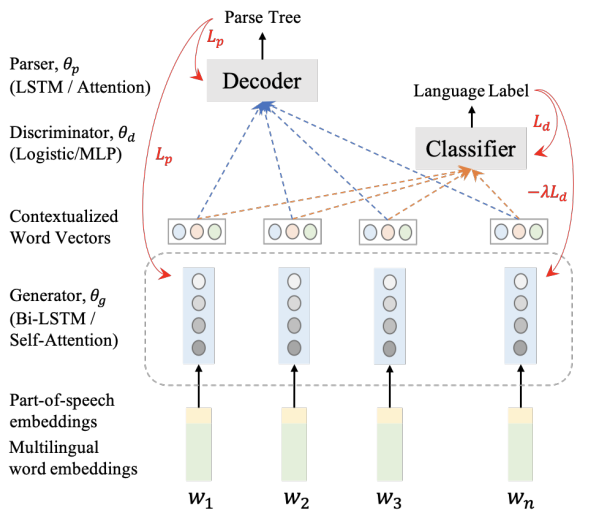
Cross-lingual transfer learning has become an important weapon to battle the unavailability of annotated resources for low-resource languages. One of the fundamental techniques to transfer across languages is learning language-agnostic representations, in the form of word embeddings or contextual encodings. In this work, we propose to leverage unannotated sentences from auxiliary languages to help learning language-agnostic representations Specifically, we explore adversarial training for learning contextual encoders that produce invariant representations across languages to facilitate cross-lingual transfer. We conduct experiments on cross-lingual dependency parsing where we train a dependency parser on a source language and transfer it to a wide range of target languages. Experiments on 28 target languages demonstrate that adversarial training significantly improves the overall transfer performances under several different settings. We conduct a careful analysis to evaluate the language-agnostic representations resulted from adversarial training.
Bib Entry
@inproceedings{ahmad2019crosslingual,
author = {Ahmad, Wasi and Zhang, Zhisong and Ma, Xuezhe and Chang, Kai-Wei and Peng, Nanyun},
title = { Cross-lingual Dependency Parsing with Unlabeled Auxiliary Languages},
booktitle = {CoNLL},
year = {2019}
}
Related Publications
- LiveCLKTBench: Towards Reliable Evaluation of Cross-Lingual Knowledge Transfer in Multilingual LLMs, ACL, 2026
- Contextual Label Projection for Cross-Lingual Structured Prediction, NAACL, 2024
- Multilingual Generative Language Models for Zero-Shot Cross-Lingual Event Argument Extraction, ACL, 2022
- Improving Zero-Shot Cross-Lingual Transfer Learning via Robust Training, EMNLP, 2021
- Syntax-augmented Multilingual BERT for Cross-lingual Transfer, ACL, 2021
- Evaluating the Values of Sources in Transfer Learning, NAACL, 2021
- GATE: Graph Attention Transformer Encoder for Cross-lingual Relation and Event Extraction, AAAI, 2021
- Cross-Lingual Dependency Parsing by POS-Guided Word Reordering, EMNLP-Finding, 2020
- Target Language-Aware Constrained Inference for Cross-lingual Dependency Parsing, EMNLP, 2019
- On Difficulties of Cross-Lingual Transfer with Order Differences: A Case Study on Dependency Parsing, NAACL, 2019