Counterexamples for Robotic Planning Explained in Structured Language
Lu Feng, Mahsa Ghasemi, Kai-Wei Chang, and Ufuk Topcu, in ICRA, 2018.
Download the full text
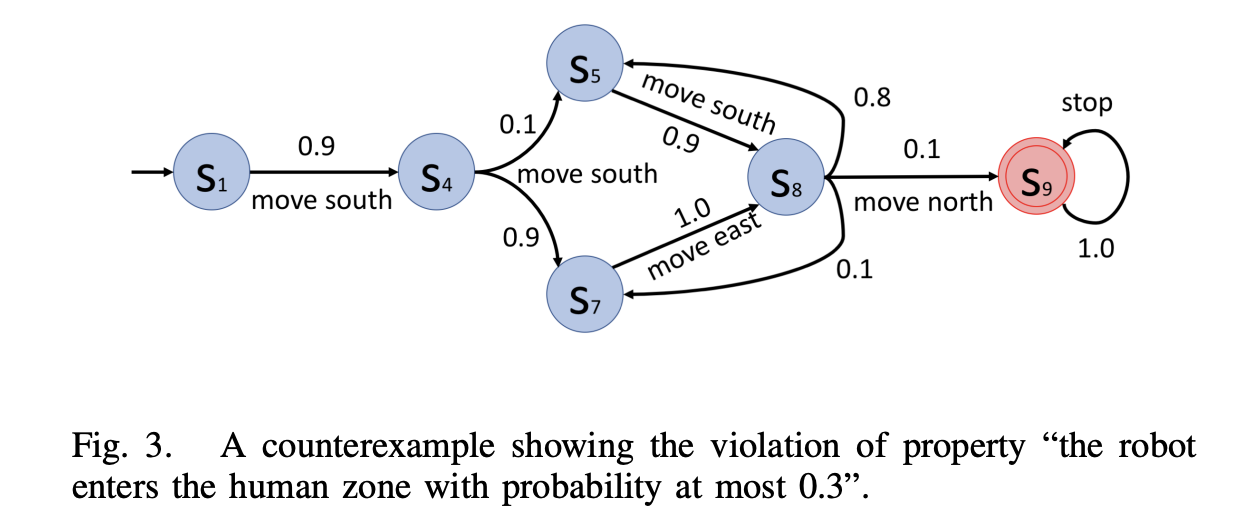
Abstract
Automated techniques such as model checking have been used to verify models of robotic mission plans based on Markov decision processes (MDPs) and generate counterexamples that may help diagnose requirement violations. However, such artifacts may be too complex for humans to understand, because existing representations of counterexamples typically include a large number of paths or a complex automaton. To help improve the interpretability of counterexamples, we define a notion of explainable counterexample, which includes a set of structured natural language sentences to describe the robotic behavior that lead to a requirement violation in an MDP model of robotic mission plan. We propose an approach based on mixed-integer linear programming for generating explainable counterexamples that are minimal, sound and complete. We demonstrate the usefulness of the proposed approach via a case study of warehouse robots planning.
Bib Entry
@inproceedings{feng2018conterexamples,
author = {Feng, Lu and Ghasemi, Mahsa and Chang, Kai-Wei and Topcu, Ufuk},
title = {Counterexamples for Robotic Planning Explained in Structured Language},
booktitle = {ICRA},
year = {2018}
}
Related Publications
- A Transformer-based Approach for Source Code Summarization, ACL (short), 2020
- Context Attentive Document Ranking and Query Suggestion, SIGIR, 2019
- Multifaceted Protein-Protein Interaction Prediction Based on Siamese Residual RCNN, ISMB, 2019
- Multi-Task Learning for Document Ranking and Query Suggestion, ICLR, 2018
- Intent-aware Query Obfuscation for Privacy Protection in Personalized Web Search, SIGIR, 2018
- Word and sentence embedding tools to measure semantic similarity of Gene Ontology terms by their definitions, Journal of Computational Biology, 2018