General Introduction
We propose a patch-based object tracking algorithm which provides both good enough robustness and computational efficiency.
Our algorithm learns and maintains Composite Patch-based Templates (CPT) of the tracking target. The CPT model is initially established by maximizing the discriminability of the composite templates given the first frame, and automatically updated on-line by adding new effective composite patches and deleting old invalid ones. The inference of the target location is achieved by matching each composite template across frames. By this means the proposed algorithm can effectively track targets with partial occlusions or significant appearance variations.
Experimental results demonstrate that the proposed algorithm outperforms both Mutilple Instance Learning [3] and Ensemble Tracking algorithms [4].
Representation
As illustrated in Fig.1, the CPT model is constructed by first extracting and selecting image patches from the tracking window, by maximizing the difference with the background.
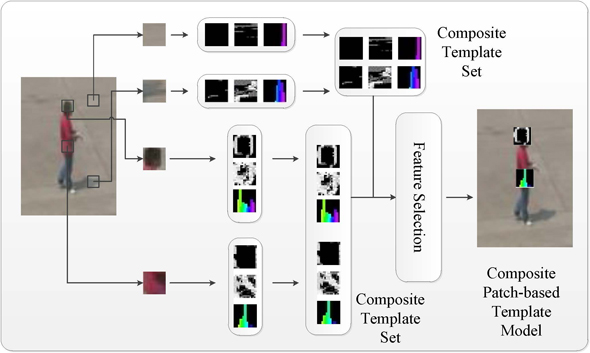
For each image patch, three types of features, LOG, CS-LBP, and RGB histogam, are applied to capture the local statistics of edge, texture and flatness.
Tracking Algorithm
Target Location Inference
When a new frame appears, we employ KL distance to measure the similarity between two composite patches and traverse peripheral regions around every composite patch in CPT to find the matching patch. The target location in the new frame is computed as the weighted sum of offsets of all matched patches.
Online Model Maintenance
The on-line maintenance mechanism is divided into two steps: firstly, we construct a candidate set from the new frame; secondly, we select composite patches from both and the matching patch set by maximizing the discriminability of CPT model.
Experiments
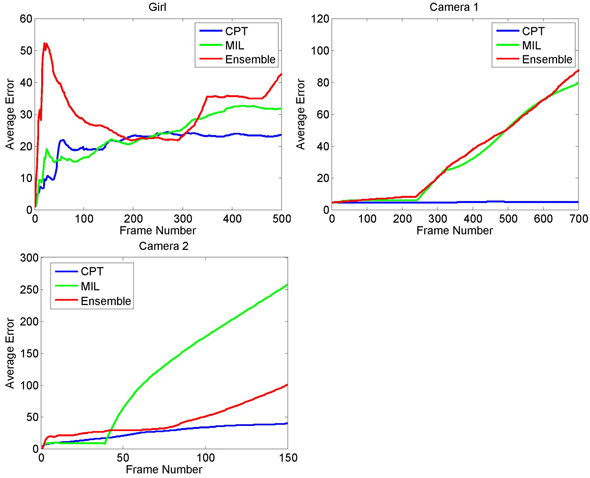
We collect 3 test videos to verify our approach, one video of the human face from Multiple Instance Learning (MIL) and two surveillance videos from the internet. We compare the proposed method (CPT) with two state-of-the-art algorithms: MIL and Ensemble Tracking (Ensemble). A number of sampled tracking results are shown in Fig.2. Severe body variations and large-scale occlusions take place in above datasets.

To quantitatively evaluate the performance of our method, we compute the average tracking error with manually labeled groundtruth of the tracking target location, as shown in Fig.3.
Reference
- [1] Realtime Object-of-Interest Tracking by Learning Composite Patch-Based Templates. Y. Xu, H. Zhou, Q. Wang, L. Lin. In Proc. International Conference on Image Processing (ICIP), 2012. [pdf]
- [2] Adaptive Object Tracking by Learning Hybrid Template Online. X. Liu, L. Lin, S. Yan, H. Jin, and W. Jiang. IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 21(11), 1588–1599, 2011.
- [3] Visual Tracking with Online Multiple Instance Learning. B. Babenko, M. Yang and S. Belongie. In Proc. of IEEE International Conference on Computer Vision and Pattern Recogntion (CVPR), 2009.
- [4] Ensemble tracking. S. Avidan. In Proc. of IEEE International Conference on Computer Vision and Pattern Recogntion (CVPR), 2005.