Unsupervised Vision-and-Language Pre-training Without Parallel Images and Captions
Liunian Harold Li, Haoxuan You, Zhecan Wang, Alireza Zareian, Shih-Fu Chang, and Kai-Wei Chang, in NAACL, 2021.
Download the full text
Abstract
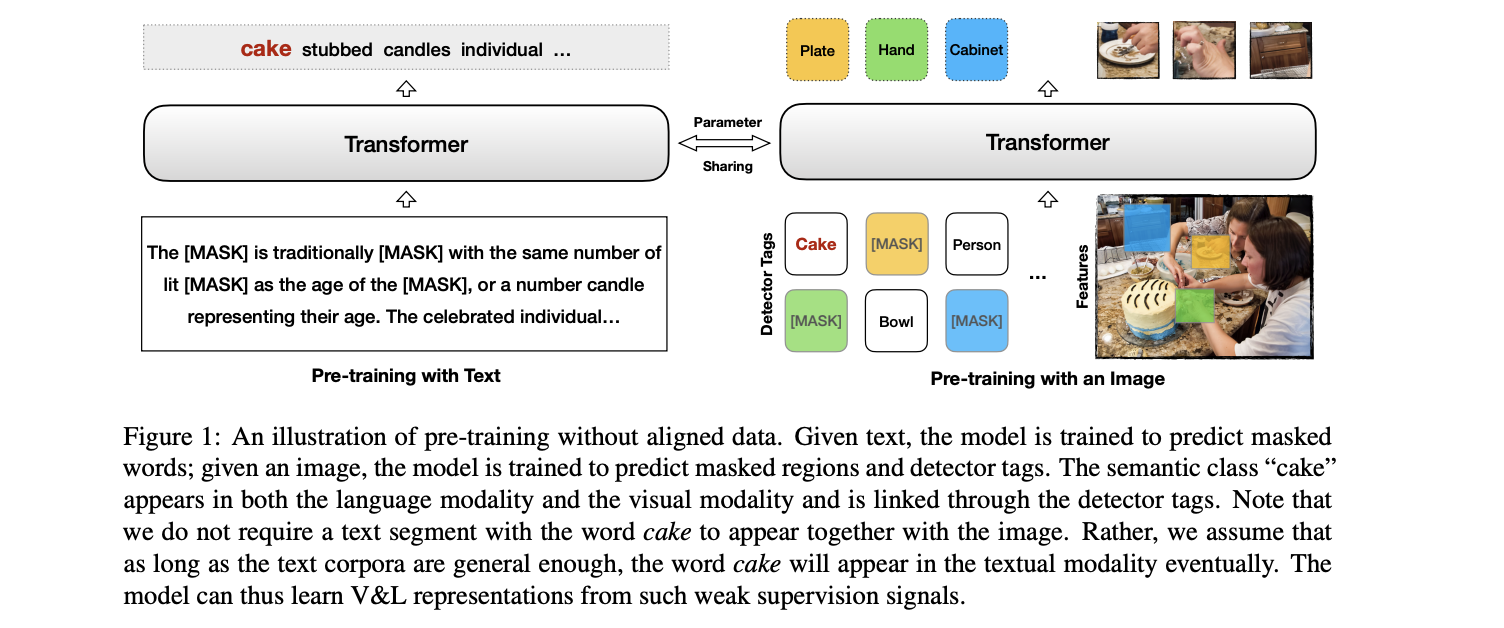
Pre-trained contextual vision-and-language (V&L) models have brought impressive performance improvement on various benchmarks. However, the paired text-image data required for pre-training are hard to collect and scale up. We investigate if a strong V&L representation model can be learned without text-image pairs. We propose Weakly-supervised VisualBERT with the key idea of conducting "mask-and-predict" pre-training on language-only and image-only corpora. Additionally, we introduce the object tags detected by an object recognition model as anchor points to bridge two modalities. Evaluation on four V&L benchmarks shows that Weakly-supervised VisualBERT achieves similar performance with a model pre-trained with paired data. Besides, pre-training on more image-only data further improves a model that already has access to aligned data, suggesting the possibility of utilizing billions of raw images available to enhance V&L models.
Excited to share our NAACL paper Unsupervised Vision-and-Language Pre-training Without Parallel Images and Captions! https://t.co/R248NcGH3b
— Liunian Harold Li (@LiLiunian) April 16, 2021
We show that one could pre-train a V&L model on unaligned images and text with competitive performance as models trained on aligned data. pic.twitter.com/7TrKAMxL6a
Bib Entry
@inproceedings{li2021unsupervised,
author = {Li, Liunian Harold and You, Haoxuan and Wang, Zhecan and Zareian, Alireza and Chang, Shih-Fu and Chang, Kai-Wei},
title = {Unsupervised Vision-and-Language Pre-training Without Parallel Images and Captions},
booktitle = {NAACL},
presentation_id = {https://underline.io/events/122/sessions/4269/lecture/19725-unsupervised-vision-and-language-pre-training-without-parallel-images-and-captions},
year = {2021}
}
Related Publications
- Broaden the Vision: Geo-Diverse Visual Commonsense Reasoning, EMNLP, 2021
- What Does BERT with Vision Look At?, ACL (short), 2020
- VisualBERT: A Simple and Performant Baseline for Vision and Language, Arxiv, 2019