Evaluating the Values of Sources in Transfer Learning
Md Rizwan Parvez and Kai-Wei Chang, in NAACL, 2021.
CodeDownload the full text
Abstract
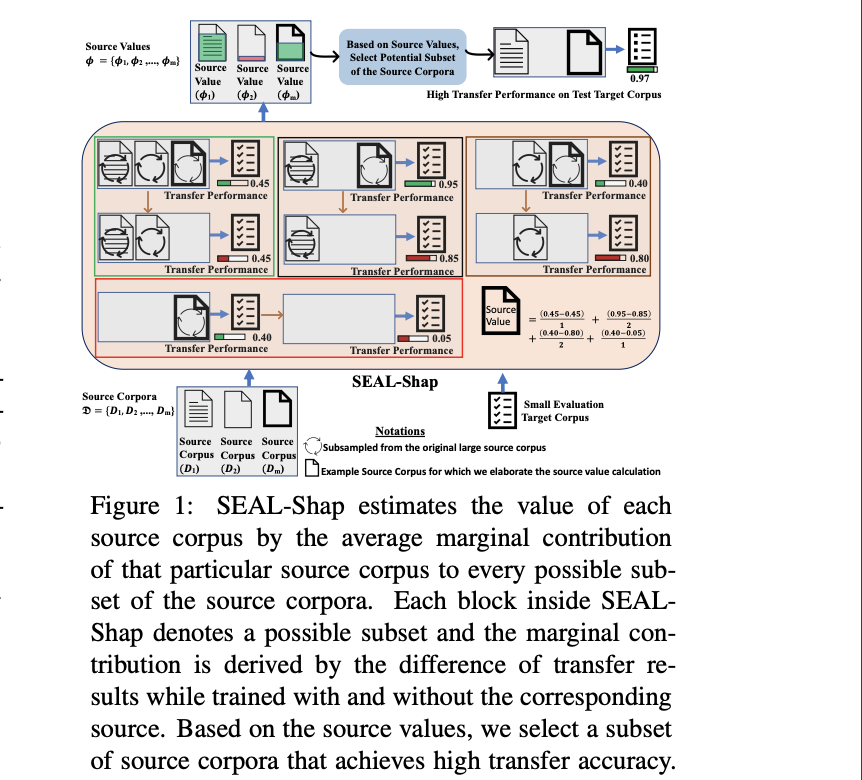
Transfer learning that adapts a model trained on data-rich sources to low-resource targets has been widely applied in natural language processing (NLP). However, when training a transfer model over multiple sources, not every source is equally useful for the target. To better transfer a model, it is essential to understand the values of the sources. In this paper, we develop SEAL-Shap, an efficient source valuation framework for quantifying the usefulness of the sources (e.g., domains/languages) in transfer learning based on the Shapley value method. Experiments and comprehensive analyses on both cross-domain and cross-lingual transfers demonstrate that our framework is not only effective in choosing useful transfer sources but also the source values match the intuitive source-target similarity.
When performing transfer learning with multiple sources, one key question is how much info one can leverage from each source. In #NAACL2021 paper, Rizwan Parvez @uclanlp developed SEAL-SHAP, an efficient source valuation framework for quantifying the usefulness of the sources 1/n pic.twitter.com/5qmAG7a1q7
— Kai-Wei Chang (@kaiwei_chang) June 5, 2021
Bib Entry
@inproceedings{parvez2021evaluating,
title = {Evaluating the Values of Sources in Transfer Learning},
author = {Parvez, Md Rizwan and Chang, Kai-Wei},
booktitle = {NAACL},
presentation_id = {https://underline.io/events/122/sessions/4261/lecture/19707-evaluating-the-values-of-sources-in-transfer-learning},
year = {2021}
}
Related Publications
- LiveCLKTBench: Towards Reliable Evaluation of Cross-Lingual Knowledge Transfer in Multilingual LLMs, ACL, 2026
- Contextual Label Projection for Cross-Lingual Structured Prediction, NAACL, 2024
- Multilingual Generative Language Models for Zero-Shot Cross-Lingual Event Argument Extraction, ACL, 2022
- Improving Zero-Shot Cross-Lingual Transfer Learning via Robust Training, EMNLP, 2021
- Syntax-augmented Multilingual BERT for Cross-lingual Transfer, ACL, 2021
- GATE: Graph Attention Transformer Encoder for Cross-lingual Relation and Event Extraction, AAAI, 2021
- Cross-Lingual Dependency Parsing by POS-Guided Word Reordering, EMNLP-Finding, 2020
- Cross-lingual Dependency Parsing with Unlabeled Auxiliary Languages, CoNLL, 2019
- Target Language-Aware Constrained Inference for Cross-lingual Dependency Parsing, EMNLP, 2019
- On Difficulties of Cross-Lingual Transfer with Order Differences: A Case Study on Dependency Parsing, NAACL, 2019