Learning Word Embeddings for Low-resource Languages by PU Learning
Chao Jiang, Hsiang-Fu Yu, Cho-Jui Hsieh, and Kai-Wei Chang, in NAACL, 2018.
Slides CodeDownload the full text
Abstract
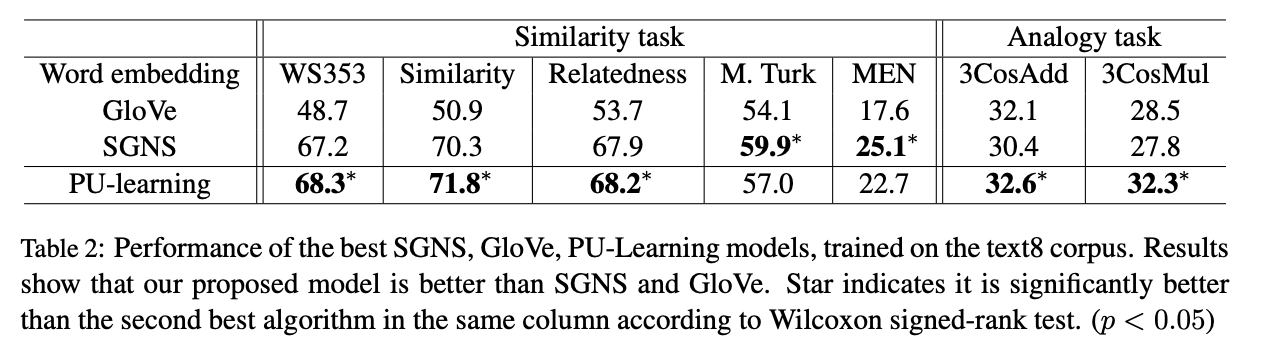
Word embedding has been used as a key component in many downstream applications in processing natural languages. Existing approaches often assume the existence of a large collection of text for learning effective word embedding. However, such a corpus may not be available for some low-resource languages. In this paper, we study how to effectively learn a word embedding model on a corpus with only a few million tokens. In such a situation, the co-occurrence matrix is very sparse because many word pairs are not observed to co-occur. In contrast to existing approaches, we argue that the zero entries in the co-occurrence matrix also provide valuable information and design a Positive-Unlabeled Learning (PU-Learning) approach to factorize the co-occurrence matrix. The experimental results demonstrate that the proposed approach requires a smaller amount of training text to obtain a reasonable word embedding model.
Bib Entry
@inproceedings{jiang2018learning,
author = {Jiang, Chao and Yu, Hsiang-Fu and Hsieh, Cho-Jui and Chang, Kai-Wei},
title = {Learning Word Embeddings for Low-resource Languages by PU Learning},
booktitle = {NAACL},
vimeo_id = {277670013},
year = {2018}
}
Related Publications
- Control Large Language Models via Divide and Conquer, EMNLP, 2024
- Re-ReST: Reflection-Reinforced Self-Training for Language Agents, EMNLP, 2024
- Agent Lumos: Unified and Modular Training for Open-Source Language Agents, ACL, 2024
- Characterizing Truthfulness in Large Language Model Generations with Local Intrinsic Dimension, ICML, 2024
- TrustLLM: Trustworthiness in Large Language Models, ICML, 2024
- The steerability of large language models toward data-driven personas, NAACL, 2024
- AI-Assisted Summarization of Radiologic Reports: Evaluating GPT3davinci, BARTcnn, LongT5booksum, LEDbooksum, LEDlegal, and LEDclinical, American Journal of Neuroradiology, 2024
- Understanding and Mitigating Spurious Correlations in Text Classification with Neighborhood Analysis, EACL-Findings, 2024
- Few-Shot Representation Learning for Out-Of-Vocabulary Words, ACL, 2019
- Co-training Embeddings of Knowledge Graphs and Entity Descriptions for Cross-lingual Entity Alignment, IJCAI, 2018
- Beyond Bilingual: Multi-sense Word Embeddings using Multilingual Context, ACL RepL4NLP Workshop, 2017