Gender Bias in Contextualized Word Embeddings
Jieyu Zhao, Tianlu Wang, Mark Yatskar, Ryan Cotterell, Vicente Ordonez, and Kai-Wei Chang, in NAACL (short), 2019.
SlidesDownload the full text
Abstract
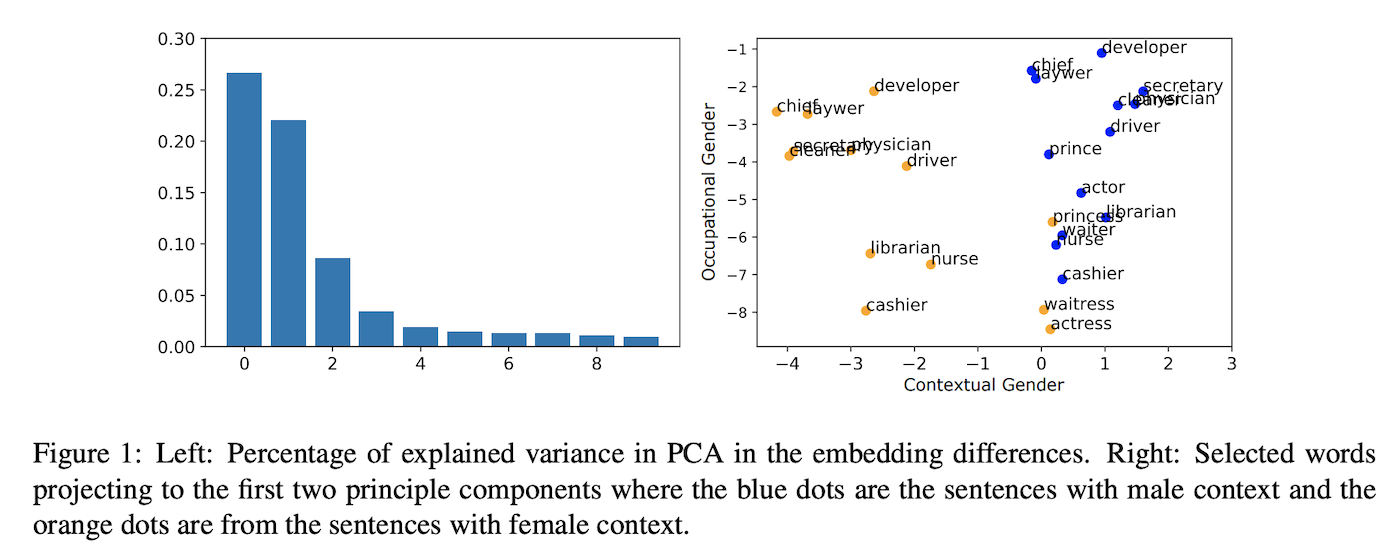
Despite the great success of contextualized word embeddings on downstream applications, these representations potentially embed the societal biases exhibited in their training corpus. In this paper, we quantify, analyze and mitigate the gender bias exhibited in ELMo contextualized word vectors. We first demonstrate that the vectors encode and propagate information about genders unequally and then conduct a principal component analysis to visualize the geometry of the gender information in the embeddings. Then we show that ELMo works unequally well for men and women in down-stream tasks. Finally, we explore a variety of methods to remove such gender bias and demonstrate that it can be reduced through data augmentation.
Bib Entry
@inproceedings{zhao2019gender,
author = {Zhao, Jieyu and Wang, Tianlu and Yatskar, Mark and Cotterell, Ryan and Ordonez, Vicente and Chang, Kai-Wei},
title = {Gender Bias in Contextualized Word Embeddings},
booktitle = {NAACL (short)},
year = {2019}
}
Related Publications
- Mitigating Gender Bias in Distilled Language Models via Counterfactual Role Reversal, ACL Finding, 2022
- Harms of Gender Exclusivity and Challenges in Non-Binary Representation in Language Technologies, EMNLP, 2021
- Gender Bias in Multilingual Embeddings and Cross-Lingual Transfer, ACL, 2020
- Examining Gender Bias in Languages with Grammatical Gender, EMNLP, 2019
- Balanced Datasets Are Not Enough: Estimating and Mitigating Gender Bias in Deep Image Representations, ICCV, 2019
- Learning Gender-Neutral Word Embeddings, EMNLP (short), 2018
- Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings, NeurIPS, 2016