My research interests include probabilistic methods in machine learning and deep generative models. My goal is to design generative models that not only capture the uncertainty and structures of real-world data, but also support efficient and reliable probabilistic reasoning.
The best way to reach me is via email at mhdang at stanford dot edu.
Large language models (LLMs) are fine-tuned using human comparison data with Reinforcement Learning from Human Feedback (RLHF) methods to make them better aligned with users’ preferences. In contrast to LLMs, human preference learning has not been widely explored in text-to-image diffusion models; the best existing approach is to fine-tune a pretrained model using carefully curated high quality images and captions to improve visual appeal and text alignment. We propose Diffusion-DPO, a method to align diffusion models to human preferences by directly optimizing on human comparison data. Diffusion-DPO is adapted from the recently developed Direct Preference Optimization (DPO), a simpler alternative to RLHF which directly optimizes a policy that best satisfies human preferences under a classification objective. We re-formulate DPO to account for a diffusion model notion of likelihood, utilizing the evidence lower bound to derive a differentiable objective. Using the Pick-a-Pic dataset of 851K crowdsourced pairwise preferences, we fine-tune the base model of the state-of-the-art Stable Diffusion XL (SDXL)-1.0 model with Diffusion-DPO. Our fine-tuned base model significantly outperforms both base SDXL-1.0 and the larger SDXL-1.0 model consisting of an additional refinement model in human evaluation, improving visual appeal and prompt alignment. We also develop a variant that uses AI feedback and has comparable performance to training on human preferences, opening the door for scaling of diffusion model alignment methods.
@article{Wallace23,author={Wallace, Bram and Dang, Meihua and Rafailov, Rafael and Zhou, Linqi and Lou, Aaron and Purushwalkam, Senthil and Ermon, Stefano and Xiong, Caiming and Joty, Shafiq and Naik, Nikhil},title={Diffusion Model Alignment Using Direct Preference Optimization},year={2023},journal={arXiv preprint},}
Tractable Control for Auto-regressive Language Generation
Honghua Zhang*, Meihua Dang*, Nanyun Peng, and Guy Van den Broeck
In Proceedings of the 40th International Conference on Machine Learning (ICML), 2023
Oral full presentation, acceptance rate 155/6538 = 2.4%
Despite the success of large language models (LMs) in language generation, it remains a major challenge to generate texts following some complex lexical constraints: the conditional distribution Pr(text | α) is intractable for even the simplest lexical constraints α. In this paper, we propose to incorporate tractable probabilistic models (TPMs) to impose lexical constraints in auto-regressive language generation. Using hidden Markov model as a demonstrating example, our method achieves state-of-the-art performance on CommonGen, a challenging benchmark for constrained text generation, beating a wide range of strong baselines by a large margin. Our work opens up new avenues for not only constrained language generation but also motivates the development of more expressive TPMs.
@inproceedings{ZhangICML2023,author={Zhang*, Honghua and Dang*, Meihua and Peng, Nanyun and {Van den Broeck}, Guy},title={Tractable Control for Auto-regressive Language Generation},year={2023},booktitle={Proceedings of the 40th International Conference on Machine Learning (ICML)},}
Scaling Pareto-Efficient Decision Making via Offline Multi-Objective RL
Baiting Zhu, Meihua Dang, and Aditya Grover
In International Conference on Learning Representations, 2023
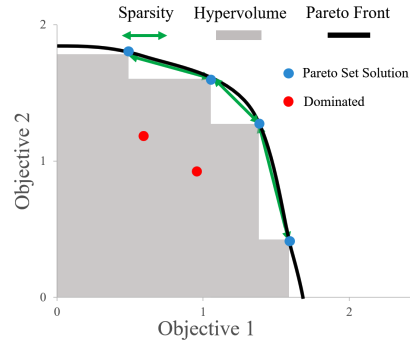
The goal of multi-objective reinforcement learning (MORL) is to learn policies that simultaneously optimize multiple competing objectives. In practice, an agent’s preferences over the objectives may not be known apriori, and hence, we require policies that can generalize to arbitrary preferences at test time. In this work, we propose a new data-driven setup for offline MORL, where we wish to learn a preference-agnostic policy agent using only a finite dataset of offline demonstrations of other agents and their preferences. The key contributions of this work are two-fold. First, we introduce D4MORL, (D)atasets for MORL that are specifically designed for offline settings. It contains 1.8 million annotated demonstrations obtained by rolling out reference policies that optimize for randomly sampled preferences on 6 MuJoCo environments with 2-3 objectives each. Second, we propose Pareto-Efficient Decision Agents (PEDA), a family of offline MORL algorithms that builds and extends Decision Transformers via a novel preference-and-return-conditioned policy. Empirically, we show that PEDA closely approximates the behavioral policy on the D4MORL benchmark and provides an excellent approximation of the Pareto-front with appropriate conditioning, as measured by the hypervolume and sparsity metrics.
@inproceedings{ZhuICML2023,title={Scaling Pareto-Efficient Decision Making via Offline Multi-Objective RL},author={Zhu, Baiting and Dang, Meihua and Grover, Aditya},booktitle={International Conference on Learning Representations},year={2023},}
Sparse Probabilistic Circuits via Pruning and Growing
Meihua Dang, Anji Liu, and Guy Van den Broeck
In Advances in Neural Information Processing Systems 35 (NeurIPS), Dec 2022
Oral full presentation, acceptance rate 201/10411 = 1.9%
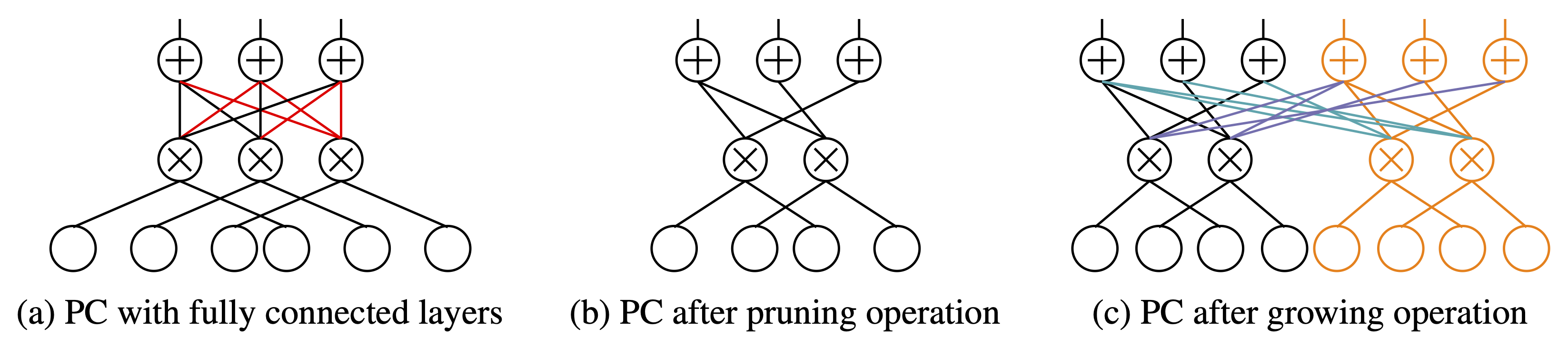
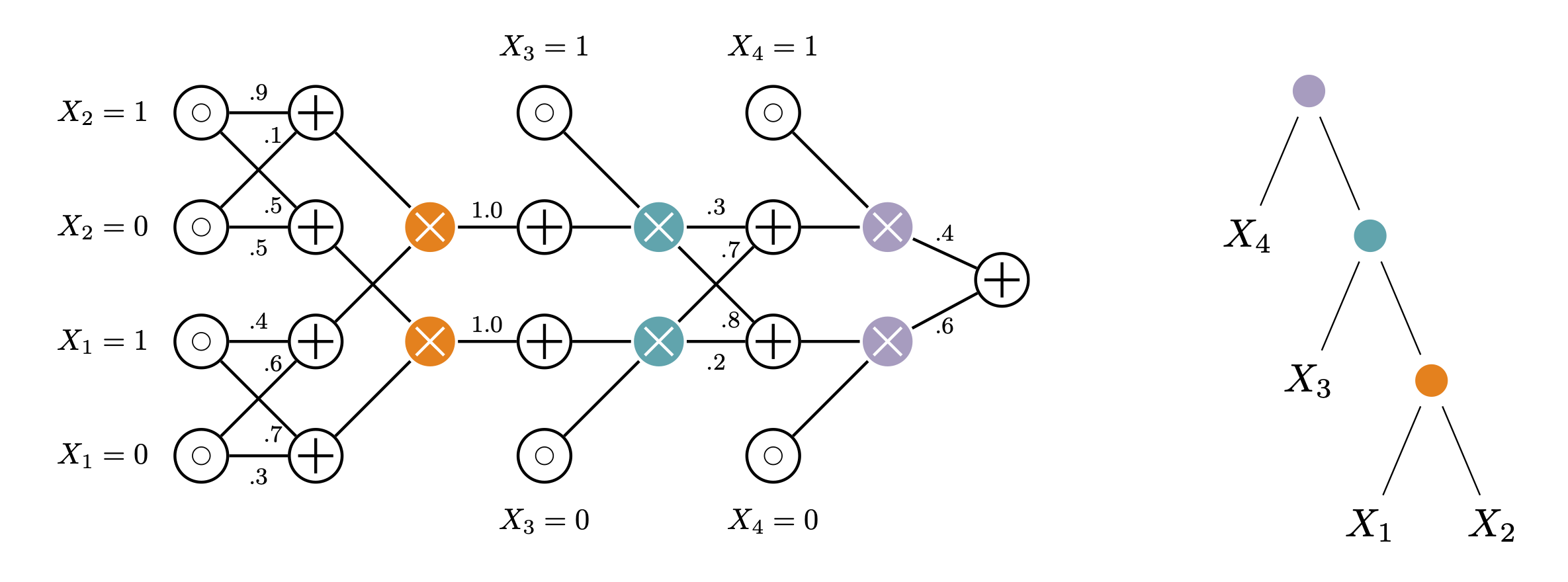
Probabilistic circuits (PCs) are a tractable representation of probability distributions allowing for exact and efficient computation of likelihoods and marginals. There has been significant recent progress on improving the scale and expressiveness of PCs. However, PC training performance plateaus as model size increases. We discover that most capacity in existing large PC structures is wasted: fully-connected parameter layers are only sparsely used. We propose two operations: pruning and growing, that exploit the sparsity of PC structures. Specifically, the pruning operation removes unimportant sub-networks of the PC for model compression and comes with theoretical guarantees. The growing operation increases model capacity by increasing the size of the latent space. By alternatingly applying pruning and growing, we increase the capacity that is meaningfully used, allowing us to significantly scale up PC learning. Empirically, our learner achieves state-of-the-art likelihoods on MNIST-family image datasets and on Penn Tree Bank language data compared to other PC learners and less tractable deep generative models such as flow-based models and variational autoencoder (VAEs).
@inproceedings{DangNeurIPS22,author={Dang, Meihua and Liu, Anji and {Van den Broeck}, Guy},title={Sparse Probabilistic Circuits via Pruning and Growing},booktitle={Advances in Neural Information Processing Systems 35 (NeurIPS)},month=dec,year={2022},}
Tractable and Expressive Generative Models of Genetic Variation Data
Meihua Dang, Anji Liu, Xinzhu Wei, Sriram Sankararaman*, and Guy Van den Broeck*
In Proceedings of the International Conference on Research in Computational Molecular Biology (RECOMB), May 2022
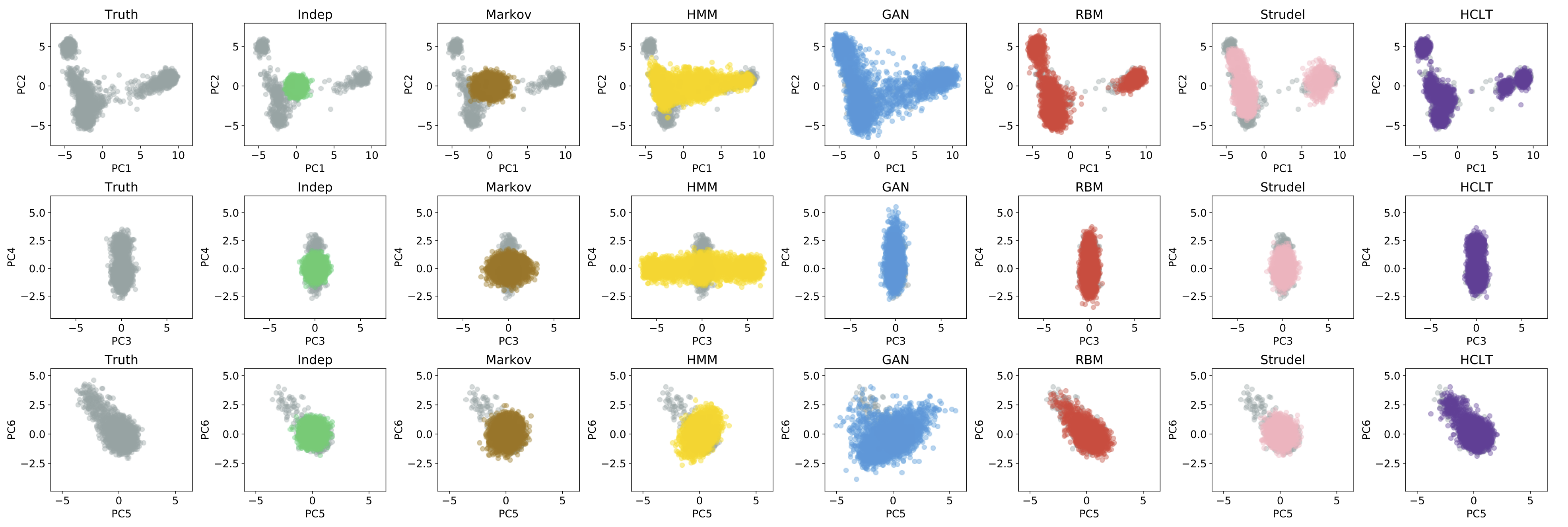
Population genetic studies often rely on artificial genomes (AGs) simulated by generative models of genetic data. In recent years, unsupervised learning models, based on hidden Markov models, deep generative adversarial networks, restricted Boltzmann machines, and variational autoencoders, have gained popularity due to their ability to generate AGs closely resembling empirical data. These models, however, present a tradeoff between expressivity and tractability. Here, we propose to use hidden Chow-Liu trees (HCLTs) and their representation as probabilistic circuits (PCs) as a solution to this tradeoff. We first learn an HCLT structure that captures the long-range dependencies among SNPs in the training data set. We then convert the HCLT to its equivalent PC as a means of supporting tractable and efficient probabilistic inference. The parameters in these PCs are inferred with an expectation-maximization algorithm using the training data. Compared to other models for generating AGs, HCLT obtains the largest log-likelihood on test genomes across SNPs chosen across the genome and from a contiguous genomic region. Moreover, the AGs generated by HCLT more accurately resemble the source data set in their patterns of allele frequencies, linkage disequilibrium, pairwise haplotype distances, and population structure. This work not only presents a new and robust AG simulator but also manifests the potential of PCs in population genetics.
@inproceedings{DangRECOMB22,title={Tractable and Expressive Generative Models of Genetic Variation Data},author={Dang, Meihua and Liu, Anji and Wei, Xinzhu and Sankararaman*, Sriram and {Van den Broeck*}, Guy},booktitle={Proceedings of the International Conference on Research in Computational Molecular Biology (RECOMB)},month=may,year={2022},doi={https://doi.org/10.1007/978-3-031-04749-7_26},}
Strudel: A Fast and Accurate Learner of Structured-Decomposable Probabilistic Circuits
Meihua Dang, Antonio Vergari, and Guy Van den Broeck
International Journal of Approximate Reasoning, Jan 2022
Probabilistic circuits (PCs) represent a probability distribution as a computational graph. Enforcing structural properties on these graphs guarantees that several inference scenarios become tractable. Among these properties, structured
decomposability is a particularly appealing one: it enables the efficient and exact computations of the probability of
complex logical formulas, and can be used to reason about the expected output of certain predictive models under missing data. This paper proposes Strudel, a simple, fast and accurate learning algorithm for structured-decomposable
PCs. Compared to prior work for learning structured-decomposable PCs, Strudel delivers more accurate single PC
models in fewer iterations, and dramatically scales learning when building ensembles of PCs. It achieves this scalability by exploiting another structural property of PCs, called determinism, and by sharing the same computational graph
across mixture components. We show these advantages on standard density estimation benchmarks and challenging
inference scenarios.
@article{DangIJAR22,author={Dang, Meihua and Vergari, Antonio and {Van den Broeck}, Guy},title={Strudel: A Fast and Accurate Learner of Structured-Decomposable Probabilistic Circuits},journal={International Journal of Approximate Reasoning},month=jan,year={2022},volume={140},pages={92-115},issn={0888-613X},doi={https://doi.org/10.1016/j.ijar.2021.09.012},}
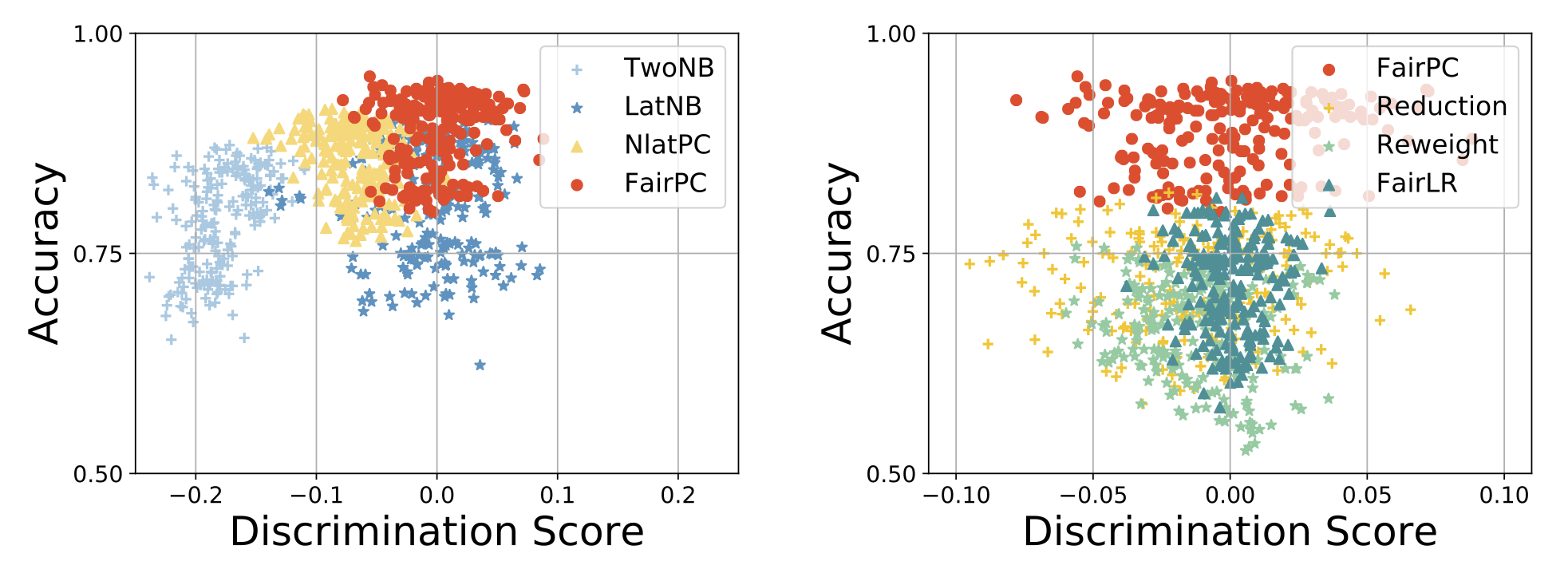
Group Fairness by Probabilistic Modeling with Latent Fair Decisions
YooJung Choi, Meihua Dang, and Guy Van den Broeck
In Proceedings of the 35th AAAI Conference on Artificial Intelligence, Feb 2021
Machine learning systems are increasingly being used to make
impactful decisions such as loan applications and criminal justice risk assessments, and as such, ensuring fairness of these
systems is critical. This is often challenging as the labels in
the data are biased. This paper studies learning fair probability distributions from biased data by explicitly modeling
a latent variable that represents a hidden, unbiased label. In
particular, we aim to achieve demographic parity by enforcing
certain independencies in the learned model. We also show
that group fairness guarantees are meaningful only if the distribution used to provide those guarantees indeed captures the
real-world data. In order to closely model the data distribution,
we employ probabilistic circuits, an expressive and tractable
probabilistic model, and propose an algorithm to learn them
from incomplete data. We evaluate our approach on a synthetic dataset in which observed labels indeed come from fair
labels but with added bias, and demonstrate that the fair labels
are successfully retrieved. Moreover, we show on real-world
datasets that our approach not only is a better model than existing methods of how the data was generated but also achieves
competitive accuracy.
@inproceedings{ChoiAAAI21,author={Choi, YooJung and Dang, Meihua and {Van den Broeck}, Guy},title={Group Fairness by Probabilistic Modeling with Latent Fair Decisions},booktitle={Proceedings of the 35th AAAI Conference on Artificial Intelligence},month=feb,year={2021},}
Juice: A Julia Package for Logic and Probabilistic Circuits
Meihua Dang, Pasha Khosravi, Yitao Liang, Antonio Vergari, and Guy Van den Broeck
In Proceedings of the 35th AAAI Conference on Artificial Intelligence (Demo Track), Feb 2021
JUICE is an open-source Julia package providing tools for
logic and probabilistic reasoning and learning based on logic
circuits (LCs) and probabilistic circuits (PCs). It provides a
range of efficient algorithms for probabilistic inference queries,
such as computing marginal probabilities (MAR), as well as
many more advanced queries. Certain structural circuit properties are needed to achieve this tractability, which JUICE helps
validate. Additionally, it supports several parameter and structure learning algorithms proposed in the recent literature. By
leveraging parallelism (on both CPU and GPU), JUICE provides a fast implementation of circuit-based algorithms, which
makes it suitable for tackling large-scale datasets and models.
@inproceedings{DangAAAI21,title={Juice: A Julia Package for Logic and Probabilistic Circuits},author={Dang, Meihua and Khosravi, Pasha and Liang, Yitao and Vergari, Antonio and {Van den Broeck}, Guy},booktitle={Proceedings of the 35th AAAI Conference on Artificial Intelligence (Demo Track)},month=feb,year={2021},}
Probabilistic circuits (PCs) represent a probability distribution as a computational graph. Enforcing
structural properties on these graphs guarantees that several inference scenarios become tractable.
Among these properties, structured decomposability is a particularly appealing one: it enables the
efficient and exact computations of the probability of complex logical formulas, and can be used
to reason about the expected output of certain predictive models under missing data. This paper
proposes Strudel, a simple, fast and accurate learning algorithm for structured-decomposable PCs.
Compared to prior work for learning structured-decomposable PCs, Strudel delivers more accurate
single PC models in fewer iterations, and dramatically scales learning when building ensembles of
PCs. It achieves this scalability by exploiting another structural property of PCs, called determinism,
and by sharing the same computational graph across mixture components. We show these advantages
on standard density estimation benchmarks and challenging inference scenarios.
@inproceedings{DangPGM20,author={Dang, Meihua and Vergari, Antonio and {Van den Broeck}, Guy},title={Strudel: Learning Structured-Decomposable Probabilistic Circuits},booktitle={Proceedings of the 10th International Conference on Probabilistic Graphical Models (PGM)},month=sep,year={2020},video={https://www.youtube.com/watch?v=lOF22mPT_NU},}