| Home |
Research | Publications |
Award |
Teaching | Student | CV | Software | Funding | Service |
Leadership |
Talks |
GitHub |
Please
visit my group's GitHub page
to see a up-to-date list of software tools and research data. ![]()
 |
Apache Spark has
become a key platform for Big Data Analytics, yet it lacks
support for interactive debugging. As a result, debugging
Spark programs can be a painstakingly long process. To
address this challenge, we designed BigDebug with a set of
interactive, real-time debugging primitives for Apache
Spark. This requires rethinking the notion of step-through
debugging in a traditional debugger such as gdb, because
pausing the entire computation across distributed worker
nodes causes significant delay and naively inspecting
millions of records using a watchpoint is too time consuming
for an end user. BIGDEBUG provides simulated breakpoints and on-demand watchpoints to allow users to selectively examine distributed, intermediate data on the cloud. A user can also pinpoint a crash-inducing record and selectively resume relevant sub-computations after a quick fix. A user can determine the root causes of errors (or delays) at the level of individual records through fine-grained data provenance. BIGDEBUG scales to terabytes. Its record-level tracing inurs less than 25% overhead on average. It determines crash culprits orders of magnitude more accurately and provides up to 100% time saving compared to the baseline replay debugger. BigDebug's project website is available at here. |
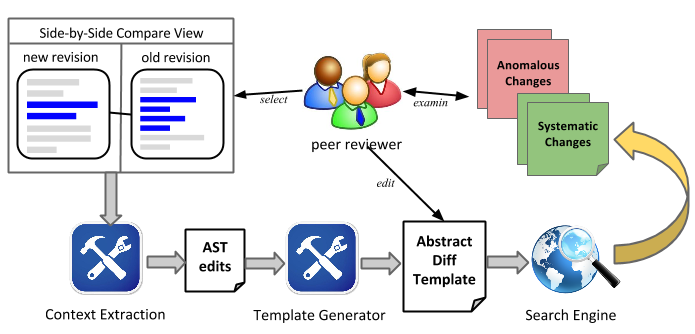 |
During peer code reviews,
developers often examine program differences. When using
existing program differencing tools, it is difficult for
developers to inspect systematic changes?similar, related
changes that are scattered across multiple files. Developers
cannot easily answer questions such as "what other code
locations changed similar to this change?" and "are there
any other locations that are similar to this code but are
not updated?" Critics assists developers in inspecting
systematic changes. It (1) allows developers to customize a
context-aware change template, (2) searches for systematic
changes using the template, and (3) detects missing or
inconsistent edits. Developers can interactively refine the
customized change template to see corresponding search
results. Critics Eclipse plug-in is developed by Tianyi Zhang and Myoungkyu Song. Please check out the demonstration video of Critics here. |
 |
Manual refactoring edits are error
prone, as refactoring requires developers to
coordinate related transformations and understand the
complex inter-relationship between affected files,
variables, and methods. We propose RefDistiller, an
approach for improving detection of manual refactoring
anomalies by two combined strategies. First, it uses a
predefined template to identify potential missed
refactoring edits---omission anomalies. Second, it
leverages an automated refactoring engine to separate
behavior-preserving edits from behavior-modifying
edits---commission anomalies. We evaluate its
effectiveness on a data set with one hundred manual
refactoring bugs. These bugs are hard to detect
because they do not produce any compilation errors nor
are caught by the pre- and post-condition checking of
many existing refactoring engines. RefDistiller is
able to identify 97% of the erroneous edits, of which
24% are not detected by the given test suites.
RefDistiller Eclipse plug-in is developed and maintained by Everton Leandro. Its evaluation data set is available and tool is available here. Please check out the demonstration video of RefDistiller here. |
 |
Adding features and fixing
bugs in software often require systematic edits
which are similar, but not identical, changes to many code
locations. Finding all relevant locations and making the
correct edits is a tedious and error-prone process. We
demonstrate an Eclipse plug-in called LASE that (1) creates
context-aware edit scripts from two or more examples,
and uses these scripts to (2) automatically identify edit
locations and to (3) transform the code. In LASE,
users can view individual syntactic edit operations and
corresponding control and data flow context for each input
example. They can also choose a different subset of the
examples to adjust the abstraction level of inferred edit.
When LASE locates target methods matching the inferred edit
context and suggests customized edits, users can review and
correct LASE's edit suggestion. These features can
reduce developers' burden in repetitively applying similar
edits to different contexts. Lase Eclipse plug-in is developed and maintained by John Jacobellis and Na Meng. Please contact myself, John, and Na for questions and comments. You can watch a tool demonstration video of LASE at: https://www.youtube.com/watch?v=npDqMVP2e9Q Please also see our 10 page technical report on LASE and our 4 page tool demo paper under submission. |
| Existing code completion
engines leverage only pre-defined templates or match a set
of user-defined APIs to complete the rest of changes. We
propose a new code completion technique, called Cookbook,
where developers can define custom edit recipes?a reusable
template of complex edit operations?by specifying change
examples. It generates an abstract edit recipe that
describes the most specific generalization of the
demonstrated example program transformations. Given a
library of edit recipes, it matches a developer?s edit
stream to recommend a suitable recipe that is capable of
filling out the rest of change customized to the target. Our
demo video is available here. Cookbook is developed by John Jacobellis. |
 |
Repertoire detects repetitive
and similar edits among a group of program patches and it is
based on CCFinderX.
Thus it can identify ported code from the program
patches. Repertoire can be used to evaluate repetitive
work in similar products and our research group has used
Repertoire to analyze the extent and characteristic of
cross-system porting in forked projects. You can
download Repertoire from here
and access the analysis data that we have made available in
public. Repertoire is developed and maintained by Baishakhi Ray. Please contact myself and Baishakhi Ray for questions and comments. Repertoire has its own tool web site and the analysis data on 18 years of the BSD product family is available as well. |
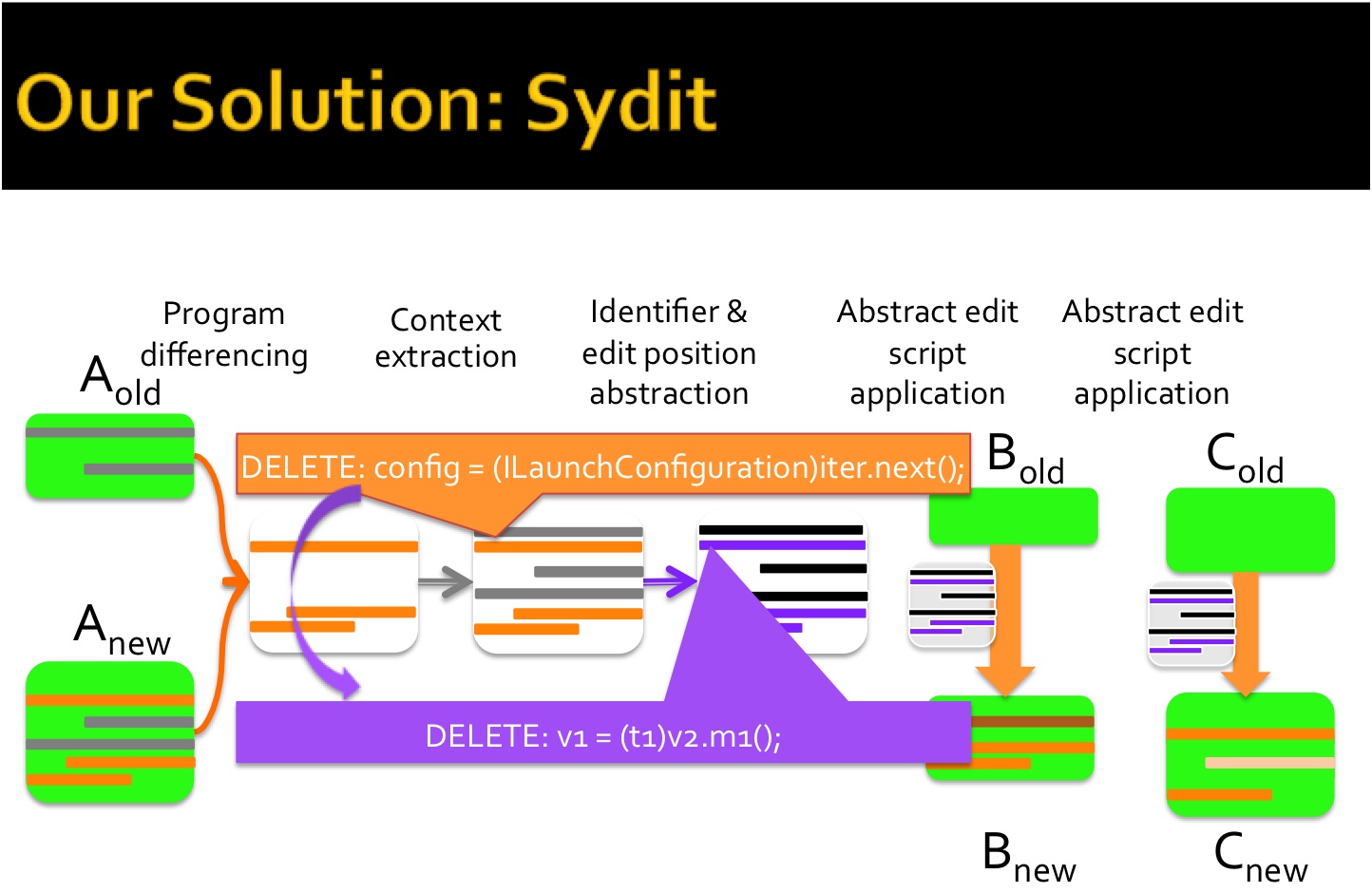 |
Bug fixes and feature
additions to large code bases often require systematic
edits---similar, but not identical, coordinated changes to
multiple places. This process is tedious and
error-prone. SYDIT supports a systematic editing approach by
creating generalized edit scripts from exemplar edits and
applying them to user-selected targets. A programmer
provides an example edit to SYDIT that consists of an old
and new version of a changed method. Based on this one
example, SYDIT generates a context-aware, abstract edit
script. To make transformations applicable to similar but
not identical methods, SYDIT encodes control, data,
and containment dependences and abstracts position, type,
method, and variable names. Then the programmer selects
target methods and SYDIT customizes the edit script to each
target and displays the results for the programmer to review
and approve. SYDIT is available as an Eclipse plug-in and this tool is developed and maintained by Na Meng. Please contact myself and Na Meng for accessing the plug-in and for questions and comments. Please read our SYDIT research paper (PLDI 2011) and a tool demo paper (FSE 2011). |
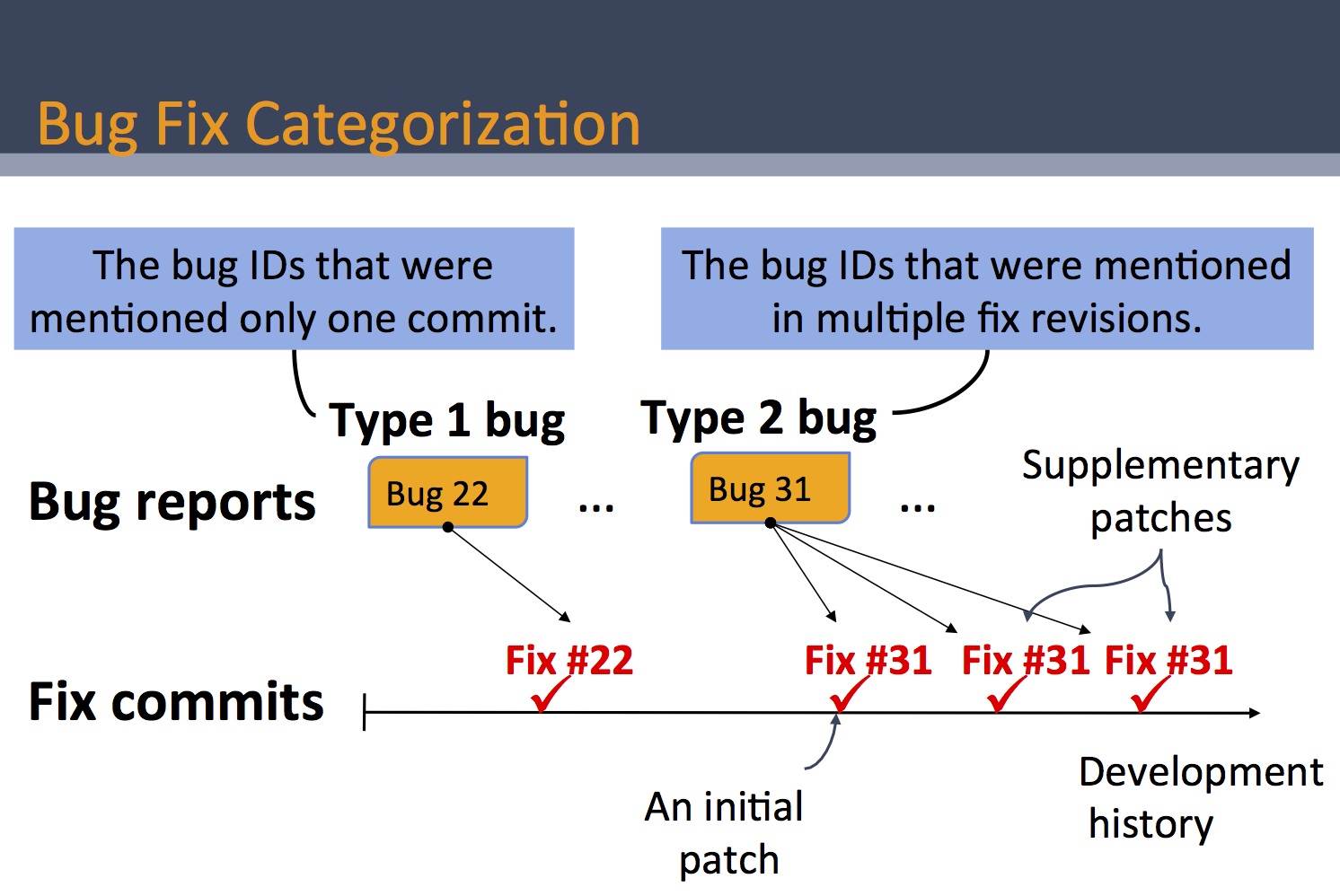 |
A recent study finds that
errors of omission are harder for programmers to detect than
errors of commission. While several change recommendation
systems already exist to prevent or reduce omission errors
during software development, there have been very few
studies on why errors of omission occur in practice and how
such errors could be prevented. In order to understand the
characteristics of omission errors, we investigate a group
of bugs that were fixed more than once in open source
projects?those bugs whose initial patches were later
considered incomplete and to which programmers applied
supplementary patches. Please read our supplementary bug fix
study paper (MSR
2012). Our data
on Eclipse JDT core, Eclipse SWT, and Mozilla are
available to public and are maintained by Jihun Park.
This data has been used by researchers at UIUC and Waterloo
on a study of performance bug fixes. |
 |
RefFinder identifies
complex refactorings between two program versions using a
template-based refactoring reconstruction
approach---RefFinder expresses each refactoring type in
terms of template logic rules and uses a logic programming
engine to infer concrete refactoring instances. It currently
supports sixty three refactoring types from Fowler's
catalog, showing the most comprehensive coverage among
existing techniques. The evaluation using code examples from
Fowler's catalog and open source project histories (jEdit,
Columba and carol) shows that RefFinder identifies
refactorings with an overall precision of 0.79 and recall of
0.95. RefFinder Eclipse plug-in is available for download. Please contact myself and Napol Rachatasumrit for questions and comments. Please read our RefFinder research paper (ICSM 2010) and a tool demo paper (FSE 2010). RefFinder results are stored in an XML format and the following zip file includes our manual inspection results on three subject programs: JMeter, Ant, and XMLSecurity. These results are used to investigate the impact of Refactoring on Regression Testing. This data set is available in public: inspected_dataset.zip |
 |
During code review tasks, comparing two versions of a hardware design description using existing program differencing tools such as diff is inherently limited because existing program differencing tools implicitly assume sequential execution semantics, while hardware description languages are designed to model concurrent computation. We designed a position-independent differencing algorithm to robustly handle language constructs whose relative orderings do not matter. This paper presents Vdiff, an instantiation of this position-independent differencing algorithm for Verilog HDL. To help programmers reason about the differences at a high-level, Vdiff outputs syntactic differences in terms of Verilog-specific change types. We evaluated Vdiff on two open source hardware design projects. The evaluation result shows that Vdiff is very accurate, with overall 96.8% precision and 97.3% recall when using manually classified differences as a basis of comparison. |
 |
Software engineers often inspect program differences when reviewing others? code changes, when writing check-in comments, or when determining why a program behaves differently from expected behavior. Program differencing tools that support these tasks are limited in their ability to group related code changes or to detect potential inconsistency in program changes. To overcome these limitations and to complement existing approaches, we built Logical Structural Diff (LSDiff) that infers systematic structural differences as logic rules, noting anomalies from systematic changes as exceptions to the logic rules. We conducted a focus group study with professional software engineers in a large E-commerce company and also compared LSDiff?s results with plain structural differences without rules and textual differences. Our evaluation suggests that LSDiff complements existing differencing tools by grouping code changes that form systematic change patterns regardless of their distribution throughout the code and that its ability to discover anomalies shows promise in detecting inconsistent changes. |