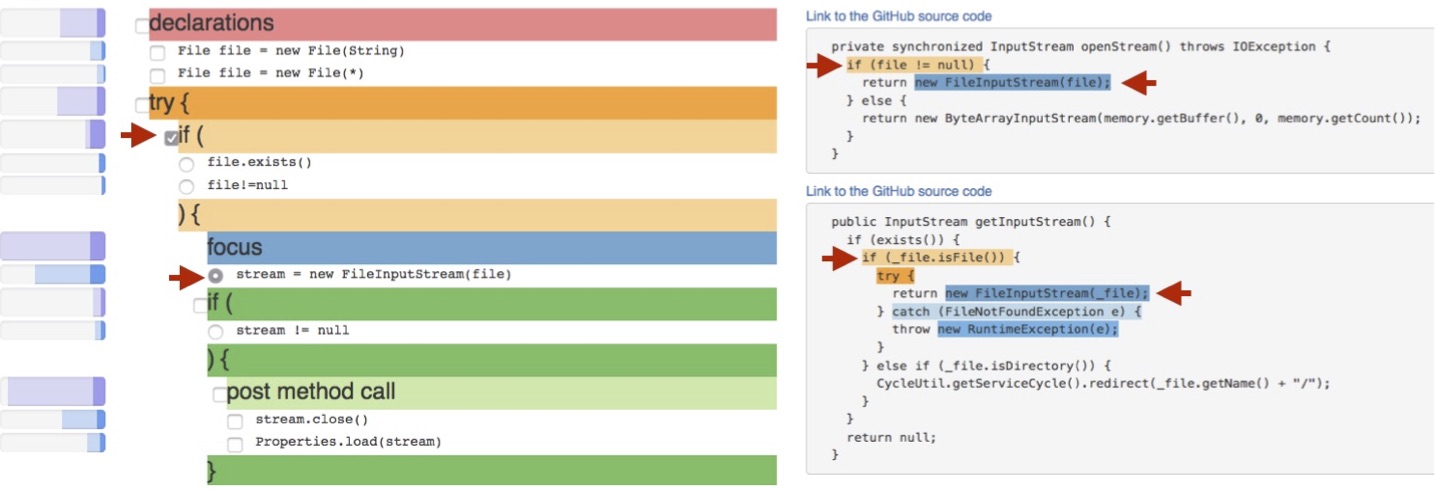
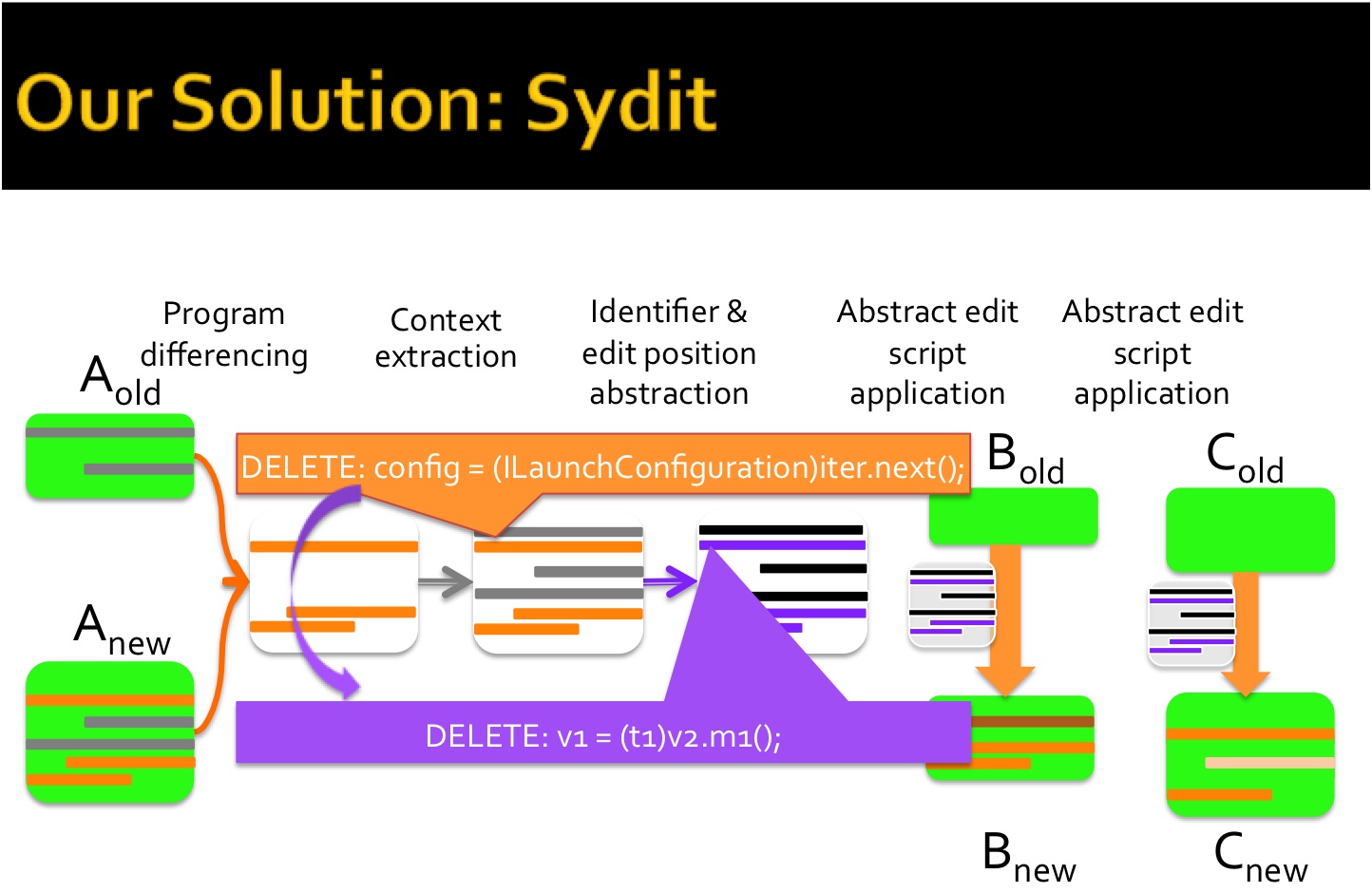
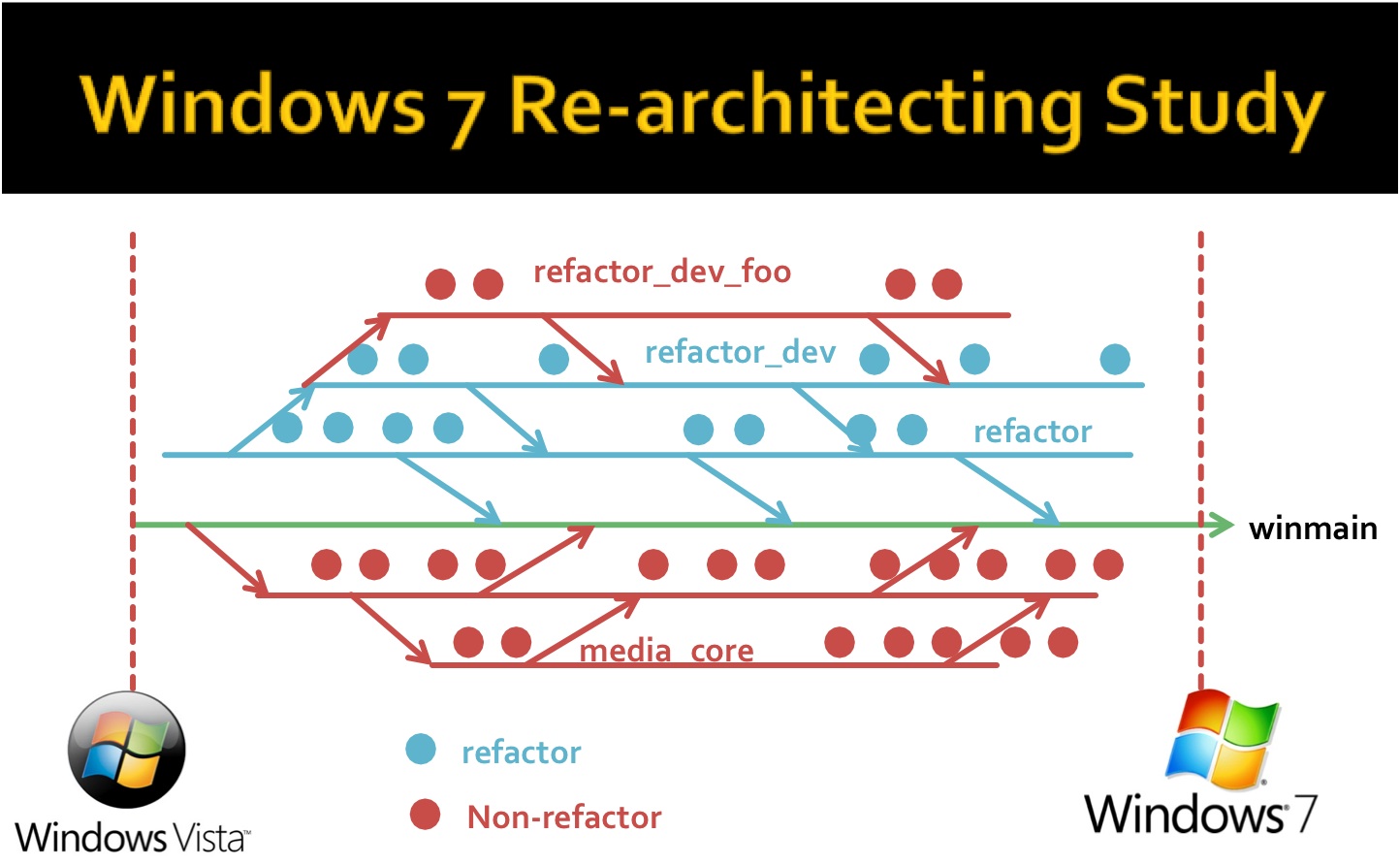
Studies on Data Scientists
Recognizing data-driven industry transformation as early as 2014, we led research into emerging roles of data scientists in the software teams and identified 9 distinct clusters of data scientists. Our studies on data scientists provided the insights on how data-focused roles were reshaping software engineering, informing the establishment of a "data scientist" career path at Microsoft. This job category was soon adopted across the technology industry, catalyzing a parallel transformation in higher education and expanding Data Science and Artificial Intelligence (AI) majors.