At UCLA-NLP, our mission is to develop fair, accountable, robust natural language processing technology to benefit everyone. We will present papers at EMNLP 2020 on the following topics.
Link to our papers in the virtual conference
Fairness in Natural Language Processing
Natural Language Processing (NLP) models are widely used in our daily lives. Despite these methods achieve high performance in various applications, they run the risk of exploiting and reinforcing the societal biases (e.g. gender bias) that are present in the underlying data. At EMNLP, we present our studies on 1) how to detect bias in a local region of instances, 2) how to control bias in language generation.
LOGAN: Local Group Bias Detection by Clustering
Jieyu Zhao and Kai-Wei Chang, in EMNLP (short), 2020.
QA Sessions: Gather-1I: Nov 17, 02:00-04:00 UTC / 18:00-20:00 PST -1d Paper link in the virtual conferenceFull Text Code BibTeX DetailsDetails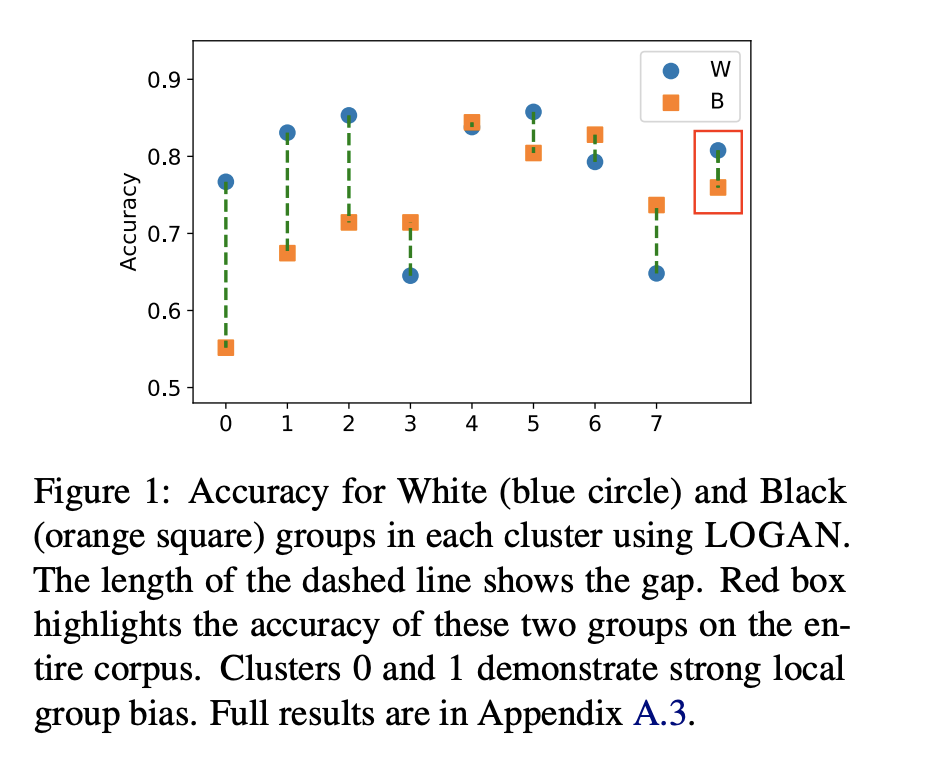
Machine learning techniques have been widely used in natural language processing (NLP). However, as revealed by many recent studies, machine learning models often inherit and amplify the societal biases in data. Various metrics have been proposed to quantify biases in model predictions. In particular, several of them evaluate disparity in model performance between protected groups and advantaged groups in the test corpus. However, we argue that evaluating bias at the corpus level is not enough for understanding how biases are embedded in a model. In fact, a model with similar aggregated performance between different groups on the entire data may behave differently on instances in a local region. To analyze and detect such local bias, we propose LOGAN, a new bias detection technique based on clustering. Experiments on toxicity classification and object classification tasks show that LOGAN identifies bias in a local region and allows us to better analyze the biases in model predictions.
@inproceedings{zhao2020logan, author = {Zhao, Jieyu and Chang, Kai-Wei}, title = {LOGAN: Local Group Bias Detection by Clustering}, booktitle = {EMNLP (short)}, presentation_id = {https://virtual.2020.emnlp.org/paper_main.2886.html}, year = {2020} }1/2 Existing studies on measuring bias often consider performance gap between cohorts over the entire test set. But, does it show the whole story? In our #EMNLP20 paper “LOGAN: Local Group Bias Detection by Clustering” (https://t.co/wnpL4Ern8l), joint work with @kaiwei_chang,
— Jieyu Zhao (@jieyuzhao11) November 16, 2020Related Publications
-
Measuring Fairness of Text Classifiers via Prediction Sensitivity
Satyapriya Krishna, Rahul Gupta, Apurv Verma, Jwala Dhamala, Yada Pruksachatkun, and Kai-Wei Chang, in ACL, 2022.
Full Text Abstract BibTeX DetailsDetailsWith the rapid growth in language processing applications, fairness has emerged as an important consideration in data-driven solutions. Although various fairness definitions have been explored in the recent literature, there is lack of consensus on which metrics most accurately reflect the fairness of a system. In this work, we propose a new formulation : ACCUMULATED PREDICTION SENSITIVITY, which measures fairness in machine learning models based on the model’s prediction sensitivity to perturbations in input features. The metric attempts to quantify the extent to which a single prediction depends on a protected attribute, where the protected attribute encodes the membership status of an individual in a protected group. We show that the metric can be theoretically linked with a specific notion of group fairness (statistical parity) and individual fairness. It also correlates well with humans’ perception of fairness. We conduct experiments on two text classification datasets : JIGSAW TOXICITY, and BIAS IN BIOS, and evaluate the correlations between metrics and manual annotations on whether the model produced a fair outcome. We observe that the proposed fairness metric based on prediction sensitivity is statistically significantly more correlated with human annotation than the existing counterfactual fairness metric.
@inproceedings{krishna2022measuring, title = {Measuring Fairness of Text Classifiers via Prediction Sensitivity}, author = {Krishna, Satyapriya and Gupta, Rahul and Verma, Apurv and Dhamala, Jwala and Pruksachatkun, Yada and Chang, Kai-Wei}, booktitle = {ACL}, year = {2022} } -
Does Robustness Improve Fairness? Approaching Fairness with Word Substitution Robustness Methods for Text Classification
Yada Pruksachatkun, Satyapriya Krishna, Jwala Dhamala, Rahul Gupta, and Kai-Wei Chang, in ACL-Finding, 2021.
Full Text Code Abstract BibTeX DetailsDetailsExisting bias mitigation methods to reduce disparities in model outcomes across cohorts have focused on data augmentation, debiasing model embeddings, or adding fairness-based optimization objectives during training. Separately, certified word substitution robustness methods have been developed to decrease the impact of spurious features and synonym substitutions on model predictions. While their end goals are different, they both aim to encourage models to make the same prediction for certain changes in the input. In this paper, we investigate the utility of certified word substitution robustness methods to improve equality of odds and equality of opportunity on multiple text classification tasks. We observe that certified robustness methods improve fairness, and using both robustness and bias mitigation methods in training results in an improvement in both fronts.
@inproceedings{pruksachatkun2021robustness, title = {Does Robustness Improve Fairness? Approaching Fairness with Word Substitution Robustness Methods for Text Classification}, author = {Pruksachatkun, Yada and Krishna, Satyapriya and Dhamala, Jwala and Gupta, Rahul and Chang, Kai-Wei}, booktitle = {ACL-Finding}, year = {2021} } -
LOGAN: Local Group Bias Detection by Clustering
Jieyu Zhao and Kai-Wei Chang, in EMNLP (short), 2020.
Full Text Code Abstract BibTeX DetailsDetailsMachine learning techniques have been widely used in natural language processing (NLP). However, as revealed by many recent studies, machine learning models often inherit and amplify the societal biases in data. Various metrics have been proposed to quantify biases in model predictions. In particular, several of them evaluate disparity in model performance between protected groups and advantaged groups in the test corpus. However, we argue that evaluating bias at the corpus level is not enough for understanding how biases are embedded in a model. In fact, a model with similar aggregated performance between different groups on the entire data may behave differently on instances in a local region. To analyze and detect such local bias, we propose LOGAN, a new bias detection technique based on clustering. Experiments on toxicity classification and object classification tasks show that LOGAN identifies bias in a local region and allows us to better analyze the biases in model predictions.
@inproceedings{zhao2020logan, author = {Zhao, Jieyu and Chang, Kai-Wei}, title = {LOGAN: Local Group Bias Detection by Clustering}, booktitle = {EMNLP (short)}, presentation_id = {https://virtual.2020.emnlp.org/paper_main.2886.html}, year = {2020} } -
Towards Understanding Gender Bias in Relation Extraction
Andrew Gaut, Tony Sun, Shirlyn Tang, Yuxin Huang, Jing Qian, Mai ElSherief, Jieyu Zhao, Diba Mirza, Elizabeth Belding, Kai-Wei Chang, and William Yang Wang, in ACL, 2020.
Full Text Abstract BibTeX DetailsDetailsRecent developments in Neural Relation Extraction (NRE) have made significant strides towards automated knowledge base construction. While much attention has been dedicated towards improvements in accuracy, there have been no attempts in the literature to evaluate social biases exhibited in NRE systems. In this paper, we create WikiGenderBias, a distantly supervised dataset composed of over 45,000 sentences including a 10% human annotated test set for the purpose of analyzing gender bias in relation extraction systems. We find that when extracting spouse and hypernym (i.e., occupation) relations, an NRE system performs differently when the gender of the target entity is different. However, such disparity does not appear when extracting relations such as birth date or birth place. We also analyze two existing bias mitigation techniques, word embedding debiasing and data augmentation. Unfortunately, due to NRE models relying heavily on surface level cues, we find that existing bias mitigation approaches have a negative effect on NRE. Our analysis lays groundwork for future quantifying and mitigating bias in relation extraction.
@inproceedings{gaut2020towards, author = {Gaut, Andrew and Sun, Tony and Tang, Shirlyn and Huang, Yuxin and Qian, Jing and ElSherief, Mai and Zhao, Jieyu and Mirza, Diba and Belding, Elizabeth and Chang, Kai-Wei and Wang, William Yang}, title = {Towards Understanding Gender Bias in Relation Extraction}, booktitle = {ACL}, year = {2020}, presentation_id = {https://virtual.acl2020.org/paper_main.265.html} } -
Mitigating Gender Bias Amplification in Distribution by Posterior Regularization
Shengyu Jia, Tao Meng, Jieyu Zhao, and Kai-Wei Chang, in ACL (short), 2020.
Full Text Slides Video Code Abstract BibTeX DetailsDetailsAdvanced machine learning techniques have boosted the performance of natural language processing. Nevertheless, recent studies, e.g., Zhao et al. (2017) show that these techniques inadvertently capture the societal bias hiddenin the corpus and further amplify it. However,their analysis is conducted only on models’ top predictions. In this paper, we investigate thegender bias amplification issue from the distribution perspective and demonstrate that thebias is amplified in the view of predicted probability distribution over labels. We further propose a bias mitigation approach based on posterior regularization. With little performance loss, our method can almost remove the bias amplification in the distribution. Our study sheds the light on understanding the bias amplification.
@inproceedings{jia2020mitigating, author = {Jia, Shengyu and Meng, Tao and Zhao, Jieyu and Chang, Kai-Wei}, title = {Mitigating Gender Bias Amplification in Distribution by Posterior Regularization}, booktitle = {ACL (short)}, year = {2020}, presentation_id = {https://virtual.acl2020.org/paper_main.264.html} } -
Mitigating Gender in Natural Language Processing: Literature Review
Tony Sun, Andrew Gaut, Shirlyn Tang, Yuxin Huang, Mai ElSherief, Jieyu Zhao, Diba Mirza, Kai-Wei Chang, and William Yang Wang, in ACL, 2019.
Full Text Slides Video Abstract BibTeX DetailsDetailsAs Natural Language Processing (NLP) and Machine Learning (ML) tools rise in popularity, it becomes increasingly vital to recognize the role they play in shaping societal biases and stereotypes. Although NLP models have shown success in modeling various applications, they propagate and may even amplify gender bias found in text corpora. While the study of bias in artificial intelligence is not new, methods to mitigate gender bias in NLP are relatively nascent. In this paper, we review contemporary studies on recognizing and mitigating gender bias in NLP. We discuss gender bias based on four forms of representation bias and analyze methods recognizing gender bias. Furthermore, we discuss the advantages and drawbacks of existing gender debiasing methods. Finally, we discuss future studies for recognizing and mitigating gender bias in NLP.
@inproceedings{sun2019mitigating, author = {Sun, Tony and Gaut, Andrew and Tang, Shirlyn and Huang, Yuxin and ElSherief, Mai and Zhao, Jieyu and Mirza, Diba and Chang, Kai-Wei and Wang, William Yang}, title = {Mitigating Gender in Natural Language Processing: Literature Review}, booktitle = {ACL}, vimeo_id = {384482151}, year = {2019} } -
Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods
Jieyu Zhao, Tianlu Wang, Mark Yatskar, Vicente Ordonez, and Kai-Wei Chang, in NAACL (short), 2018.
Full Text Poster Code Abstract BibTeX Details Top-10 cited paper at NAACL 18DetailsIn this paper, we introduce a new benchmark for co-reference resolution focused on gender bias, WinoBias. Our corpus contains Winograd-schema style sentences with entities corresponding to people referred by their occupation (e.g. the nurse, the doctor, the carpenter). We demonstrate that a rule-based, a feature-rich, and a neural coreference system all link gendered pronouns to pro-stereotypical entities with higher accuracy than anti-stereotypical entities, by an average difference of 21.1 in F1 score. Finally, we demonstrate a data-augmentation approach that, in combination with existing word-embedding debiasing techniques, removes the bias demonstrated by these systems in WinoBias without significantly affecting their performance on existing datasets.
@inproceedings{zhao2018gender, author = {Zhao, Jieyu and Wang, Tianlu and Yatskar, Mark and Ordonez, Vicente and Chang, Kai-Wei}, title = {Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods}, booktitle = {NAACL (short)}, press_url = {https://www.stitcher.com/podcast/matt-gardner/nlp-highlights/e/55861936}, year = {2018} } -
Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints
Jieyu Zhao, Tianlu Wang, Mark Yatskar, Vicente Ordonez, and Kai-Wei Chang, in EMNLP, 2017.
Full Text Slides Code Abstract BibTeX Details EMNLP 2017 Best Long Paper Award; Top-10 cited paper at EMNLP 17DetailsLanguage is increasingly being used to define rich visual recognition problems with supporting image collections sourced from the web. Structured prediction models are used in these tasks to take advantage of correlations between co-occuring labels and visual input but risk inadvertently encoding social biases found in web corpora. In this work, we study data and models associated with multilabel object classification and visual semantic role labeling. We find that (a) datasets for these tasks contain significant gender bias and (b) models trained on these datasets further amplify existing bias. For example, the activity cooking is over 33% more likely to involve females than males in a training set, but a trained model amplifies the disparity to 68% at test time. We propose to inject corpus-level constraints for calibrating existing structured prediction models and design an algorithm based on Lagrangian relaxation for the resulting inference problems. Our method results in no performance loss for the underlying recognition task but decreases the magnitude of bias amplification by 33.3% and 44.9% for multilabel classification and visual semantic role labeling, respectively.
@inproceedings{zhao2017men, author = {Zhao, Jieyu and Wang, Tianlu and Yatskar, Mark and Ordonez, Vicente and Chang, Kai-Wei}, title = {Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints}, booktitle = {EMNLP}, year = {2017} }
-
Towards Controllable Biases in Language Generation
Emily Sheng, Kai-Wei Chang, Premkumar Natarajan, and Nanyun Peng, in EMNLP-Finding, 2020.
Full Text Code BibTeX DetailsDetails
We present a general approach towards controllable societal biases in natural language generation (NLG). Building upon the idea of adversarial triggers, we develop a method to induce societal biases in generated text when input prompts contain mentions of specific demographic groups. We then analyze two scenarios: 1) inducing negative biases for one demographic and positive biases for another demographic, and 2) equalizing biases between demographics. The former scenario enables us to detect the types of biases present in the model. Specifically, we show the effectiveness of our approach at facilitating bias analysis by finding topics that correspond to demographic inequalities in generated text and comparing the relative effectiveness of inducing biases for different demographics. The second scenario is useful for mitigating biases in downstream applications such as dialogue generation. In our experiments, the mitigation technique proves to be effective at equalizing the amount of biases across demographics while simultaneously generating less negatively biased text overall.
@inproceedings{sheng2020towards, title = {Towards Controllable Biases in Language Generation}, author = {Sheng, Emily and Chang, Kai-Wei and Natarajan, Premkumar and Peng, Nanyun}, booktitle = {EMNLP-Finding}, year = {2020} }Excited to finally share our work “Towards Controllable Biases in Language Generation” (https://t.co/Y7TbcSOsbX), to appear in Findings of #emnlp2020, and done with @kaiwei_chang, Prem Natarajan, and @VioletNPeng :)
— Emily Sheng (@ewsheng) October 8, 2020Related Publications
-
Are Personalized Stochastic Parrots More Dangerous? Evaluating Persona Biases in Dialogue Systems
Yixin Wan, Jieyu Zhao, Aman Chadha, Nanyun Peng, and Kai-Wei Chang, in EMNLP-Finding, 2023.
Full Text Abstract BibTeX DetailsDetailsRecent advancements in Large Language Models empower them to follow freeform instructions, including imitating generic or specific demographic personas in conversations. Generic personas refer to a demographic group (e.g. an Asian person), whereas specific personas can be actual names of historical figures. While the adoption of personas allows dialogue systems to be more engaging and approachable to users, it also carries the potential risk of exacerbating social biases in model responses, further causing societal harms through interactions with users. In this paper, we systematically study “persona biases”, which we define to be the sensitivity of harmful dialogue model behaviors to different persona adoptions.We categorize persona biases into biases in harmful expression and harmful agreement, as well as establish a comprehensive evaluation framework to measure persona biases in five aspects: Offensiveness, Toxic Continuation, Regard, Stereotype Agreement, and Toxic Agreement. Additionally, we propose to comprehensively investigate persona biases through experimenting with UniversalPersona, a systematized persona dataset with a comprehensive list of both generic and specific model personas. Through benchmarking on four different models, including Blender, ChatGPT, Alpaca, and Vicuna, our study uncovers significant persona biases in dialogue systems. Findings of our study underscores the immediate need to revisit the use of persona traits in dialogue agents to ensure their safe application.
@inproceedings{wan2023personalized, author = {Wan, Yixin and Zhao, Jieyu and Chadha, Aman and Peng, Nanyun and Chang, Kai-Wei}, title = {Are Personalized Stochastic Parrots More Dangerous? Evaluating Persona Biases in Dialogue Systems}, booktitle = {EMNLP-Finding}, year = {2023} } -
Kelly is a Warm Person, Joseph is a Role Model: Gender Biases in LLM-Generated Reference Letters
Yixin Wan, George Pu, Jiao Sun, Aparna Garimella, Kai-Wei Chang, and Nanyun Peng, in EMNLP-Findings, 2023.
Full Text Abstract BibTeX DetailsDetailsAs generative language models advance, users have started to utilize Large Language Models (LLMs) to assist in writing various types of content, including professional documents such as recommendation letters. Despite their convenience, these applications introduce unprecedented fairness concerns. As generated reference letter might be directly utilized by users in professional or academic scenarios, it has the potential to cause direct harm such as lowering success rates for female applicants. Therefore, it is imminent and necessary to comprehensively study fairness issues and associated harms in such real-world use cases for future mitigation and monitoring. In this paper, we critically examine gender bias in LLM-generated reference letters. Inspired by findings in social science, we specifically design evaluation methods to manifest gender biases in LLM-generated letters through two dimensions: biases in language style and biases in lexical content. Furthermore, we investigate the extent of bias propagation by separately analyze bias amplification in model-hallucinated contents, which we define to be hallucination bias of model-generated documents. Through benchmarking evaluation on 4 popular LLMs, including ChatGPT, Alpaca, Vicuna and StableLM, our study reveal significant gender biases in LLM-generated recommendation letters. Our findings further point towards the importance and imminence to recognize bias in LLM-generated professional documents.
@inproceedings{wan2023kelly, title = {Kelly is a Warm Person, Joseph is a Role Model: Gender Biases in LLM-Generated Reference Letters}, author = {Wan, Yixin and Pu, George and Sun, Jiao and Garimella, Aparna and Chang, Kai-Wei and Peng, Nanyun}, booktitle = {EMNLP-Findings}, year = {2023} } -
How well can Text-to-Image Generative Models understand Ethical Natural Language Interventions?
Hritik Bansal, Da Yin, Masoud Monajatipoor, and Kai-Wei Chang, in EMNLP (Short), 2022.
Full Text Code Abstract BibTeX DetailsDetailsText-to-image generative models have achieved unprecedented success in generating high-quality images based on natural language descriptions. However, it is shown that these models tend to favor specific social groups when prompted with neutral text descriptions (e.g., ’a photo of a lawyer’). Following Zhao et al. (2021), we study the effect on the diversity of the generated images when adding ethical intervention that supports equitable judgment (e.g., ’if all individuals can be a lawyer irrespective of their gender’) in the input prompts. To this end, we introduce an Ethical NaTural Language Interventions in Text-to-Image GENeration (ENTIGEN) benchmark dataset to evaluate the change in image generations conditional on ethical interventions across three social axes – gender, skin color, and culture. Through ENTIGEN framework, we find that the generations from minDALL.E, DALL.E-mini and Stable Diffusion cover diverse social groups while preserving the image quality. Preliminary studies indicate that a large change in the model predictions is triggered by certain phrases such as ’irrespective of gender’ in the context of gender bias in the ethical interventions. We release code and annotated data at https://github.com/Hritikbansal/entigen_emnlp.
@inproceedings{bansal2022how, title = {How well can Text-to-Image Generative Models understand Ethical Natural Language Interventions?}, author = {Bansal, Hritik and Yin, Da and Monajatipoor, Masoud and Chang, Kai-Wei}, booktitle = {EMNLP (Short)}, year = {2022} } -
On the Intrinsic and Extrinsic Fairness Evaluation Metrics for Contextualized Language Representations
Yang Trista Cao, Yada Pruksachatkun, Kai-Wei Chang, Rahul Gupta, Varun Kumar, Jwala Dhamala, and Aram Galstyan, in ACL (short), 2022.
Full Text Abstract BibTeX DetailsDetailsMultiple metrics have been introduced to measure fairness in various natural language processing tasks. These metrics can be roughly categorized into two categories: 1) \emphextrinsic metrics for evaluating fairness in downstream applications and 2) \emphintrinsic metrics for estimating fairness in upstream contextualized language representation models. In this paper, we conduct an extensive correlation study between intrinsic and extrinsic metrics across bias notions using 19 contextualized language models. We find that intrinsic and extrinsic metrics do not necessarily correlate in their original setting, even when correcting for metric misalignments, noise in evaluation datasets, and confounding factors such as experiment configuration for extrinsic metrics.
@inproceedings{trista2022evaluation, title = {On the Intrinsic and Extrinsic Fairness Evaluation Metrics for Contextualized Language Representations}, author = {Cao, Yang Trista and Pruksachatkun, Yada and Chang, Kai-Wei and Gupta, Rahul and Kumar, Varun and Dhamala, Jwala and Galstyan, Aram}, booktitle = {ACL (short)}, year = {2022} } -
Societal Biases in Language Generation: Progress and Challenges
Emily Sheng, Kai-Wei Chang, Prem Natarajan, and Nanyun Peng, in ACL, 2021.
Full Text Abstract BibTeX DetailsDetailsTechnology for language generation has advanced rapidly, spurred by advancements in pre-training large models on massive amounts of data and the need for intelligent agents to communicate in a natural manner. While techniques can effectively generate fluent text, they can also produce undesirable societal biases that can have a disproportionately negative impact on marginalized populations. Language generation presents unique challenges for biases in terms of direct user interaction and the structure of decoding techniques. To better understand these challenges, we present a survey on societal biases in language generation, focusing on how data and techniques contribute to biases and progress towards reducing biases. Motivated by a lack of studies on biases from decoding techniques, we also conduct experiments to quantify the effects of these techniques. By further discussing general trends and open challenges, we call to attention promising directions for research and the importance of fairness and inclusivity considerations for language generation applications.
@inproceedings{sheng2021societam, title = {Societal Biases in Language Generation: Progress and Challenges}, author = {Sheng, Emily and Chang, Kai-Wei and Natarajan, Prem and Peng, Nanyun}, booktitle = {ACL}, year = {2021} } -
"Nice Try, Kiddo": Investigating Ad Hominems in Dialogue Responses
Emily Sheng, Kai-Wei Chang, Prem Natarajan, and Nanyun Peng, in NAACL, 2021.
Full Text Video Code Abstract BibTeX DetailsDetailsAd hominem attacks are those that target some feature of a person’s character instead of the position the person is maintaining. These attacks are harmful because they propagate implicit biases and diminish a person’s credibility. Since dialogue systems respond directly to user input, it is important to study ad hominems in dialogue responses. To this end, we propose categories of ad hominems, compose an annotated dataset, and build a classifier to analyze human and dialogue system responses to English Twitter posts. We specifically compare responses to Twitter topics about marginalized communities (#BlackLivesMatter, #MeToo) versus other topics (#Vegan, #WFH), because the abusive language of ad hominems could further amplify the skew of power away from marginalized populations. Furthermore, we propose a constrained decoding technique that uses salient n-gram similarity as a soft constraint for top-k sampling to reduce the amount of ad hominems generated. Our results indicate that 1) responses from both humans and DialoGPT contain more ad hominems for discussions around marginalized communities, 2) different quantities of ad hominems in the training data can influence the likelihood of generating ad hominems, and 3) we can use constrained decoding techniques to reduce ad hominems in generated dialogue responses.
@inproceedings{sheng2021nice, title = {"Nice Try, Kiddo": Investigating Ad Hominems in Dialogue Responses}, booktitle = {NAACL}, author = {Sheng, Emily and Chang, Kai-Wei and Natarajan, Prem and Peng, Nanyun}, presentation_id = {https://underline.io/events/122/sessions/4137/lecture/19854-%27nice-try,-kiddo%27-investigating-ad-hominems-in-dialogue-responses}, year = {2021} } -
BOLD: Dataset and metrics for measuring biases in open-ended language generation
Jwala Dhamala, Tony Sun, Varun Kumar, Satyapriya Krishna, Yada Pruksachatkun, Kai-Wei Chang, and Rahul Gupta, in FAccT, 2021.
Full Text Code Abstract BibTeX DetailsDetailsRecent advances in deep learning techniques have enabled machines to generate cohesive open-ended text when prompted with a sequence of words as context. While these models now empower many downstream applications from conversation bots to automatic storytelling, they have been shown to generate texts that exhibit social biases. To systematically study and benchmark social biases in open-ended language generation, we introduce the Bias in Open-Ended Language Generation Dataset (BOLD), a large-scale dataset that consists of 23,679 English text generation prompts for bias benchmarking across five domains: profession, gender, race, religion, and political ideology. We also propose new automated metrics for toxicity, psycholinguistic norms, and text gender polarity to measure social biases in open-ended text generation from multiple angles. An examination of text generated from three popular language models reveals that the majority of these models exhibit a larger social bias than human-written Wikipedia text across all domains. With these results we highlight the need to benchmark biases in open-ended language generation and caution users of language generation models on downstream tasks to be cognizant of these embedded prejudices.
@inproceedings{dhamala2021bold, author = {Dhamala, Jwala and Sun, Tony and Kumar, Varun and Krishna, Satyapriya and Pruksachatkun, Yada and Chang, Kai-Wei and Gupta, Rahul}, title = {BOLD: Dataset and metrics for measuring biases in open-ended language generation}, booktitle = {FAccT}, year = {2021} } -
Towards Controllable Biases in Language Generation
Emily Sheng, Kai-Wei Chang, Premkumar Natarajan, and Nanyun Peng, in EMNLP-Finding, 2020.
Full Text Code Abstract BibTeX DetailsDetailsWe present a general approach towards controllable societal biases in natural language generation (NLG). Building upon the idea of adversarial triggers, we develop a method to induce societal biases in generated text when input prompts contain mentions of specific demographic groups. We then analyze two scenarios: 1) inducing negative biases for one demographic and positive biases for another demographic, and 2) equalizing biases between demographics. The former scenario enables us to detect the types of biases present in the model. Specifically, we show the effectiveness of our approach at facilitating bias analysis by finding topics that correspond to demographic inequalities in generated text and comparing the relative effectiveness of inducing biases for different demographics. The second scenario is useful for mitigating biases in downstream applications such as dialogue generation. In our experiments, the mitigation technique proves to be effective at equalizing the amount of biases across demographics while simultaneously generating less negatively biased text overall.
@inproceedings{sheng2020towards, title = {Towards Controllable Biases in Language Generation}, author = {Sheng, Emily and Chang, Kai-Wei and Natarajan, Premkumar and Peng, Nanyun}, booktitle = {EMNLP-Finding}, year = {2020} } -
The Woman Worked as a Babysitter: On Biases in Language Generation
Emily Sheng, Kai-Wei Chang, Premkumar Natarajan, and Nanyun Peng, in EMNLP (short), 2019.
Full Text Slides Video Code Abstract BibTeX DetailsDetailsWe present a systematic study of biases in natural language generation (NLG) by analyzing text generated from prompts that contain mentions of different demographic groups. In this work, we introduce the notion of the regard towards a demographic, use the varying levels of regard towards different demographics as a defining metric for bias in NLG, and analyze the extent to which sentiment scores are a relevant proxy metric for regard. To this end, we collect strategically-generated text from language models and manually annotate the text with both sentiment and regard scores. Additionally, we build an automatic regard classifier through transfer learning, so that we can analyze biases in unseen text. Together, these methods reveal the extent of the biased nature of language model generations. Our analysis provides a study of biases in NLG, bias metrics and correlated human judgments, and empirical evidence on the usefulness of our annotated dataset.
@inproceedings{sheng2019woman, author = {Sheng, Emily and Chang, Kai-Wei and Natarajan, Premkumar and Peng, Nanyun}, title = {The Woman Worked as a Babysitter: On Biases in Language Generation}, booktitle = {EMNLP (short)}, vimeo_id = {426366363}, year = {2019} }
-
Cross-Lingual Transfer
Cross-Lingual Dependency Parsing by POS-Guided Word Reordering
Lu Liu, Yi Zhou, Jianhan Xu, Xiaoqing Zheng, Kai-Wei Chang, and Xuanjing Huang, in EMNLP-Finding, 2020.
Full Text BibTeX DetailsDetails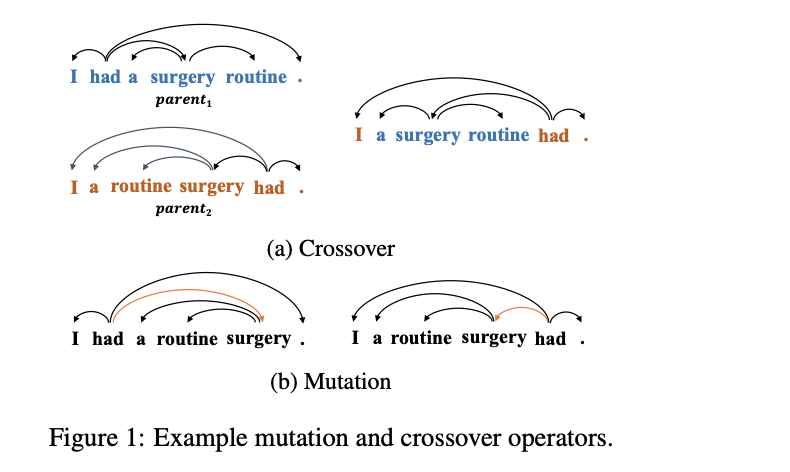
We propose a novel approach to cross-lingual dependency parsing based on word reordering. The words in each sentence of a source language corpus are rearranged to meet the word order in a target language under the guidance of a part-of-speech based language model (LM). To obtain the highest reordering score under the LM, a population-based optimization algorithm and its genetic operators are designed to deal with the combinatorial nature of such word reordering. A parser trained on the reordered corpus then can be used to parse sentences in the target language. We demonstrate through extensive experimentation that our approach achieves better or comparable results across 25 target languages (1.73% increase in average), and outperforms a baseline by a significant margin on the languages that are greatly different from the source one. For example, when transferring the English parser to Hindi and Latin, our approach outperforms the baseline by 15.3% and 6.7% respectively.
@inproceedings{liu2020cross-lingual, author = {Liu, Lu and Zhou, Yi and Xu, Jianhan and Zheng, Xiaoqing and Chang, Kai-Wei and Huang, Xuanjing}, title = {Cross-Lingual Dependency Parsing by POS-Guided Word Reordering}, booktitle = {EMNLP-Finding}, year = {2020} }Related Publications
-
Multilingual Generative Language Models for Zero-Shot Cross-Lingual Event Argument Extraction
Kuan-Hao Huang, I.-Hung Hsu, Prem Natarajan, Kai-Wei Chang, and Nanyun Peng, in ACL, 2022.
Full Text Code Abstract BibTeX DetailsDetailsWe present a study on leveraging multilingual pre-trained generative language models for zero-shot cross-lingual event argument extraction (EAE). By formulating EAE as a language generation task, our method effectively encodes event structures and captures the dependencies between arguments. We design language-agnostic templates to represent the event argument structures, which are compatible with any language, hence facilitating the cross-lingual transfer. Our proposed model finetunes multilingual pre-trained generative language models to generate sentences that fill in the language-agnostic template with arguments extracted from the input passage. The model is trained on source languages and is then directly applied to target languages for event argument extraction. Experiments demonstrate that the proposed model outperforms the current state-of-the-art models on zero-shot cross-lingual EAE. Comprehensive studies and error analyses are presented to better understand the advantages and the current limitations of using generative language models for zero-shot cross-lingual transfer EAE.
@inproceedings{huang2022multilingual, title = {Multilingual Generative Language Models for Zero-Shot Cross-Lingual Event Argument Extraction}, author = {Huang, Kuan-Hao and Hsu, I-Hung and Natarajan, Prem and Chang, Kai-Wei and Peng, Nanyun}, booktitle = {ACL}, year = {2022} } -
Improving Zero-Shot Cross-Lingual Transfer Learning via Robust Training
Kuan-Hao Huang, Wasi Ahmad, Nanyun Peng, and Kai-Wei Chang, in EMNLP, 2021.
Full Text Code Abstract BibTeX DetailsDetailsPre-trained multilingual language encoders, such as multilingual BERT and XLM-R, show great potential for zero-shot cross-lingual transfer. However, these multilingual encoders do not precisely align words and phrases across languages. Especially, learning alignments in the multilingual embedding space usually requires sentence-level or word-level parallel corpora, which are expensive to be obtained for low-resource languages. An alternative is to make the multilingual encoders more robust; when fine-tuning the encoder using downstream task, we train the encoder to tolerate noise in the contextual embedding spaces such that even if the representations of different languages are not aligned well, the model can still achieve good performance on zero-shot cross-lingual transfer. In this work, we propose a learning strategy for training robust models by drawing connections between adversarial examples and the failure cases of zero-shot cross-lingual transfer. We adopt two widely used robust training methods, adversarial training and randomized smoothing, to train the desired robust model. The experimental results demonstrate that robust training improves zero-shot cross-lingual transfer on text classification tasks. The improvement is more significant in the generalized cross-lingual transfer setting, where the pair of input sentences belong to two different languages.
@inproceedings{huang2021improving, title = {Improving Zero-Shot Cross-Lingual Transfer Learning via Robust Training}, author = {Huang, Kuan-Hao and Ahmad, Wasi and Peng, Nanyun and Chang, Kai-Wei}, presentation_id = {https://underline.io/events/192/posters/7783/poster/40656-improving-zero-shot-cross-lingual-transfer-learning-via-robust-training}, booktitle = {EMNLP}, year = {2021} } -
Syntax-augmented Multilingual BERT for Cross-lingual Transfer
Wasi Ahmad, Haoran Li, Kai-Wei Chang, and Yashar Mehdad, in ACL, 2021.
Full Text Video Code Abstract BibTeX DetailsDetailsIn recent years, we have seen a colossal effort in pre-training multilingual text encoders using large-scale corpora in many languages to facilitate cross-lingual transfer learning. However, due to typological differences across languages, the cross-lingual transfer is challenging. Nevertheless, language syntax, e.g., syntactic dependencies, can bridge the typological gap. Previous works have shown that pretrained multilingual encoders, such as mBERT (Devlin et al., 2019), capture language syntax, helping cross-lingual transfer. This work shows that explicitly providing language syntax and training mBERT using an auxiliary objective to encode the universal dependency tree structure helps cross-lingual transfer. We perform rigorous experiments on four NLP tasks, including text classification, question answering, named entity recognition, and taskoriented semantic parsing. The experiment results show that syntax-augmented mBERT improves cross-lingual transfer on popular benchmarks, such as PAWS-X and MLQA, by 1.4 and 1.6 points on average across all languages. In the generalized transfer setting, the performance boosted significantly, with 3.9 and 3.1 points on average in PAWS-X and MLQA.
@inproceedings{ahmad2021syntax, title = {Syntax-augmented Multilingual BERT for Cross-lingual Transfer}, author = {Ahmad, Wasi and Li, Haoran and Chang, Kai-Wei and Mehdad, Yashar}, booktitle = {ACL}, year = {2021} } -
Evaluating the Values of Sources in Transfer Learning
Md Rizwan Parvez and Kai-Wei Chang, in NAACL, 2021.
Full Text Video Code Abstract BibTeX DetailsDetailsTransfer learning that adapts a model trained on data-rich sources to low-resource targets has been widely applied in natural language processing (NLP). However, when training a transfer model over multiple sources, not every source is equally useful for the target. To better transfer a model, it is essential to understand the values of the sources. In this paper, we develop SEAL-Shap, an efficient source valuation framework for quantifying the usefulness of the sources (e.g., domains/languages) in transfer learning based on the Shapley value method. Experiments and comprehensive analyses on both cross-domain and cross-lingual transfers demonstrate that our framework is not only effective in choosing useful transfer sources but also the source values match the intuitive source-target similarity.
@inproceedings{parvez2021evaluating, title = {Evaluating the Values of Sources in Transfer Learning}, author = {Parvez, Md Rizwan and Chang, Kai-Wei}, booktitle = {NAACL}, presentation_id = {https://underline.io/events/122/sessions/4261/lecture/19707-evaluating-the-values-of-sources-in-transfer-learning}, year = {2021} } -
GATE: Graph Attention Transformer Encoder for Cross-lingual Relation and Event Extraction
Wasi Ahmad, Nanyun Peng, and Kai-Wei Chang, in AAAI, 2021.
Full Text Code Abstract BibTeX DetailsDetailsPrevalent approaches in cross-lingual relation and event extraction use graph convolutional networks (GCNs) with universal dependency parses to learn language-agnostic representations such that models trained on one language can be applied to other languages. However, GCNs lack in modeling long-range dependencies or disconnected words in the dependency tree. To address this challenge, we propose to utilize the self-attention mechanism where we explicitly fuse structural information to learn the dependencies between words at different syntactic distances. We introduce GATE, a \bf Graph \bf Attention \bf Transformer \bf Encoder, and test its cross-lingual transferability on relation and event extraction tasks. We perform rigorous experiments on the widely used ACE05 dataset that includes three typologically different languages: English, Chinese, and Arabic. The evaluation results show that GATE outperforms three recently proposed methods by a large margin. Our detailed analysis reveals that due to the reliance on syntactic dependencies, GATE produces robust representations that facilitate transfer across languages.
@inproceedings{ahmad2021gate, author = {Ahmad, Wasi and Peng, Nanyun and Chang, Kai-Wei}, title = {GATE: Graph Attention Transformer Encoder for Cross-lingual Relation and Event Extraction}, booktitle = {AAAI}, year = {2021} } -
Cross-Lingual Dependency Parsing by POS-Guided Word Reordering
Lu Liu, Yi Zhou, Jianhan Xu, Xiaoqing Zheng, Kai-Wei Chang, and Xuanjing Huang, in EMNLP-Finding, 2020.
Full Text Abstract BibTeX DetailsDetailsWe propose a novel approach to cross-lingual dependency parsing based on word reordering. The words in each sentence of a source language corpus are rearranged to meet the word order in a target language under the guidance of a part-of-speech based language model (LM). To obtain the highest reordering score under the LM, a population-based optimization algorithm and its genetic operators are designed to deal with the combinatorial nature of such word reordering. A parser trained on the reordered corpus then can be used to parse sentences in the target language. We demonstrate through extensive experimentation that our approach achieves better or comparable results across 25 target languages (1.73% increase in average), and outperforms a baseline by a significant margin on the languages that are greatly different from the source one. For example, when transferring the English parser to Hindi and Latin, our approach outperforms the baseline by 15.3% and 6.7% respectively.
@inproceedings{liu2020cross-lingual, author = {Liu, Lu and Zhou, Yi and Xu, Jianhan and Zheng, Xiaoqing and Chang, Kai-Wei and Huang, Xuanjing}, title = {Cross-Lingual Dependency Parsing by POS-Guided Word Reordering}, booktitle = {EMNLP-Finding}, year = {2020} } -
Cross-lingual Dependency Parsing with Unlabeled Auxiliary Languages
Wasi Ahmad, Zhisong Zhang, Xuezhe Ma, Kai-Wei Chang, and Nanyun Peng, in CoNLL, 2019.
Full Text Poster Code Abstract BibTeX DetailsDetailsCross-lingual transfer learning has become an important weapon to battle the unavailability of annotated resources for low-resource languages. One of the fundamental techniques to transfer across languages is learning language-agnostic representations, in the form of word embeddings or contextual encodings. In this work, we propose to leverage unannotated sentences from auxiliary languages to help learning language-agnostic representations Specifically, we explore adversarial training for learning contextual encoders that produce invariant representations across languages to facilitate cross-lingual transfer. We conduct experiments on cross-lingual dependency parsing where we train a dependency parser on a source language and transfer it to a wide range of target languages. Experiments on 28 target languages demonstrate that adversarial training significantly improves the overall transfer performances under several different settings. We conduct a careful analysis to evaluate the language-agnostic representations resulted from adversarial training.
@inproceedings{ahmad2019crosslingual, author = {Ahmad, Wasi and Zhang, Zhisong and Ma, Xuezhe and Chang, Kai-Wei and Peng, Nanyun}, title = { Cross-lingual Dependency Parsing with Unlabeled Auxiliary Languages}, booktitle = {CoNLL}, year = {2019} } -
Target Language-Aware Constrained Inference for Cross-lingual Dependency Parsing
Tao Meng, Nanyun Peng, and Kai-Wei Chang, in EMNLP, 2019.
Full Text Poster Code Abstract BibTeX DetailsDetailsPrior work on cross-lingual dependency parsing often focuses on capturing the commonalities between source and target languages and overlooks the potential of leveraging linguistic properties of the languages to facilitate the transfer. In this paper, we show that weak supervisions of linguistic knowledge for the target languages can improve a cross-lingual graph-based dependency parser substantially. Specifically, we explore several types of corpus linguistic statistics and compile them into corpus-wise constraints to guide the inference process during the test time. We adapt two techniques, Lagrangian relaxation and posterior regularization, to conduct inference with corpus-statistics constraints. Experiments show that the Lagrangian relaxation and posterior regularization inference improve the performances on 15 and 17 out of 19 target languages, respectively. The improvements are especially significant for target languages that have different word order features from the source language.
@inproceedings{meng2019target, author = {Meng, Tao and Peng, Nanyun and Chang, Kai-Wei}, title = {Target Language-Aware Constrained Inference for Cross-lingual Dependency Parsing}, booktitle = {EMNLP}, year = {2019} } -
On Difficulties of Cross-Lingual Transfer with Order Differences: A Case Study on Dependency Parsing
Wasi Uddin Ahmad, Zhisong Zhang, Xuezhe Ma, Eduard Hovy, Kai-Wei Chang, and Nanyun Peng, in NAACL, 2019.
Full Text Video Code Abstract BibTeX DetailsDetailsDifferent languages might have different wordorders. In this paper, we investigate cross-lingual transfer and posit that an order-agnostic model will perform better when trans-ferring to distant foreign languages. To test ourhypothesis, we train dependency parsers on anEnglish corpus and evaluate their transfer per-formance on 30 other languages. Specifically,we compare encoders and decoders based onRecurrent Neural Networks (RNNs) and mod-ified self-attentive architectures. The formerrelies on sequential information while the lat-ter is more flexible at modeling word order.Rigorous experiments and detailed analysisshows that RNN-based architectures transferwell to languages that are close to English,while self-attentive models have better overallcross-lingual transferability and perform espe-cially well on distant languages.
@inproceedings{ahmad2019difficulties, author = {Ahmad, Wasi Uddin and Zhang, Zhisong and Ma, Xuezhe and Hovy, Eduard and Chang, Kai-Wei and Peng, Nanyun}, title = {On Difficulties of Cross-Lingual Transfer with Order Differences: A Case Study on Dependency Parsing}, booktitle = {NAACL}, year = {2019} }
-
NLP for Social Good
PolicyQA: A Reading Comprehension Dataset for Privacy Policies
Wasi Ahmad, Jianfeng Chi, Yuan Tian, and Kai-Wei Chang, in EMNLP-Finding (short), 2020.
Full Text Code BibTeX DetailsDetails
Privacy policy documents are long and verbose. A question answering (QA) system can assist users in finding the information that is relevant and important to them. Prior studies in this domain frame the QA task as retrieving the most relevant text segment or a list of sentences from the policy document given a question. On the contrary, we argue that providing users with a short text span from policy documents reduces the burden of searching the target information from a lengthy text segment. In this paper, we present PolicyQA, a dataset that contains 25,017 reading comprehension style examples curated from an existing corpus of 115 website privacy policies. PolicyQA provides 714 human-annotated questions written for a wide range of privacy practices. We evaluate two existing neural QA models and perform rigorous analysis to reveal the advantages and challenges offered by PolicyQA.
@inproceedings{ahmad2020policyqa, author = {Ahmad, Wasi and Chi, Jianfeng and Tian, Yuan and Chang, Kai-Wei}, title = {PolicyQA: A Reading Comprehension Dataset for Privacy Policies}, booktitle = {EMNLP-Finding (short)}, year = {2020} }Related Publications
-
Relation-Guided Pre-Training for Open-Domain Question Answering
Ziniu Hu, Yizhou Sun, and Kai-Wei Chang, in EMNLP-Finding, 2021.
Full Text Abstract BibTeX DetailsDetailsAnswering complex open-domain questions requires understanding the latent relations between involving entities. However, we found that the existing QA datasets are extremely imbalanced in some types of relations, which hurts the generalization performance over questions with long-tail relations. To remedy this problem, in this paper, we propose a Relation-Guided Pre-Training (RGPT-QA) framework. We first generate a relational QA dataset covering a wide range of relations from both the Wikidata triplets and Wikipedia hyperlinks. We then pre-train a QA model to infer the latent relations from the question, and then conduct extractive QA to get the target answer entity. We demonstrate that by pretraining with propoed RGPT-QA techique, the popular open-domain QA model, Dense Passage Retriever (DPR), achieves 2.2%, 2.4%, and 6.3% absolute improvement in Exact Match accuracy on Natural Questions, TriviaQA, and WebQuestions. Particularly, we show that RGPT-QA improves significantly on questions with long-tail relations
@inproceedings{hu2021relation, title = {Relation-Guided Pre-Training for Open-Domain Question Answering}, author = {Hu, Ziniu and Sun, Yizhou and Chang, Kai-Wei}, presentation_id = {https://underline.io/events/192/sessions/7932/lecture/38507-relation-guided-pre-training-for-open-domain-question-answering}, booktitle = {EMNLP-Finding}, year = {2021} } -
An Integer Linear Programming Framework for Mining Constraints from Data
Tao Meng and Kai-Wei Chang, in ICML, 2021.
Full Text Video Code Abstract BibTeX DetailsDetailsVarious structured output prediction problems (e.g., sequential tagging) involve constraints over the output space. By identifying these constraints, we can filter out infeasible solutions and build an accountable model. To this end, we present a general integer linear programming (ILP) framework for mining constraints from data. We model the inference of structured output prediction as an ILP problem. Then, given the coefficients of the objective function and the corresponding solution, we mine the underlying constraints by estimating the outer and inner polytopes of the feasible set. We verify the proposed constraint mining algorithm in various synthetic and real-world applications and demonstrate that the proposed approach successfully identifies the feasible set at scale. In particular, we show that our approach can learn to solve 9x9 Sudoku puzzles and minimal spanning tree problems from examples without providing the underlying rules. We also demonstrate results on hierarchical multi-label classification and conduct a theoretical analysis on how close the mined constraints are from the ground truth.
@inproceedings{meng2020integer, author = {Meng, Tao and Chang, Kai-Wei}, title = {An Integer Linear Programming Framework for Mining Constraints from Data}, booktitle = {ICML}, year = {2021} } -
Generating Syntactically Controlled Paraphrases without Using Annotated Parallel Pairs
Kuan-Hao Huang and Kai-Wei Chang, in EACL, 2021.
Full Text Slides Poster Code Abstract BibTeX DetailsDetailsParaphrase generation plays an essential role in natural language process (NLP), and it has many downstream applications. However, training supervised paraphrase models requires many annotated paraphrase pairs, which are usually costly to obtain. On the other hand, the paraphrases generated by existing unsupervised approaches are usually syntactically similar to the source sentences and are limited in diversity. In this paper, we demonstrate that it is possible to generate syntactically various paraphrases without the need for annotated paraphrase pairs. We propose Syntactically controlled Paraphrase Generator (SynPG), an encoder-decoder based model that learns to disentangle the semantics and the syntax of a sentence from a collection of unannotated texts. The disentanglement enables SynPG to control the syntax of output paraphrases by manipulating the embedding in the syntactic space. Extensive experiments using automatic metrics and human evaluation show that SynPG performs better syntactic control than unsupervised baselines, while the quality of the generated paraphrases is competitive. We also demonstrate that the performance of SynPG is competitive or even better than supervised models when the unannotated data is large. Finally, we show that the syntactically controlled paraphrases generated by SynPG can be utilized for data augmentation to improve the robustness of NLP models.
@inproceedings{huang2021generating, author = {Huang, Kuan-Hao and Chang, Kai-Wei}, title = {Generating Syntactically Controlled Paraphrases without Using Annotated Parallel Pairs}, booktitle = {EACL}, year = {2021} } -
Clinical Temporal Relation Extraction with Probabilistic Soft Logic Regularization and Global Inference
Yichao Zhou, Yu Yan, Rujun Han, J. Harry Caufield, Kai-Wei Chang, Yizhou Sun, Peipei Ping, and Wei Wang, in AAAI, 2021.
Full Text Code Abstract BibTeX DetailsDetailsThere has been a steady need in the medical community to precisely extract the temporal relations between clinical events. In particular, temporal information can facilitate a variety of downstream applications such as case report retrieval and medical question answering. However, existing methods either require expensive feature engineering or are incapable of modeling the global relational dependencies among theevents. In this paper, we propose Clinical Temporal Relation Exaction with Probabilistic Soft Logic Regularization and Global Inference (CTRL-PG), a novel method to tackle the problem at the document level. Extensive experiments on two benchmark datasets, I2B2-2012 and TB-Dense, demonstrate that CTRL-PG significantly outperforms baseline methodsfor temporal relation extraction.
@inproceedings{zhou2021clinical, author = {Zhou, Yichao and Yan, Yu and Han, Rujun and Caufield, J. Harry and Chang, Kai-Wei and Sun, Yizhou and Ping, Peipei and Wang, Wei}, title = {Clinical Temporal Relation Extraction with Probabilistic Soft Logic Regularization and Global Inference}, booktitle = {AAAI}, year = {2021} } -
PolicyQA: A Reading Comprehension Dataset for Privacy Policies
Wasi Ahmad, Jianfeng Chi, Yuan Tian, and Kai-Wei Chang, in EMNLP-Finding (short), 2020.
Full Text Code Abstract BibTeX DetailsDetailsPrivacy policy documents are long and verbose. A question answering (QA) system can assist users in finding the information that is relevant and important to them. Prior studies in this domain frame the QA task as retrieving the most relevant text segment or a list of sentences from the policy document given a question. On the contrary, we argue that providing users with a short text span from policy documents reduces the burden of searching the target information from a lengthy text segment. In this paper, we present PolicyQA, a dataset that contains 25,017 reading comprehension style examples curated from an existing corpus of 115 website privacy policies. PolicyQA provides 714 human-annotated questions written for a wide range of privacy practices. We evaluate two existing neural QA models and perform rigorous analysis to reveal the advantages and challenges offered by PolicyQA.
@inproceedings{ahmad2020policyqa, author = {Ahmad, Wasi and Chi, Jianfeng and Tian, Yuan and Chang, Kai-Wei}, title = {PolicyQA: A Reading Comprehension Dataset for Privacy Policies}, booktitle = {EMNLP-Finding (short)}, year = {2020} } -
GPT-GNN: Generative Pre-Training of Graph Neural Networks
Ziniu Hu, Yuxiao Dong, Kuansan Wang, Kai-Wei Chang, and Yizhou Sun, in KDD, 2020.
Full Text Video Code Abstract BibTeX Details Top-10 cited paper at KDD 20DetailsGraph neural networks (GNNs) have been demonstrated to besuccessful in modeling graph-structured data. However, training GNNs requires abundant task-specific labeled data, which is often arduously expensive to obtain. One effective way to reduce labeling effort is to pre-train an expressive GNN model on unlabelled data with self-supervision and then transfer the learned knowledge to downstream models. In this paper, we present the GPT-GNN’s framework to initialize GNNs by generative pre-training. GPT-GNN introduces a self-supervised attributed graph generation task to pre-train a GNN,which allows the GNN to capture the intrinsic structural and semantic properties of the graph. We factorize the likelihood of graph generation into two components: 1) attribute generation, and 2) edgegeneration. By modeling both components, GPT-GNN captures the inherent dependency between node attributes and graph structure during the generative process. Comprehensive experiments on thebillion-scale academic graph and Amazon recommendation data demonstrate that GPT-GNN significantly outperforms state-of-the-art base GNN models without pre-training by up to 9.1% across different downstream tasks.
@inproceedings{hu2020gptgnn, author = {Hu, Ziniu and Dong, Yuxiao and Wang, Kuansan and Chang, Kai-Wei and Sun, Yizhou}, title = {GPT-GNN: Generative Pre-Training of Graph Neural Networks}, booktitle = {KDD}, slide_url = {https://acbull.github.io/pdf/gpt.pptx}, year = {2020} } -
SentiBERT: A Transferable Transformer-Based Architecture for Compositional Sentiment Semantics
Da Yin, Tao Meng, and Kai-Wei Chang, in ACL, 2020.
Full Text Slides Video Code Abstract BibTeX DetailsDetailsWe propose SentiBERT, a variant of BERT that effectively captures compositional sentiment semantics. The model incorporates contextualized representation with binary constituency parse tree to capture semantic composition. Comprehensive experiments demonstrate that SentiBERT achieves competitive performance on phrase-level sentiment classification. We further demonstrate that the sentiment composition learned from the phrase-level annotations on SST can be transferred to other sentiment analysis tasks as well as related tasks, such as emotion classification tasks. Moreover, we conduct ablation studies and design visualization methods to understand SentiBERT. We show that SentiBERT is better than baseline approaches in capturing negation and the contrastive relation and model the compositional sentiment semantics.
@inproceedings{yin2020sentibert, author = {Yin, Da and Meng, Tao and Chang, Kai-Wei}, title = {SentiBERT: A Transferable Transformer-Based Architecture for Compositional Sentiment Semantics}, booktitle = {ACL}, year = {2020}, presentation_id = {https://virtual.acl2020.org/paper_main.341.html} } -
Building Language Models for Text with Named Entities
Md Rizwan Parvez, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang, in ACL, 2018.
Full Text Poster Code Abstract BibTeX DetailsDetailsText in many domains involves a significant amount of named entities. Predicting the entity names is often challenging for a language model as they appear less frequent on the training corpus. In this paper, we propose a novel and effective approach to building a language model which can learn the entity names by leveraging their entity type information. We also introduce two benchmark datasets based on recipes and Java programming codes, on which we evaluate the proposed model. Experimental results show that our model achieves 52.2% better perplexity in recipe generation and 40.3% on code generation than state-of-the-art language models.
@inproceedings{parvez2018building, author = {Parvez, Md Rizwan and Chakraborty, Saikat and Ray, Baishakhi and Chang, Kai-Wei}, title = {Building Language Models for Text with Named Entities}, booktitle = {ACL}, year = {2018} } -
Learning from Explicit and Implicit Supervision Jointly For Algebra Word Problems
Shyam Upadhyay, Ming-Wei Chang, Kai-Wei Chang, and Wen-tau Yih, in EMNLP, 2016.
Full Text Abstract BibTeX DetailsDetailsAutomatically solving algebra word problems has raised considerable interest recently. Existing state-of-the-art approaches mainly rely on learning from human annotated equations. In this paper, we demonstrate that it is possible to efficiently mine algebra problems and their numerical solutions with little to no manual effort. To leverage the mined dataset, we propose a novel structured-output learning algorithm that aims to learn from both explicit (e.g., equations) and implicit (e.g., solutions) supervision signals jointly. Enabled by this new algorithm, our model gains 4.6% absolute improvement in accuracy on the ALG-514 benchmark compared to the one without using implicit supervision. The final model also outperforms the current state-of-the-art approach by 3%. Dataset
@inproceedings{BCWS16, author = {Upadhyay, Shyam and Chang, Ming-Wei and Chang, Kai-Wei and Yih, Wen-tau}, title = {Learning from Explicit and Implicit Supervision Jointly For Algebra Word Problems}, booktitle = {EMNLP}, year = {2016} }
-