Debiasing Gender in Natural Language Processing: Literature Review
Tony Sun, Andrew Gaut, Shirlyn Tang, Yuxin Huang, Mai ElSherief, Jieyu Zhao, Diba Mirza, Kai-Wei Chang, and William Yang Wang, in ACL, 2019.
SlidesDownload the full text
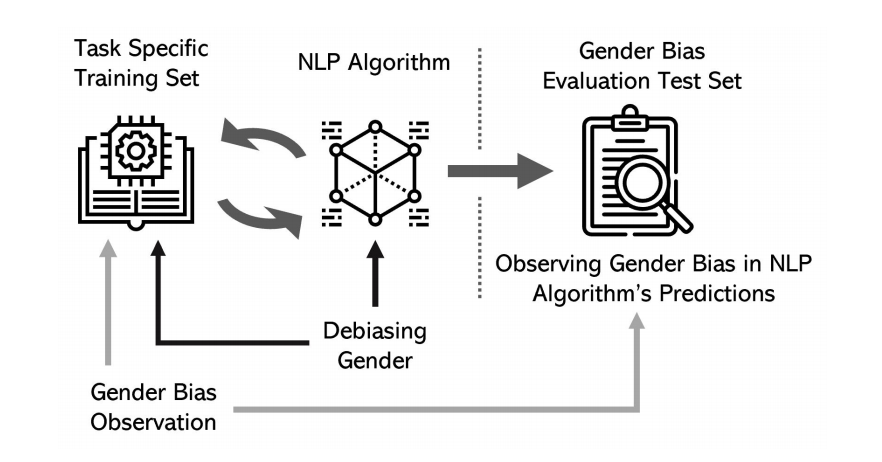
Abstract
As Natural Language Processing (NLP) and Machine Learning (ML) tools rise in popularity, it becomes increasingly vital to recognize the role they play in shaping societal biases and stereotypes. Although NLP models have shown success in modeling various applications, they propagate and may even amplify gender bias found in text corpora. While the study of bias in artificial intelligence is not new, methods to mitigate gender bias in NLP are relatively nascent. In this paper, we review contemporary studies on recognizing and mitigating gender bias in NLP. We discuss gender bias based on four forms of representation bias and analyze methods recognizing gender bias. Furthermore, we discuss the advantages and drawbacks of existing gender debiasing methods. Finally, we discuss future studies for recognizing and mitigating gender bias in NLP.
Excited to share our #acl2019nlp paper Mitigating Gender Bias in Natural Language Processing: Literature Review https://t.co/1gHusYNgCf Joint work by T. Sun, A. Gaut, S. Tang, Y. Huang, @mai_elsherief @jieyuzhao11 D.Mirza, E. Belding @kaiwei_chang #NLProc Check it out!
— William Wang (@WilliamWangNLP) June 24, 2019
Bib Entry
@inproceedings{sun2019debiasing,
author = {Sun, Tony and Gaut, Andrew and Tang, Shirlyn and Huang, Yuxin and ElSherief, Mai and Zhao, Jieyu and Mirza, Diba and Chang, Kai-Wei and Wang, William Yang},
title = {Debiasing Gender in Natural Language Processing: Literature Review},
booktitle = {ACL},
vimeo_id = {384482151},
year = {2019}
}
Related Publications
BOLD: Dataset and metrics for measuring biases in open-ended language generation
Jwala Dhamala, Tony Sun, Varun Kumar, Satyapriya Krishna, Yada Pruksachatkun, Kai-Wei Chang, and Rahul Gupta, in FAccT, 2021.
Full Text Abstract BibTeX DetailsDetailsRecent advances in deep learning techniques have enabled machines to generate cohesive open-ended text when prompted with a sequence of words as context. While these models now empower many downstream applications from conversation bots to automatic storytelling, they have been shown to generate texts that exhibit social biases. To systematically study and benchmark social biases in open-ended language generation, we introduce the Bias in Open-Ended Language Generation Dataset (BOLD), a large-scale dataset that consists of 23,679 English text generation prompts for bias benchmarking across five domains: profession, gender, race, religion, and political ideology. We also propose new automated metrics for toxicity, psycholinguistic norms, and text gender polarity to measure social biases in open-ended text generation from multiple angles. An examination of text generated from three popular language models reveals that the majority of these models exhibit a larger social bias than human-written Wikipedia text across all domains. With these results we highlight the need to benchmark biases in open-ended language generation and caution users of language generation models on downstream tasks to be cognizant of these embedded prejudices.
@inproceedings{Dhamala2021bold, author = {Dhamala, Jwala and Sun, Tony and Kumar, Varun and Krishna, Satyapriya and Pruksachatkun, Yada and Chang, Kai-Wei and Gupta, Rahul}, title = {BOLD: Dataset and metrics for measuring biases in open-ended language generation}, booktitle = {FAccT}, year = {2021} }LOGAN: Local Group Bias Detection by Clustering
Jieyu Zhao and Kai-Wei Chang, in EMNLP (short), 2020.
Full Text Code Abstract BibTeX DetailsDetailsMachine learning techniques have been widely used in natural language processing (NLP). However, as revealed by many recent studies, machine learning models often inherit and amplify the societal biases in data. Various metrics have been proposed to quantify biases in model predictions. In particular, several of them evaluate disparity in model performance between protected groups and advantaged groups in the test corpus. However, we argue that evaluating bias at the corpus level is not enough for understanding how biases are embedded in a model. In fact, a model with similar aggregated performance between different groups on the entire data may behave differently on instances in a local region. To analyze and detect such local bias, we propose LOGAN, a new bias detection technique based on clustering. Experiments on toxicity classification and object classification tasks show that LOGAN identifies bias in a local region and allows us to better analyze the biases in model predictions.
@inproceedings{zhao2020logan, author = {Zhao, Jieyu and Chang, Kai-Wei}, title = {LOGAN: Local Group Bias Detection by Clustering}, booktitle = {EMNLP (short)}, presentation_id = {https://virtual.2020.emnlp.org/paper_main.2886.html}, year = {2020} }Towards Controllable Biases in Language Generation
Emily Sheng, Kai-Wei Chang, Premkumar Natarajan, and Nanyun Peng, in EMNLP-Finding, 2020.
Full Text Code Abstract BibTeX DetailsDetailsWe present a general approach towards controllable societal biases in natural language generation (NLG). Building upon the idea of adversarial triggers, we develop a method to induce societal biases in generated text when input prompts contain mentions of specific demographic groups. We then analyze two scenarios: 1) inducing negative biases for one demographic and positive biases for another demographic, and 2) equalizing biases between demographics. The former scenario enables us to detect the types of biases present in the model. Specifically, we show the effectiveness of our approach at facilitating bias analysis by finding topics that correspond to demographic inequalities in generated text and comparing the relative effectiveness of inducing biases for different demographics. The second scenario is useful for mitigating biases in downstream applications such as dialogue generation. In our experiments, the mitigation technique proves to be effective at equalizing the amount of biases across demographics while simultaneously generating less negatively biased text overall.
@inproceedings{sheng2020towards, title = {Towards Controllable Biases in Language Generation}, author = {Sheng, Emily and Chang, Kai-Wei and Natarajan, Premkumar and Peng, Nanyun}, booktitle = {EMNLP-Finding}, year = {2020} }Towards Understanding Gender Bias in Relation Extraction
Andrew Gaut, Tony Sun, Shirlyn Tang, Yuxin Huang, Jing Qian, Mai ElSherief, Jieyu Zhao, Diba Mirza, Elizabeth Belding, Kai-Wei Chang, and William Yang Wang, in ACL, 2020.
Full Text Abstract BibTeX DetailsDetailsRecent developments in Neural Relation Extraction (NRE) have made significant strides towards automated knowledge base construction. While much attention has been dedicated towards improvements in accuracy, there have been no attempts in the literature to evaluate social biases exhibited in NRE systems. In this paper, we create WikiGenderBias, a distantly supervised dataset composed of over 45,000 sentences including a 10% human annotated test set for the purpose of analyzing gender bias in relation extraction systems. We find that when extracting spouse and hypernym (i.e., occupation) relations, an NRE system performs differently when the gender of the target entity is different. However, such disparity does not appear when extracting relations such as birth date or birth place. We also analyze two existing bias mitigation techniques, word embedding debiasing and data augmentation. Unfortunately, due to NRE models relying heavily on surface level cues, we find that existing bias mitigation approaches have a negative effect on NRE. Our analysis lays groundwork for future quantifying and mitigating bias in relation extraction.
@inproceedings{gaut2020towards, author = {Gaut, Andrew and Sun, Tony and Tang, Shirlyn and Huang, Yuxin and Qian, Jing and ElSherief, Mai and Zhao, Jieyu and Mirza, Diba and Belding, Elizabeth and Chang, Kai-Wei and Wang, William Yang}, title = {Towards Understanding Gender Bias in Relation Extraction}, booktitle = {ACL}, year = {2020}, presentation_id = {https://virtual.acl2020.org/paper_main.265.html} }Mitigating Gender Bias Amplification in Distribution by Posterior Regularization
Shengyu Jia, Tao Meng, Jieyu Zhao, and Kai-Wei Chang, in ACL (short), 2020.
Full Text Slides Video Code Abstract BibTeX DetailsDetailsAdvanced machine learning techniques have boosted the performance of natural language processing. Nevertheless, recent studies, e.g., Zhao et al. (2017) show that these techniques inadvertently capture the societal bias hiddenin the corpus and further amplify it. However,their analysis is conducted only on models’ top predictions. In this paper, we investigate thegender bias amplification issue from the distribution perspective and demonstrate that thebias is amplified in the view of predicted probability distribution over labels. We further propose a bias mitigation approach based on posterior regularization. With little performance loss, our method can almost remove the bias amplification in the distribution. Our study sheds the light on understanding the bias amplification.
@inproceedings{jia2020mitigating, author = {Jia, Shengyu and Meng, Tao and Zhao, Jieyu and Chang, Kai-Wei}, title = {Mitigating Gender Bias Amplification in Distribution by Posterior Regularization}, booktitle = {ACL (short)}, year = {2020}, presentation_id = {https://virtual.acl2020.org/paper_main.264.html} }The Woman Worked as a Babysitter: On Biases in Language Generation
Emily Sheng, Kai-Wei Chang, Premkumar Natarajan, and Nanyun Peng, in EMNLP (short), 2019.
Full Text Slides Video Code Abstract BibTeX DetailsDetailsWe present a systematic study of biases in natural language generation (NLG) by analyzing text generated from prompts that contain mentions of different demographic groups. In this work, we introduce the notion of the regard towards a demographic, use the varying levels of regard towards different demographics as a defining metric for bias in NLG, and analyze the extent to which sentiment scores are a relevant proxy metric for regard. To this end, we collect strategically-generated text from language models and manually annotate the text with both sentiment and regard scores. Additionally, we build an automatic regard classifier through transfer learning, so that we can analyze biases in unseen text. Together, these methods reveal the extent of the biased nature of language model generations. Our analysis provides a study of biases in NLG, bias metrics and correlated human judgments, and empirical evidence on the usefulness of our annotated dataset.
@inproceedings{sheng2019woman, author = {Sheng, Emily and Chang, Kai-Wei and Natarajan, Premkumar and Peng, Nanyun}, title = {The Woman Worked as a Babysitter: On Biases in Language Generation}, booktitle = {EMNLP (short)}, vimeo_id = {426366363}, year = {2019} }Debiasing Gender in Natural Language Processing: Literature Review
Tony Sun, Andrew Gaut, Shirlyn Tang, Yuxin Huang, Mai ElSherief, Jieyu Zhao, Diba Mirza, Kai-Wei Chang, and William Yang Wang, in ACL, 2019.
Full Text Slides Video Abstract BibTeX DetailsDetailsAs Natural Language Processing (NLP) and Machine Learning (ML) tools rise in popularity, it becomes increasingly vital to recognize the role they play in shaping societal biases and stereotypes. Although NLP models have shown success in modeling various applications, they propagate and may even amplify gender bias found in text corpora. While the study of bias in artificial intelligence is not new, methods to mitigate gender bias in NLP are relatively nascent. In this paper, we review contemporary studies on recognizing and mitigating gender bias in NLP. We discuss gender bias based on four forms of representation bias and analyze methods recognizing gender bias. Furthermore, we discuss the advantages and drawbacks of existing gender debiasing methods. Finally, we discuss future studies for recognizing and mitigating gender bias in NLP.
@inproceedings{sun2019debiasing, author = {Sun, Tony and Gaut, Andrew and Tang, Shirlyn and Huang, Yuxin and ElSherief, Mai and Zhao, Jieyu and Mirza, Diba and Chang, Kai-Wei and Wang, William Yang}, title = {Debiasing Gender in Natural Language Processing: Literature Review}, booktitle = {ACL}, vimeo_id = {384482151}, year = {2019} }Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods
Jieyu Zhao, Tianlu Wang, Mark Yatskar, Vicente Ordonez, and Kai-Wei Chang, in NAACL (short), 2018.
Full Text Poster Code Abstract BibTeX DetailsDetailsIn this paper, we introduce a new benchmark for co-reference resolution focused on gender bias, WinoBias. Our corpus contains Winograd-schema style sentences with entities corresponding to people referred by their occupation (e.g. the nurse, the doctor, the carpenter). We demonstrate that a rule-based, a feature-rich, and a neural coreference system all link gendered pronouns to pro-stereotypical entities with higher accuracy than anti-stereotypical entities, by an average difference of 21.1 in F1 score. Finally, we demonstrate a data-augmentation approach that, in combination with existing word-embedding debiasing techniques, removes the bias demonstrated by these systems in WinoBias without significantly affecting their performance on existing datasets.
@inproceedings{zhao2018gender, author = {Zhao, Jieyu and Wang, Tianlu and Yatskar, Mark and Ordonez, Vicente and Chang, Kai-Wei}, title = {Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods}, booktitle = {NAACL (short)}, press_url = {https://www.stitcher.com/podcast/matt-gardner/nlp-highlights/e/55861936}, year = {2018} }Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints
Jieyu Zhao, Tianlu Wang, Mark Yatskar, Vicente Ordonez, and Kai-Wei Chang, in EMNLP, 2017.
Full Text Slides Code Abstract BibTeX Details EMNLP 2017 Best Long Paper AwardDetailsLanguage is increasingly being used to define rich visual recognition problems with supporting image collections sourced from the web. Structured prediction models are used in these tasks to take advantage of correlations between co-occuring labels and visual input but risk inadvertently encoding social biases found in web corpora. In this work, we study data and models associated with multilabel object classification and visual semantic role labeling. We find that (a) datasets for these tasks contain significant gender bias and (b) models trained on these datasets further amplify existing bias. For example, the activity cooking is over 33% more likely to involve females than males in a training set, but a trained model amplifies the disparity to 68% at test time. We propose to inject corpus-level constraints for calibrating existing structured prediction models and design an algorithm based on Lagrangian relaxation for the resulting inference problems. Our method results in no performance loss for the underlying recognition task but decreases the magnitude of bias amplification by 33.3% and 44.9% for multilabel classification and visual semantic role labeling, respectively.
@inproceedings{zhao2017men, author = {Zhao, Jieyu and Wang, Tianlu and Yatskar, Mark and Ordonez, Vicente and Chang, Kai-Wei}, title = {Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints}, booktitle = {EMNLP}, year = {2017} }