An Integer Linear Programming Framework for Mining Constraints from Data
Tao Meng and Kai-Wei Chang, in ICML, 2021.
CodeDownload the full text
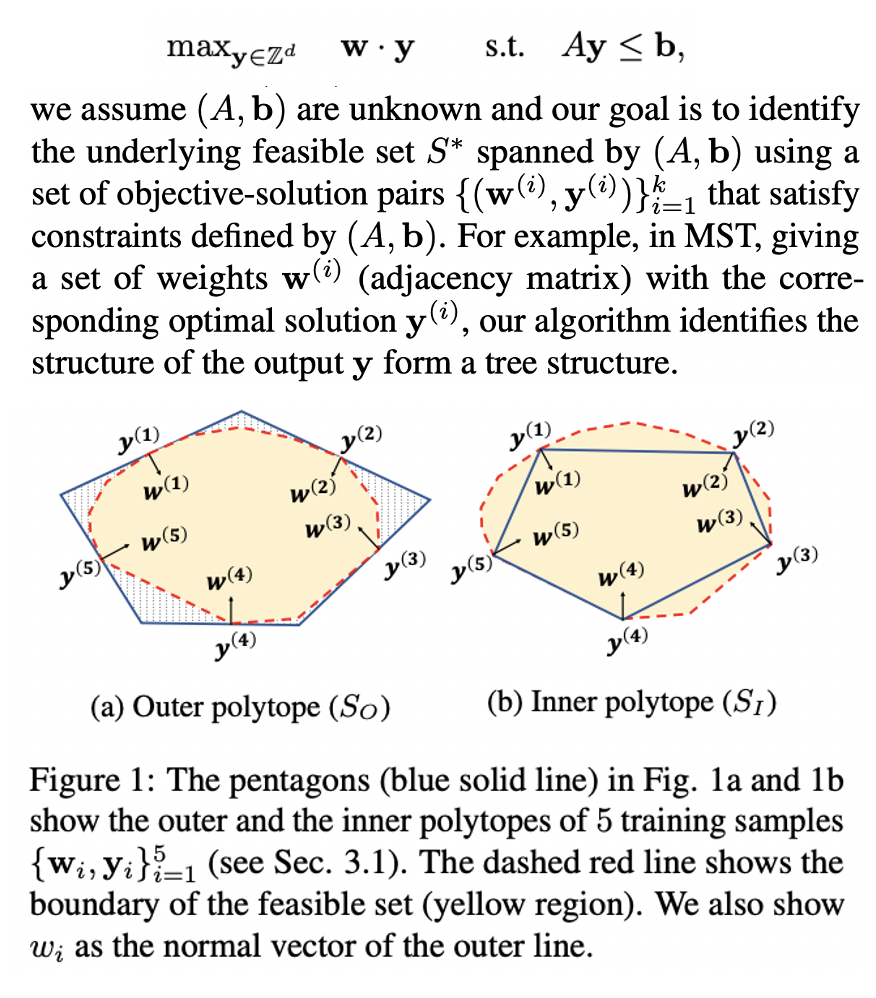
Abstract
Various structured output prediction problems (e.g., sequential tagging) involve constraints over the output space. By identifying these constraints, we can filter out infeasible solutions and build an accountable model. To this end, we present a general integer linear programming (ILP) framework for mining constraints from data. We model the inference of structured output prediction as an ILP problem. Then, given the coefficients of the objective function and the corresponding solution, we mine the underlying constraints by estimating the outer and inner polytopes of the feasible set. We verify the proposed constraint mining algorithm in various synthetic and real-world applications and demonstrate that the proposed approach successfully identifies the feasible set at scale. In particular, we show that our approach can learn to solve 9x9 Sudoku puzzles and minimal spanning tree problems from examples without providing the underlying rules. We also demonstrate results on hierarchical multi-label classification and conduct a theoretical analysis on how close the mined constraints are from the ground truth.
Can a model learn problem structure/constraints from data? E.g., given pairs of adjacent matrix and corresponding minimal spanning tree, can a model learn to solve MST? Check out our #ICML2021 paper on constraint mining with ILP https://t.co/jEPCWSrOQv w/@kaiwei_chang 1/4
— Tao Meng (@TaoMeng10) June 17, 2021
Bib Entry
@inproceedings{meng2020integer,
author = {Meng, Tao and Chang, Kai-Wei},
title = {An Integer Linear Programming Framework for Mining Constraints from Data},
booktitle = {ICML},
year = {2021}
}
Related Publications
- Relation-Guided Pre-Training for Open-Domain Question Answering, EMNLP-Finding, 2021
- Generating Syntactically Controlled Paraphrases without Using Annotated Parallel Pairs, EACL, 2021
- Clinical Temporal Relation Extraction with Probabilistic Soft Logic Regularization and Global Inference, AAAI, 2021
- PolicyQA: A Reading Comprehension Dataset for Privacy Policies, EMNLP-Finding (short), 2020
- GPT-GNN: Generative Pre-Training of Graph Neural Networks, KDD, 2020
- SentiBERT: A Transferable Transformer-Based Architecture for Compositional Sentiment Semantics, ACL, 2020
- Building Language Models for Text with Named Entities, ACL, 2018
- Learning from Explicit and Implicit Supervision Jointly For Algebra Word Problems, EMNLP, 2016