Building Language Models for Text with Named Entities
Md Rizwan Parvez, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang, in ACL, 2018.
Poster CodeDownload the full text
Abstract
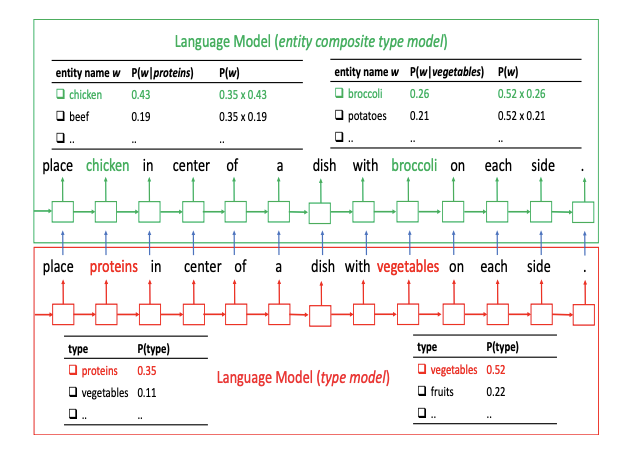
Text in many domains involves a significant amount of named entities. Predicting the entity names is often challenging for a language model as they appear less frequent on the training corpus. In this paper, we propose a novel and effective approach to building a language model which can learn the entity names by leveraging their entity type information. We also introduce two benchmark datasets based on recipes and Java programming codes, on which we evaluate the proposed model. Experimental results show that our model achieves 52.2% better perplexity in recipe generation and 40.3% on code generation than state-of-the-art language models.
Here's a #PaperSummary I wrote last week: #ACL2018 paper on "Building Language Models for Text with Named Entities", by Md Rizwan Parvez, Saikat Chakraborty, Baishakhi Ray, @kaiwei_chang https://t.co/Kpmm3kn9fG #NLProc
— Sameer Singh (@sameer_) October 23, 2018
Bib Entry
@inproceedings{parvez2018building,
author = {Parvez, Md Rizwan and Chakraborty, Saikat and Ray, Baishakhi and Chang, Kai-Wei},
title = {Building Language Models for Text with Named Entities},
booktitle = {ACL},
year = {2018}
}
Related Publications
- Relation-Guided Pre-Training for Open-Domain Question Answering, EMNLP-Finding, 2021
- An Integer Linear Programming Framework for Mining Constraints from Data, ICML, 2021
- Generating Syntactically Controlled Paraphrases without Using Annotated Parallel Pairs, EACL, 2021
- Clinical Temporal Relation Extraction with Probabilistic Soft Logic Regularization and Global Inference, AAAI, 2021
- PolicyQA: A Reading Comprehension Dataset for Privacy Policies, EMNLP-Finding (short), 2020
- GPT-GNN: Generative Pre-Training of Graph Neural Networks, KDD, 2020
- SentiBERT: A Transferable Transformer-Based Architecture for Compositional Sentiment Semantics, ACL, 2020
- Learning from Explicit and Implicit Supervision Jointly For Algebra Word Problems, EMNLP, 2016