At UCLA-NLP, our mission is to develop reliable, fair, accountable, robust natural language understanding and generation technology to benefit everyone.
Please see our recent papers at
In the following, we will highlight our reseach papers at NAACL 2021 on the following topics:
- Fairness and Social NLP
- Language Generation
- (Multi-Modal) Represenation Learning
- Model Evaluation and Interpretation
- Event Extraction
Fairness and Social NLP
"Nice Try, Kiddo": Investigating Ad Hominems in Dialogue Responses
Emily Sheng, Kai-Wei Chang, Prem Natarajan, and Nanyun Peng, in NAACL, 2021.
QA Sessions: 3A-ORAL: DIALOGUE AND INTERACTIVE SYSTEMS Paper link in the virtual conferenceFull Text Code BibTeX DetailsDetails
Ad hominem attacks are those that target some feature of a person’s character instead of the position the person is maintaining. These attacks are harmful because they propagate implicit biases and diminish a person’s credibility. Since dialogue systems respond directly to user input, it is important to study ad hominems in dialogue responses. To this end, we propose categories of ad hominems, compose an annotated dataset, and build a classifier to analyze human and dialogue system responses to English Twitter posts. We specifically compare responses to Twitter topics about marginalized communities (#BlackLivesMatter, #MeToo) versus other topics (#Vegan, #WFH), because the abusive language of ad hominems could further amplify the skew of power away from marginalized populations. Furthermore, we propose a constrained decoding technique that uses salient n-gram similarity as a soft constraint for top-k sampling to reduce the amount of ad hominems generated. Our results indicate that 1) responses from both humans and DialoGPT contain more ad hominems for discussions around marginalized communities, 2) different quantities of ad hominems in the training data can influence the likelihood of generating ad hominems, and 3) we can use constrained decoding techniques to reduce ad hominems in generated dialogue responses.
@inproceedings{sheng2021nice, title = {"Nice Try, Kiddo": Investigating Ad Hominems in Dialogue Responses}, booktitle = {NAACL}, author = {Sheng, Emily and Chang, Kai-Wei and Natarajan, Prem and Peng, Nanyun}, presentation_id = {https://underline.io/events/122/sessions/4137/lecture/19854-%27nice-try,-kiddo%27-investigating-ad-hominems-in-dialogue-responses}, year = {2021} }Really excited about 👉 “Nice Try, Kiddo”: Investigating Ad Hominems in Dialogue Responses (https://t.co/A9aBtzyXmm) w/@kaiwei_chang @natarajan_prem @VioletNPeng #NAACL2021
— Emily Sheng (@ewsheng) April 14, 2021
We find that there are more ad hominem responses in discussions about marginalized communities…Related Publications
- A Meta-Evaluation of Measuring LLM Misgendering, COLM 2025, 2025
- White Men Lead, Black Women Help? Benchmarking Language Agency Social Biases in LLMs, ACL, 2025
- Controllable Generation via Locally Constrained Resampling, ICLR, 2025
- On Localizing and Deleting Toxic Memories in Large Language Models, NAACL-Finding, 2025
- Attribute Controlled Fine-tuning for Large Language Models: A Case Study on Detoxification, EMNLP-Finding, 2024
- Mitigating Bias for Question Answering Models by Tracking Bias Influence, NAACL, 2024
- Are you talking to ['xem'] or ['x', 'em']? On Tokenization and Addressing Misgendering in LLMs with Pronoun Tokenization Parity, NAACL-Findings, 2024
- Are Personalized Stochastic Parrots More Dangerous? Evaluating Persona Biases in Dialogue Systems, EMNLP-Finding, 2023
- Kelly is a Warm Person, Joseph is a Role Model: Gender Biases in LLM-Generated Reference Letters, EMNLP-Findings, 2023
- The Tail Wagging the Dog: Dataset Construction Biases of Social Bias Benchmarks, ACL (short), 2023
- Factoring the Matrix of Domination: A Critical Review and Reimagination of Intersectionality in AI Fairness, AIES, 2023
- How well can Text-to-Image Generative Models understand Ethical Natural Language Interventions?, EMNLP (Short), 2022
- On the Intrinsic and Extrinsic Fairness Evaluation Metrics for Contextualized Language Representations, ACL (short), 2022
- Societal Biases in Language Generation: Progress and Challenges, ACL, 2021
- BOLD: Dataset and metrics for measuring biases in open-ended language generation, FAccT, 2021
- Towards Controllable Biases in Language Generation, EMNLP-Finding, 2020
- The Woman Worked as a Babysitter: On Biases in Language Generation, EMNLP (short), 2019
Adapting Coreference Resolution for Processing Violent Death Narratives
Ankith Uppunda, Susan Cochran, Jacob Foster, Alina Arseniev-Koehler, Vickie Mays, and Kai-Wei Chang, in NAACL (short), 2021.
QA Sessions: 13A-Oral: NLP Applications Paper link in the virtual conferenceFull Text BibTeX DetailsDetails
Coreference resolution is an important component in analyzing narrative text from administrative data (e.g., clinical or police sources). However, existing coreference models trained on general language corpora suffer from poor transferability due to domain gaps, especially when they are applied to gender-inclusive data with lesbian, gay, bisexual, and transgender (LGBT) individuals. In this paper, we analyzed the challenges of coreference resolution in an exemplary form of administrative text written in English: violent death narratives from the USA’s Centers for Disease Control’s (CDC) National Violent Death Reporting System. We developed a set of data augmentation rules to improve model performance using a probabilistic data programming framework. Experiments on narratives from an administrative database, as well as existing gender-inclusive coreference datasets, demonstrate the effectiveness of data augmentation in training coreference models that can better handle text data about LGBT individuals.
@inproceedings{uppunda2021adapting, title = {Adapting Coreference Resolution for Processing Violent Death Narratives}, author = {Uppunda, Ankith and Cochran, Susan and Foster, Jacob and Arseniev-Koehler, Alina and Mays, Vickie and Chang, Kai-Wei}, booktitle = {NAACL (short)}, presentation_id = {https://underline.io/events/122/sessions/4249/lecture/19662-adapting-coreference-resolution-for-processing-violent-death-narratives}, year = {2021} }Our #NAACL2021 paper demonstrates the challenges when applying NLP in analyzing narratives from USA’s CDC National Violent Death Reporting System. We showed that Coref suffers from poor transferability due to domain gaps, especially in narratives involved LGBT individuals 1/n pic.twitter.com/VNFy26f0CX
— Kai-Wei Chang (@kaiwei_chang) June 5, 2021Identifying Distributional Perspective Differences from Colingual Groups
Yufei Tian, Tuhin Chakrabarty, Fred Morstatter, and Nanyun Peng, in NAACL 2021 Workshop of Social NLP, 2021.
QA Sessions: NINTH INTERNATIONAL WORKSHOP ON NATURAL LANGUAGE PROCESSING FOR SOCIAL MEDIA (SOCIALNLP 2021) Paper link in the virtual conferenceFull Text Code BibTeX DetailsDetailsPerspective differences exist among different cultures or languages. A lack of mutual understanding among different groups about their perspectives on specific values or events may lead to uninformed decisions or biased opinions. Automatically understanding the group perspectives can provide essential background for many downstream applications of natural language processing techniques. In this paper, we study colingual groups and use language corpora as a proxy to identify their distributional perspectives. We present a novel computational approach to learn shared understandings, and benchmark our method by building culturally-aware models for the English, Chinese, and Japanese languages. On a held out set of diverse topics including marriage, corruption, democracy, our model achieves high correlation with human judgements regarding intra-group values and inter-group differences.
@inproceedings{tian2021identifying, title = {Identifying Distributional Perspective Differences from Colingual Groups}, author = {Tian, Yufei and Chakrabarty, Tuhin and Morstatter, Fred and Peng, Nanyun}, booktitle = {NAACL 2021 Workshop of Social NLP}, presentation_id = {https://underline.io/events/122/posters/4298/poster/20429-identifying-distributional-perspectives-from-colingual-groups}, year = {2021} }
Language Generation
Plot-guided Adversarial Example Construction for Evaluating Open-domain Story Generation
Sarik Ghazarian, Zixi Liu, Akash S. M, Ralph Weischedel, Aram Galstyan, and Nanyun Peng, in The 2021 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2021.
QA Sessions: 12D-ORAL: LANGUAGE RESOURCES AND EVALUATION Paper link in the virtual conferenceFull Text Slides Code BibTeX DetailsDetailsWith the recent advances of open-domain story generation models, the lack of reliable automatic evaluation metrics becomes an increasingly imperative issue that hinders the development of such models. A critical bottleneck of obtaining a trustworthy learnable evaluation metric is the lack of high-quality training data for learning classifiers to efficiently distinguish between plausible and implausible machine-generated stories. Previous works relied on heuristically manipulate plausible examples to mimic possible system drawbacks such as repetition, contradiction, or irrelevant content in the text level, which can be unnatural and oversimplify the characteristics of implausible machine-generated stories. We propose to tackle these issues by generating a more comprehensive set of implausible stories using plots, which are structured representations of controllable factors used to generate stories. Since these plots are compact and structured, it is easier to manipulate them to generate text with targeted undesirable properties, while at the same time maintain the naturalness of the generation. To improve the quality of incoherent stories, we further apply the adversarial filtering procedure to select a more nuanced set of implausible texts. We find that the evaluation metrics trained on our generated data result in more reliable automatic assessments that correlate remarkably better with human judgments than other baselines.
@inproceedings{ghazarian2021plot, title = {Plot-guided Adversarial Example Construction for Evaluating Open-domain Story Generation}, author = {Ghazarian, Sarik and Liu, Zixi and M, Akash S and Weischedel, Ralph and Galstyan, Aram and Peng, Nanyun}, booktitle = {The 2021 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL)}, publisher = {Association for Computational Linguistics}, pages = {4334--4344}, presentation_id = {https://underline.io/events/122/sessions/4241/lecture/19650-plot-guided-adversarial-example-construction-for-evaluating-open-domain-story-generation}, year = {2021} }In our first paper in the title "Plot-guided Adversarial Example Construction for Evaluating Open-domain Story Generation", we tried to achieve a more accurate story plausibility evaluator by proposing a more comprehensive set of incoherent stories based on plot manipulations.
— Sarik (@Sarikgha) March 19, 2021MERMAID: Metaphor Generation with Symbolism and Discriminative Decoding
Tuhin Chakrabarty, Xurui Zhang, Smaranda Muresan, and Nanyun Peng, in The 2021 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2021.
QA Sessions: 12C-ORAL: LANGUAGE GENERATION Paper link in the virtual conferenceFull Text Poster Code BibTeX DetailsDetailsGenerating metaphors is a challenging task as it requires a proper understanding of abstract concepts, making connections between unrelated concepts, and deviating from the literal meaning. In this paper, we aim to generate a metaphoric sentence given a literal expression by replacing relevant verbs. Based on a theoretically-grounded connection between metaphors and symbols, we propose a method to automatically construct a parallel corpus by transforming a large number of metaphorical sentences from the Gutenberg Poetry corpus (CITATION) to their literal counterpart using recent advances in masked language modeling coupled with commonsense inference. For the generation task, we incorporate a metaphor discriminator to guide the decoding of a sequence to sequence model fine-tuned on our parallel data to generate high-quality metaphors. Human evaluation on an independent test set of literal statements shows that our best model generates metaphors better than three well-crafted baselines 66% of the time on average. A task-based evaluation shows that human-written poems enhanced with metaphors proposed by our model are preferred 68% of the time compared to poems without metaphors.
@inproceedings{chakrabarty2021mermaid, title = {MERMAID: Metaphor Generation with Symbolism and Discriminative Decoding}, author = {Chakrabarty, Tuhin and Zhang, Xurui and Muresan, Smaranda and Peng, Nanyun}, booktitle = {The 2021 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL)}, presentation_id = {https://underline.io/events/122/sessions/4240/lecture/19642-mermaid-metaphor-generation-with-symbolism-and-discriminative-decoding}, talk_url = {https://underline.io/events/122/sessions/4240/lecture/19642-mermaid-metaphor-generation-with-symbolism-and-discriminative-decoding}, year = {2021} }🔥Metaphors are not to be trifled with🔥 Excited to share #NAACL2021 preprint titled “MERMAID: Metaphor Generation with Symbolism and Discriminative Decoding”https://t.co/gcnvn995vR . Joint work with my figurative NLG constants @VioletNPeng and Smaranda Muresan. #NLProc pic.twitter.com/3mJqlLV6j2
— Tuhin Chakrabarty (@TuhinChakr) March 12, 2021DiSCoL: Toward Engaging Dialogue Systems through Conversational Line Guided Response Generation
Sarik Ghazarian, Zixi Liu, Tuhin Chakrabarty, Xuezhe Ma, Aram Galstyan, and Nanyun Peng, 2021 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), Demonstrations Track, 2021.
QA Sessions: 10F-POSTER: SYSTEM DEMONSTRATIONS Paper link in the virtual conferenceFull Text Code BibTeX DetailsDetailsHaving engaging and informative conversations with users is the utmost goal for open-domain conversational systems. Recent advances in transformer-based language models and their applications to dialogue systems have succeeded to generate fluent and human-like responses. However, they still lack control over the generation process towards producing contentful responses and achieving engaging conversations. To achieve this goal, we present DiSCoL (Dialogue Systems through Coversational Line guided response generation). DiSCoL is an open-domain dialogue system that leverages conversational lines (briefly convlines) as controllable and informative content-planning elements to guide the generation model produce engaging and informative responses. Two primary modules in DiSCoL’s pipeline are conditional generators trained for 1) predicting relevant and informative convlines for dialogue contexts and 2) generating high-quality responses conditioned on the predicted convlines. Users can also change the returned convlines to control the direction of the conversations towards topics that are more interesting for them. Through automatic and human evaluations, we demonstrate the efficiency of the convlines in producing engaging conversations.
@article{ghazarian2021discol, title = {DiSCoL: Toward Engaging Dialogue Systems through Conversational Line Guided Response Generation}, author = {Ghazarian, Sarik and Liu, Zixi and Chakrabarty, Tuhin and Ma, Xuezhe and Galstyan, Aram and Peng, Nanyun}, booktitle = {2021 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), Demonstrations Track}, presentation_id = {https://underline.io/events/122/posters/4227/poster/20579-discol-toward-engaging-dialogue-systems-through-conversational-line-guided-response-generation}, pages = {26–34}, publisher = {Association for Computational Linguistics}, year = {2021} }In our demo system called DiSCoL (https://t.co/32JAfKtvmH), we presented an engaging conversational system that uses conversational lines to guide the response generation. Users also have the control to change the dialog toward their more favorite direction.
— Sarik (@Sarikgha) March 19, 2021
NLP Model Evaluation and Interpretation
Double Perturbation: On the Robustness of Robustness and Counterfactual Bias Evaluation
Chong Zhang, Jieyu Zhao, Huan Zhang, Kai-Wei Chang, and Cho-Jui Hsieh, in NAACL, 2021.
QA Sessions: 11B-ORAL: INTERPRETABILITY AND ANALYSIS OF MODELS FOR NLP Paper link in the virtual conferenceFull Text Code BibTeX DetailsDetails
Robustness and counterfactual bias are usually evaluated on a test dataset. However, are these evaluations robust? If the test dataset is perturbed slightly, will the evaluation results keep the same? In this paper, we propose a "double perturbation" framework to uncover model weaknesses beyond the test dataset. The framework first perturbs the test dataset to construct abundant natural sentences similar to the test data, and then diagnoses the prediction change regarding a single-word substitution. We apply this framework to study two perturbation-based approaches that are used to analyze models’ robustness and counterfactual bias in English. (1) For robustness, we focus on synonym substitutions and identify vulnerable examples where prediction can be altered. Our proposed attack attains high success rates (96.0%-99.8%) in finding vulnerable examples on both original and robustly trained CNNs and Transformers. (2) For counterfactual bias, we focus on substituting demographic tokens (e.g., gender, race) and measure the shift of the expected prediction among constructed sentences. Our method is able to reveal the hidden model biases not directly shown in the test dataset.
@inproceedings{zhang2021double, title = { Double Perturbation: On the Robustness of Robustness and Counterfactual Bias Evaluation}, booktitle = {NAACL}, author = {Zhang, Chong and Zhao, Jieyu and Zhang, Huan and Chang, Kai-Wei and Hsieh, Cho-Jui}, year = {2021}, presentation_id = {https://underline.io/events/122/sessions/4229/lecture/19609-double-perturbation-on-the-robustness-of-robustness-and-counterfactual-bias-evaluation} }Prior studies often test model robustness by applying semantic-invariant perturbation on a given test set. In our #NAACL2021 “Double Perturbation: On the Robustness of Robustness and Counterfactual Bias Evaluation”, we propose a new framework for robustness verification. 1/n pic.twitter.com/h4V1dKhYXL
— Jieyu Zhao (@jieyuzhao11) June 5, 2021Related Publications
- VideoCon: Robust video-language alignment via contrast captions, CVPR, 2024
- CleanCLIP: Mitigating Data Poisoning Attacks in Multimodal Contrastive Learning, ICCV, 2023
- Red Teaming Language Model Detectors with Language Models, TACL, 2023
- ADDMU: Detection of Far-Boundary Adversarial Examples with Data and Model Uncertainty Estimation, EMNLP, 2022
- Investigating Ensemble Methods for Model Robustness Improvement of Text Classifiers, EMNLP-Finding (short), 2022
- Unsupervised Syntactically Controlled Paraphrase Generation with Abstract Meaning Representations, EMNLP-Finding (short), 2022
- Improving the Adversarial Robustness of NLP Models by Information Bottleneck, ACL-Finding, 2022
- Searching for an Effiective Defender: Benchmarking Defense against Adversarial Word Substitution, EMNLP, 2021
- On the Transferability of Adversarial Attacks against Neural Text Classifier, EMNLP, 2021
- Defense against Synonym Substitution-based Adversarial Attacks via Dirichlet Neighborhood Ensemble, ACL, 2021
- Provable, Scalable and Automatic Perturbation Analysis on General Computational Graphs, NeurIPS, 2020
- On the Robustness of Language Encoders against Grammatical Errors, ACL, 2020
- Robustness Verification for Transformers, ICLR, 2020
- Learning to Discriminate Perturbations for Blocking Adversarial Attacks in Text Classification, EMNLP, 2019
- Retrofitting Contextualized Word Embeddings with Paraphrases, EMNLP (short), 2019
- Generating Natural Language Adversarial Examples, EMNLP (short), 2018
Evaluating the Values of Sources in Transfer Learning
Md Rizwan Parvez and Kai-Wei Chang, in NAACL, 2021.
QA Sessions: 14C-ORAL: INTERPRETABILITY AND ANALYSIS OF MODELS FOR NLP Paper link in the virtual conferenceFull Text Code BibTeX DetailsDetails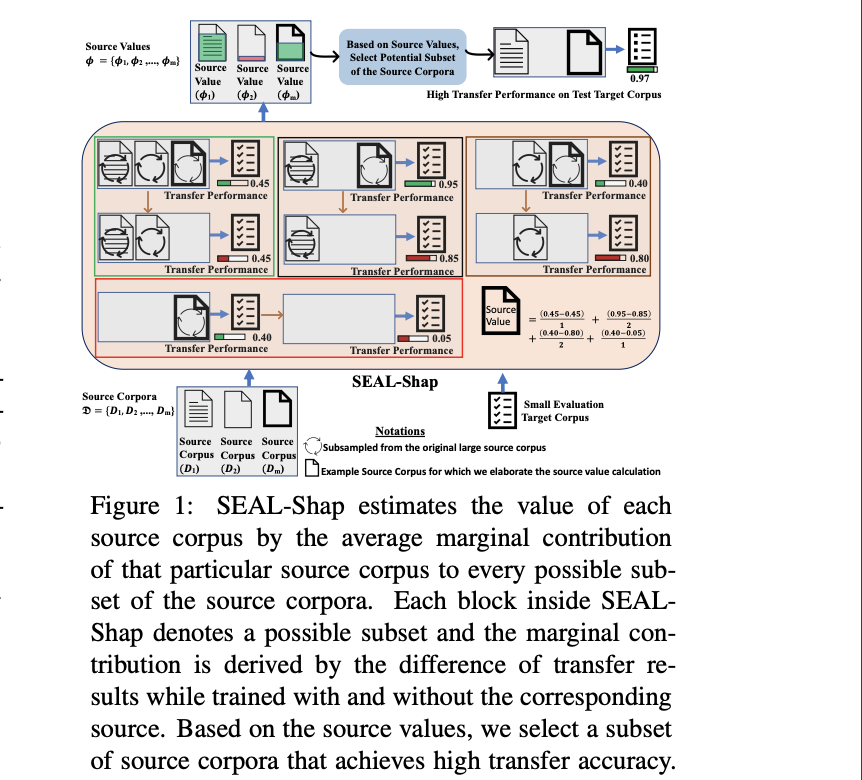
Transfer learning that adapts a model trained on data-rich sources to low-resource targets has been widely applied in natural language processing (NLP). However, when training a transfer model over multiple sources, not every source is equally useful for the target. To better transfer a model, it is essential to understand the values of the sources. In this paper, we develop SEAL-Shap, an efficient source valuation framework for quantifying the usefulness of the sources (e.g., domains/languages) in transfer learning based on the Shapley value method. Experiments and comprehensive analyses on both cross-domain and cross-lingual transfers demonstrate that our framework is not only effective in choosing useful transfer sources but also the source values match the intuitive source-target similarity.
@inproceedings{parvez2021evaluating, title = {Evaluating the Values of Sources in Transfer Learning}, author = {Parvez, Md Rizwan and Chang, Kai-Wei}, booktitle = {NAACL}, presentation_id = {https://underline.io/events/122/sessions/4261/lecture/19707-evaluating-the-values-of-sources-in-transfer-learning}, year = {2021} }When performing transfer learning with multiple sources, one key question is how much info one can leverage from each source. In #NAACL2021 paper, Rizwan Parvez @uclanlp developed SEAL-SHAP, an efficient source valuation framework for quantifying the usefulness of the sources 1/n pic.twitter.com/5qmAG7a1q7
— Kai-Wei Chang (@kaiwei_chang) June 5, 2021Related Publications
- Contextual Label Projection for Cross-Lingual Structured Prediction, NAACL, 2024
- Multilingual Generative Language Models for Zero-Shot Cross-Lingual Event Argument Extraction, ACL, 2022
- Improving Zero-Shot Cross-Lingual Transfer Learning via Robust Training, EMNLP, 2021
- Syntax-augmented Multilingual BERT for Cross-lingual Transfer, ACL, 2021
- GATE: Graph Attention Transformer Encoder for Cross-lingual Relation and Event Extraction, AAAI, 2021
- Cross-Lingual Dependency Parsing by POS-Guided Word Reordering, EMNLP-Finding, 2020
- Cross-lingual Dependency Parsing with Unlabeled Auxiliary Languages, CoNLL, 2019
- Target Language-Aware Constrained Inference for Cross-lingual Dependency Parsing, EMNLP, 2019
- On Difficulties of Cross-Lingual Transfer with Order Differences: A Case Study on Dependency Parsing, NAACL, 2019
(Multi-Modal) Representation Learning
Unified Pre-training for Program Understanding and Generation
Wasi Ahmad, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang, in NAACL, 2021.
QA Sessions: 8A-ORAL: MACHINE LEARNING FOR NLP: LANGUAGE MODELING AND SEQUENCE TO SEQUENCE MODELS Paper link in the virtual conferenceFull Text Code BibTeX Details Top-10 cited paper at NAACL 21DetailsCode summarization nd generation empower conversion between programming language (PL) and natural language (NL), while code translation avails the migration of legacy code from one PL to another. This paper introduces PLBART, a sequence-to-sequence model capable of performing a broad spectrum of program and language understanding and generation tasks. PLBART is pre-trained on an extensive collection of Java and Python functions and associated NL text via denoising autoencoding. Experiments on code summarization in the English language, code generation, and code translation in seven programming languages show that PLBART outperforms or rivals state-of-the-art models. Moreover, experiments on discriminative tasks, e.g., program repair, clone detection, and vulnerable code detection, demonstrate PLBART’s effectiveness in program understanding. Furthermore, analysis reveals that PLBART learns program syntax, style (e.g., identifier naming convention), logical flow (e.g., if block inside an else block is equivalent to else if block) that are crucial to program semantics and thus excels even with limited annotations.
@inproceedings{ahmad2021unified, title = {Unified Pre-training for Program Understanding and Generation}, author = {Ahmad, Wasi and Chakraborty, Saikat and Ray, Baishakhi and Chang, Kai-Wei}, booktitle = {NAACL}, presentation_id = {https://underline.io/events/122/sessions/4197/lecture/20024-unified-pre-training-for-program-understanding-and-generation}, year = {2021} }De-noising pretraining excels for dual modeling of programming language (e.g., source code) + natural language (e.g., code comment). See our new @NAACLHLT paper https://t.co/YrLFIJE1RH. Thanks to awesome collaborations by Wasi Ahmed, Saikat Chakraborty, @kaiwei_chang
— Baishakhi Ray (@baishakhir) March 13, 2021
.Related Publications
- METAL: A Multi-Agent Framework for Chart Generation with Test-Time Scaling, ACL, 2025
- MQT-LLaVA: Matryoshka Query Transformer for Large Vision-Language Models, NeurIPS, 2024
- DACO: Towards Application-Driven and Comprehensive Data Analysis via Code Generation, NeurIPS (Datasets and Benchmarks Track), 2024
- VDebugger: Harnessing Execution Feedback for Debugging Visual Programs, EMNLP-Finding, 2024
- AVATAR: A Parallel Corpus for Java-Python Program Translation, ACL-Finding (short), 2023
- Retrieval Augmented Code Generation and Summarization, EMNLP-Finding, 2021
Unsupervised Vision-and-Language Pre-training Without Parallel Images and Captions
Liunian Harold Li, Haoxuan You, Zhecan Wang, Alireza Zareian, Shih-Fu Chang, and Kai-Wei Chang, in NAACL, 2021.
QA Sessions: 15A-ORAL: LANGUAGE GROUNDING TO VISION, ROBOTICS AND BEYOND Paper link in the virtual conferenceFull Text BibTeX DetailsDetails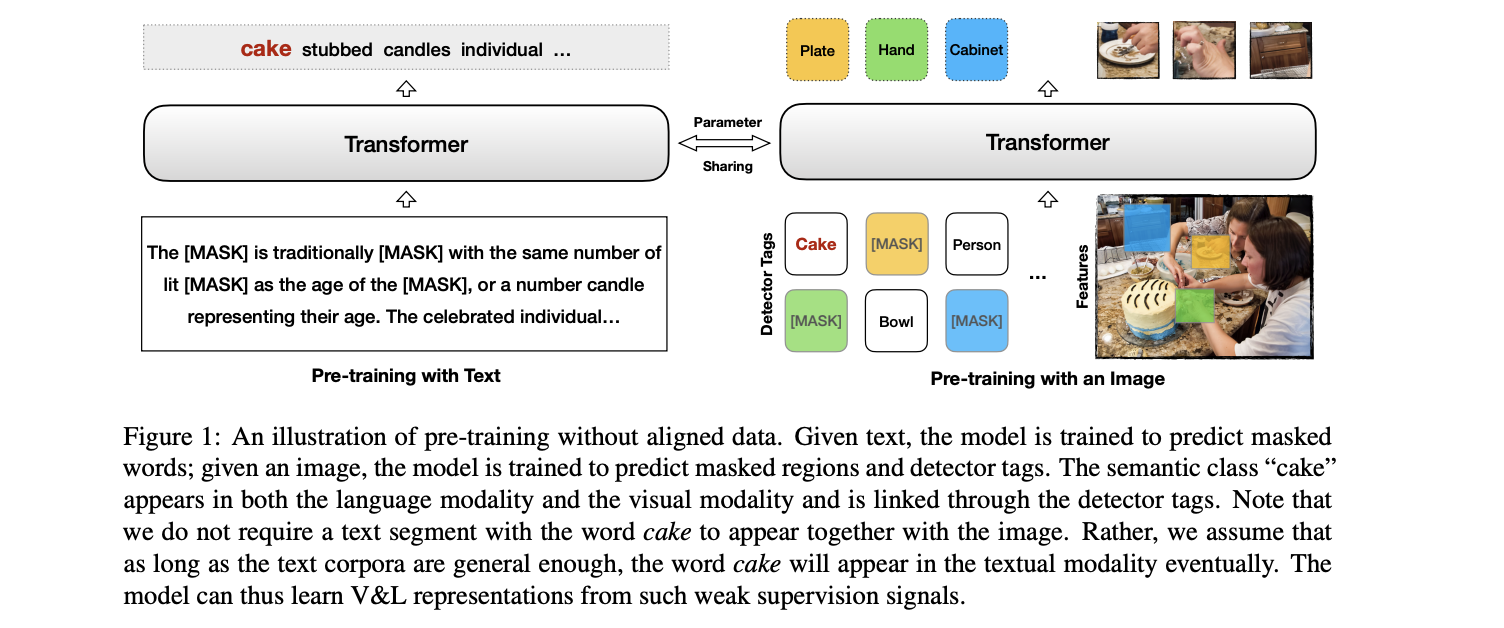
Pre-trained contextual vision-and-language (V&L) models have brought impressive performance improvement on various benchmarks. However, the paired text-image data required for pre-training are hard to collect and scale up. We investigate if a strong V&L representation model can be learned without text-image pairs. We propose Weakly-supervised VisualBERT with the key idea of conducting "mask-and-predict" pre-training on language-only and image-only corpora. Additionally, we introduce the object tags detected by an object recognition model as anchor points to bridge two modalities. Evaluation on four V&L benchmarks shows that Weakly-supervised VisualBERT achieves similar performance with a model pre-trained with paired data. Besides, pre-training on more image-only data further improves a model that already has access to aligned data, suggesting the possibility of utilizing billions of raw images available to enhance V&L models.
@inproceedings{li2021unsupervised, author = {Li, Liunian Harold and You, Haoxuan and Wang, Zhecan and Zareian, Alireza and Chang, Shih-Fu and Chang, Kai-Wei}, title = {Unsupervised Vision-and-Language Pre-training Without Parallel Images and Captions}, booktitle = {NAACL}, presentation_id = {https://underline.io/events/122/sessions/4269/lecture/19725-unsupervised-vision-and-language-pre-training-without-parallel-images-and-captions}, year = {2021} }Excited to share our NAACL paper Unsupervised Vision-and-Language Pre-training Without Parallel Images and Captions! https://t.co/R248NcGH3b
— Liunian Harold Li (@LiLiunian) April 16, 2021
We show that one could pre-train a V&L model on unaligned images and text with competitive performance as models trained on aligned data. pic.twitter.com/7TrKAMxL6aRelated Publications
- Broaden the Vision: Geo-Diverse Visual Commonsense Reasoning, EMNLP, 2021
- What Does BERT with Vision Look At?, ACL (short), 2020
- VisualBERT: A Simple and Performant Baseline for Vision and Language, Arxiv, 2019
Disentangling Semantics and Syntax in Sentence Embeddings with Pre-trained Language Models
James Y. Huang, Kuan-Hao Huang, and Kai-Wei Chang, in NAACL (short), 2021.
QA Sessions: 4C-ORAL: SEMANTICS: SENTENCE-LEVEL SEMANTICS AND TEXTUAL INFERENCE Paper link in the virtual conferenceFull Text Code BibTeX DetailsDetails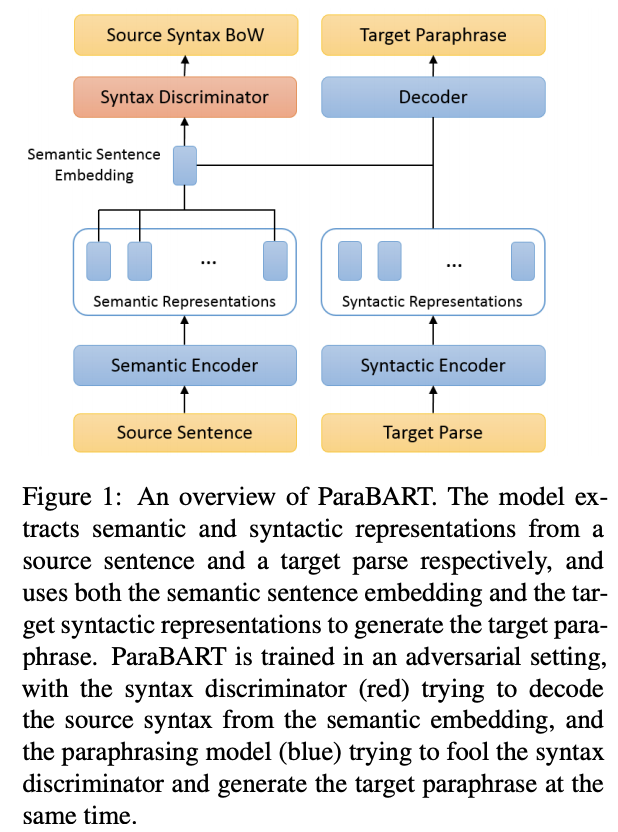
Pre-trained language models have achieved huge success on a wide range of NLP tasks. However, contextual representations from pre-trained models contain entangled semantic and syntactic information, and therefore cannot be directly used to derive useful semantic sentence embeddings for some tasks. Paraphrase pairs offer an effective way of learning the distinction between semantics and syntax, as they naturally share semantics and often vary in syntax. In this work, we present ParaBART, a semantic sentence embedding model that learns to disentangle semantics and syntax in sentence embeddings obtained by pre-trained language models. ParaBART is trained to perform syntax-guided paraphrasing, based on a source sentence that shares semantics with the target paraphrase, and a parse tree that specifies the target syntax. In this way, ParaBART learns disentangled semantic and syntactic representations from their respective inputs with separate encoders. Experiments in English show that ParaBART outperforms state-of-the-art sentence embedding models on unsupervised semantic similarity tasks. Additionally, we show that our approach can effectively remove syntactic information from semantic sentence embeddings, leading to better robustness against syntactic variation on downstream semantic tasks.
@inproceedings{huang2021disentangling, title = {Disentangling Semantics and Syntax in Sentence Embeddings with Pre-trained Language Models}, author = {Huang, James Y. and Huang, Kuan-Hao and Chang, Kai-Wei}, booktitle = {NAACL (short)}, presentation_id = {https://underline.io/events/122/sessions/4151/lecture/19910-disentangling-semantics-and-syntax-in-sentence-embeddings-with-pre-trained-language-models}, year = {2021} }Check out our #NAACL2021 paper on semantic sentence embeddings! By disentangling the semantics and the syntax of sentences, our ParaBART achieves better performance on semantic textual similarity tasks. (https://t.co/QspSh8W2XJ w/ James Huang and @kaiwei_chang) [1/2] #UCLANLP pic.twitter.com/XzgSmN0353
— Kuan-Hao Huang (@kuanhao_) April 15, 2021
Event Extraction
EventPlus: A Temporal Event Understanding Pipeline
Mingyu Derek Ma, Jiao Sun, Mu Yang, Kung-Hsiang Huang, Nuan Wen, Shikhar Singh, Rujun Han, and Nanyun Peng, in 2021 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), Demonstrations Track, 2021.
QA Sessions: 10F-POSTER: SYSTEM DEMONSTRATIONS Paper link in the virtual conferenceFull Text Slides Poster Code BibTeX DetailsDetailsWe present EventPlus, a temporal event understanding pipeline that integrates various state-of-the-art event understanding components including event trigger and type detection, event argument detection, event duration and temporal relation extraction. Event information, especially event temporal knowledge, is a type of common sense knowledge that helps people understand how stories evolve and provides predictive hints for future events. EventPlus as the first comprehensive temporal event understanding pipeline provides a convenient tool for users to quickly obtain annotations about events and their temporal information for any user-provided document. Furthermore, we show EventPlus can be easily adapted to other domains (e.g., biomedical domain). We make EventPlus publicly available to facilitate event-related information extraction and downstream applications.
@inproceedings{ma2021eventplus, title = {EventPlus: A Temporal Event Understanding Pipeline}, author = {Ma, Mingyu Derek and Sun, Jiao and Yang, Mu and Huang, Kung-Hsiang and Wen, Nuan and Singh, Shikhar and Han, Rujun and Peng, Nanyun}, booktitle = {2021 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), Demonstrations Track}, presentation_id = {https://underline.io/events/122/posters/4227/poster/20582-eventplus-a-temporal-event-understanding-pipeline}, year = {2021} }Document-level Event Extraction with Efficient End-to-end Learning of Cross-event Dependencies
Kung-Hsiang Huang and Nanyun Peng, in The 3rd Workshop on Narrative Understanding (NAACL 2021), 2021.
QA Sessions: THE THIRD WORKSHOP ON NARRATIVE UNDERSTANDING Paper link in the virtual conferenceFull Text BibTeX DetailsDetailsFully understanding narratives often requires identifying events in the context of whole documents and modeling the event relations. However, document-level event extraction is a challenging task as it requires the extraction of event and entity coreference, and capturing arguments that span across different sentences. Existing works on event extraction usually confine on extracting events from single sentences, which fail to capture the relationships between the event mentions at the scale of a document, as well as the event arguments that appear in a different sentence than the event trigger. In this paper, we propose an end-to-end model leveraging Deep Value Networks (DVN), a structured prediction algorithm, to efficiently capture cross-event dependencies for document-level event extraction. Experimental results show that our approach achieves comparable performance to CRF-based models on ACE05, while enjoys significantly higher computational efficiency.
@inproceedings{huang2021document, title = {Document-level Event Extraction with Efficient End-to-end Learning of Cross-event Dependencies}, author = {Huang, Kung-Hsiang and Peng, Nanyun}, booktitle = {The 3rd Workshop on Narrative Understanding (NAACL 2021)}, presentation_id = {https://underline.io/events/122/posters/4309/poster/20541-document-level-event-extraction-with-efficient-end-to-end-learning-of-cross-event-dependencies}, year = {2021} }