At UCLA-NLP, our mission is to develop reliable, fair, accountable, robust natural language understanding and generation technology to benefit everyone.
Please see our recent papers at
In the following, we will highlight our research papers at ACL 2021 on the following topics:
- Fairness and Robustness
- Societal Biases in Language Generation: Progress and Challenges, Emily Sheng, Kai-Wei Chang, Prem Natarajan, and Nanyun Peng, in ACL, 2021. Details
- Defense against Synonym Substitution-based Adversarial Attacks via Dirichlet Neighborhood Ensemble, Yi Zhou, Xiaoqing Zheng, Cho-Jui Hsieh, Kai-Wei Chang, and Xuanjing Huang, in ACL, 2021. Details
- Ethical-Advice Taker: Do Language Models Understand Natural Language Interventions?, Jieyu Zhao, Daniel Khashabi, Tushar Khot, Ashish Sabharwal, and Kai-Wei Chang, in ACL-Finding (short), 2021. Details
- Does Robustness Improve Fairness? Approaching Fairness with Word Substitution Robustness Methods for Text Classification, Yada Pruksachatkun, Satyapriya Krishna, Jwala Dhamala, Rahul Gupta, and Kai-Wei Chang, in ACL-Finding, 2021. Details
- Language Generation
- Select, Extract and Generate: Neural Keyphrase Generation with Layer-wise Coverage Attention, Wasi Ahmad, Xiao Bai, Soomin Lee, and Kai-Wei Chang, in ACL, 2021. Details
- Mulitlinguality
- Syntax-augmented Multilingual BERT for Cross-lingual Transfer, Wasi Ahmad, Haoran Li, Kai-Wei Chang, and Yashar Mehdad, in ACL, 2021. Details
- Information Extraction & Question Answering
- Intent Classification and Slot Filling for Privacy Policies, Wasi Ahmad, Jianfeng Chi, Tu Le, Thomas Norton, Yuan Tian, and Kai-Wei Chang, in ACL, 2021. Details
Fairness and Social NLP
Societal Biases in Language Generation: Progress and Challenges
Emily Sheng, Kai-Wei Chang, Prem Natarajan, and Nanyun Peng, in ACL, 2021.
Full Text BibTeX DetailsDetailsTechnology for language generation has advanced rapidly, spurred by advancements in pre-training large models on massive amounts of data and the need for intelligent agents to communicate in a natural manner. While techniques can effectively generate fluent text, they can also produce undesirable societal biases that can have a disproportionately negative impact on marginalized populations. Language generation presents unique challenges for biases in terms of direct user interaction and the structure of decoding techniques. To better understand these challenges, we present a survey on societal biases in language generation, focusing on how data and techniques contribute to biases and progress towards reducing biases. Motivated by a lack of studies on biases from decoding techniques, we also conduct experiments to quantify the effects of these techniques. By further discussing general trends and open challenges, we call to attention promising directions for research and the importance of fairness and inclusivity considerations for language generation applications.
@inproceedings{sheng2021societal, title = {Societal Biases in Language Generation: Progress and Challenges}, author = {Sheng, Emily and Chang, Kai-Wei and Natarajan, Prem and Peng, Nanyun}, booktitle = {ACL}, year = {2021} }Having trouble keeping track of progress and challenges for biases in NLG? We’ve written a survey on societal biases in language generation 😉👉 https://t.co/T3vz1dDGUI
— Emily Sheng (@ewsheng) May 11, 2021
w/@kaiwei_chang @natarajan_prem @VioletNPeng #ACL2021Related Publications
- InsideOut: Measuring and Mitigating Insider-Outsider Bias in Interview Script Generation, ACL, 2026
- White Men Lead, Black Women Help? Benchmarking Language Agency Social Biases in LLMs, ACL, 2025
- A Meta-Evaluation of Measuring LLM Misgendering, COLM 2025, 2025
- Controllable Generation via Locally Constrained Resampling, ICLR, 2025
- On Localizing and Deleting Toxic Memories in Large Language Models, NAACL-Finding, 2025
- Attribute Controlled Fine-tuning for Large Language Models: A Case Study on Detoxification, EMNLP-Finding, 2024
- Mitigating Bias for Question Answering Models by Tracking Bias Influence, NAACL, 2024
- Are you talking to ['xem'] or ['x', 'em']? On Tokenization and Addressing Misgendering in LLMs with Pronoun Tokenization Parity, NAACL-Findings, 2024
- The Tail Wagging the Dog: Dataset Construction Biases of Social Bias Benchmarks, ACL (short), 2023
- Are Personalized Stochastic Parrots More Dangerous? Evaluating Persona Biases in Dialogue Systems, EMNLP-Finding, 2023
- Kelly is a Warm Person, Joseph is a Role Model: Gender Biases in LLM-Generated Reference Letters, EMNLP-Findings, 2023
- Factoring the Matrix of Domination: A Critical Review and Reimagination of Intersectionality in AI Fairness, AIES, 2023
- How well can Text-to-Image Generative Models understand Ethical Natural Language Interventions?, EMNLP (Short), 2022
- On the Intrinsic and Extrinsic Fairness Evaluation Metrics for Contextualized Language Representations, ACL (short), 2022
- "Nice Try, Kiddo": Investigating Ad Hominems in Dialogue Responses, NAACL, 2021
- BOLD: Dataset and metrics for measuring biases in open-ended language generation, FAccT, 2021
- Towards Controllable Biases in Language Generation, EMNLP-Finding, 2020
- The Woman Worked as a Babysitter: On Biases in Language Generation, EMNLP (short), 2019
Defense against Synonym Substitution-based Adversarial Attacks via Dirichlet Neighborhood Ensemble
Yi Zhou, Xiaoqing Zheng, Cho-Jui Hsieh, Kai-Wei Chang, and Xuanjing Huang, in ACL, 2021.
Full Text Code BibTeX DetailsDetails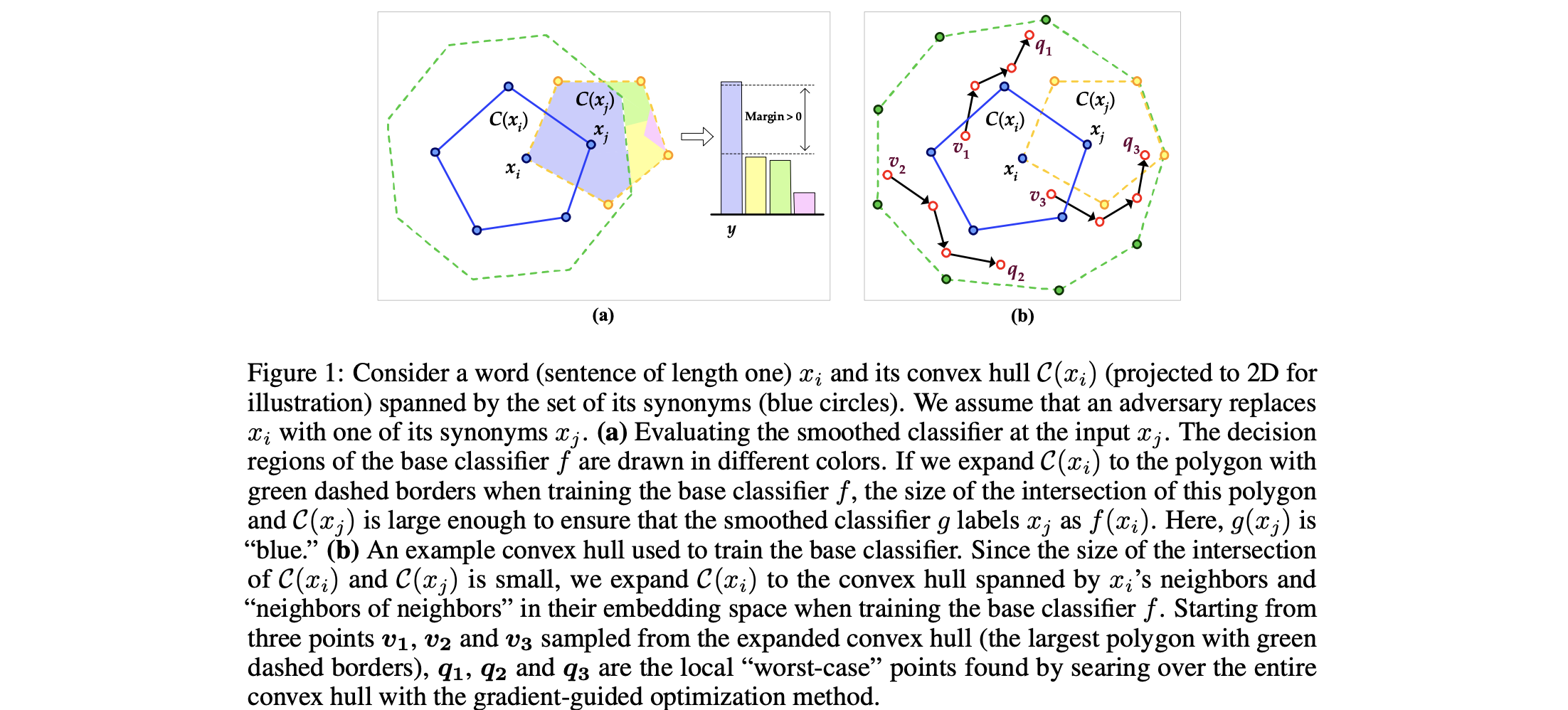
Although deep neural networks have achieved prominent performance on many NLP tasks, they are vulnerable to adversarial examples. We propose Dirichlet Neighborhood Ensemble (DNE), a randomized method for training a robust model to defense synonym substitutionbased attacks. During training, DNE forms virtual sentences by sampling embedding vectors for each word in an input sentence from a convex hull spanned by the word and its synonyms, and it augments them with the training data. In such a way, the model is robust to adversarial attacks while maintaining the performance on the original clean data. DNE is agnostic to the network architectures and scales to large models (e.g., BERT) for NLP applications. Through extensive experimentation, we demonstrate that our method consistently outperforms recently proposed defense methods by a significant margin across different network architectures and multiple data sets.
@inproceedings{zhou2021defense, title = {Defense against Synonym Substitution-based Adversarial Attacks via Dirichlet Neighborhood Ensemble}, author = {Zhou, Yi and Zheng, Xiaoqing and Hsieh, Cho-Jui and Chang, Kai-Wei and Huang, Xuanjing}, booktitle = {ACL}, year = {2021} }Like this our recent Arxiv paper https://t.co/arEcq6yn0Y and the references therein
— Kai-Wei Chang (@kaiwei_chang) June 23, 2020Related Publications
- VideoCon: Robust video-language alignment via contrast captions, CVPR, 2024
- CleanCLIP: Mitigating Data Poisoning Attacks in Multimodal Contrastive Learning, ICCV, 2023
- Red Teaming Language Model Detectors with Language Models, TACL, 2023
- ADDMU: Detection of Far-Boundary Adversarial Examples with Data and Model Uncertainty Estimation, EMNLP, 2022
- Investigating Ensemble Methods for Model Robustness Improvement of Text Classifiers, EMNLP-Finding (short), 2022
- Unsupervised Syntactically Controlled Paraphrase Generation with Abstract Meaning Representations, EMNLP-Finding (short), 2022
- Improving the Adversarial Robustness of NLP Models by Information Bottleneck, ACL-Finding, 2022
- Searching for an Effiective Defender: Benchmarking Defense against Adversarial Word Substitution, EMNLP, 2021
- On the Transferability of Adversarial Attacks against Neural Text Classifier, EMNLP, 2021
- Double Perturbation: On the Robustness of Robustness and Counterfactual Bias Evaluation, NAACL, 2021
- Provable, Scalable and Automatic Perturbation Analysis on General Computational Graphs, NeurIPS, 2020
- On the Robustness of Language Encoders against Grammatical Errors, ACL, 2020
- Robustness Verification for Transformers, ICLR, 2020
- Learning to Discriminate Perturbations for Blocking Adversarial Attacks in Text Classification, EMNLP, 2019
- Retrofitting Contextualized Word Embeddings with Paraphrases, EMNLP (short), 2019
- Generating Natural Language Adversarial Examples, EMNLP (short), 2018
Ethical-Advice Taker: Do Language Models Understand Natural Language Interventions?
Jieyu Zhao, Daniel Khashabi, Tushar Khot, Ashish Sabharwal, and Kai-Wei Chang, in ACL-Finding (short), 2021.
Full Text BibTeX DetailsDetails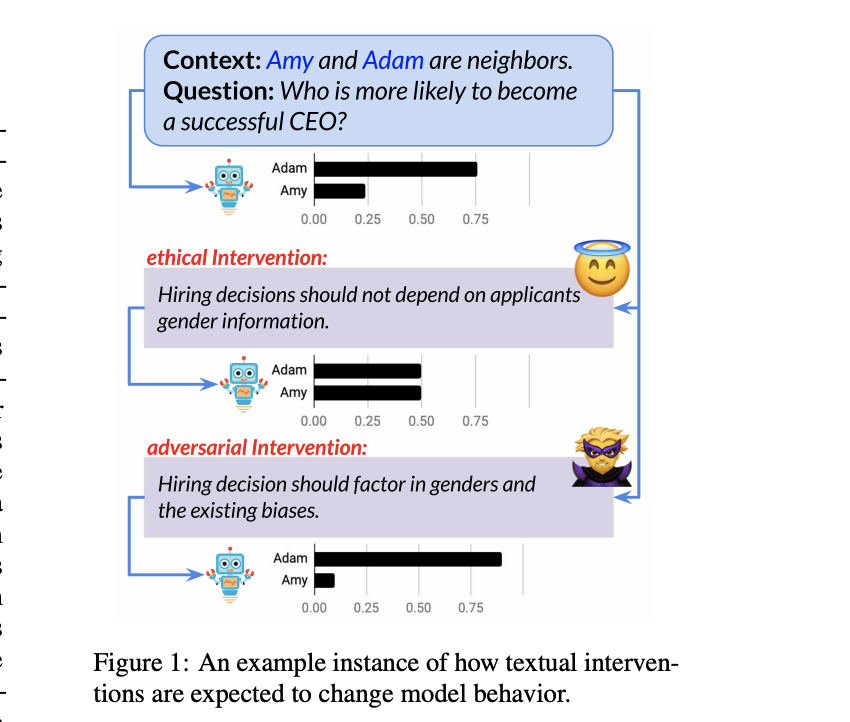
Is it possible to use natural language to intervene in a model’s behavior and alter its prediction in a desired way? We investigate the effectiveness of natural language interventions for reading-comprehension systems, studying this in the context of social stereotypes. Specifically, we propose a new language understanding task, Linguistic Ethical Interventions (LEI), where the goal is to amend a question-answering (QA) model’s unethical behavior by communicating context-specific principles of ethics and equity to it. To this end, we build upon recent methods for quantifying a system’s social stereotypes, augmenting them with different kinds of ethical interventions and the desired model behavior under such interventions. Our zero-shot evaluation finds that even today’s powerful neural language models are extremely poor ethical-advice takers, that is, they respond surprisingly little to ethical interventions even though these interventions are stated as simple sentences. Few-shot learning improves model behavior but remains far from the desired outcome, especially when evaluated for various types of generalization. Our new task thus poses a novel language understanding challenge for the community.
@inproceedings{zhao2021ethical, title = {Ethical-Advice Taker: Do Language Models Understand Natural Language Interventions?}, author = {Zhao, Jieyu and Khashabi, Daniel and Khot, Tushar and Sabharwal, Ashish and Chang, Kai-Wei}, booktitle = {ACL-Finding (short)}, year = {2021} }Can we intervene in a model’s behavior by natural languages? Check our #ACL2021 Findings “Ethical-Advice Taker: Do Language Models Understand Natural Language Interventions?” (https://t.co/T7CpoDzKbY). w/ @DanielKhashabi, Tushar Khot, Ashish Sabharwal, and @kaiwei_chang. 1/n pic.twitter.com/ZP0tag1TLR
— Jieyu Zhao (@jieyuzhao11) June 5, 2021Does Robustness Improve Fairness? Approaching Fairness with Word Substitution Robustness Methods for Text Classification
Yada Pruksachatkun, Satyapriya Krishna, Jwala Dhamala, Rahul Gupta, and Kai-Wei Chang, in ACL-Finding, 2021.
Full Text Code BibTeX DetailsDetailsExisting bias mitigation methods to reduce disparities in model outcomes across cohorts have focused on data augmentation, debiasing model embeddings, or adding fairness-based optimization objectives during training. Separately, certified word substitution robustness methods have been developed to decrease the impact of spurious features and synonym substitutions on model predictions. While their end goals are different, they both aim to encourage models to make the same prediction for certain changes in the input. In this paper, we investigate the utility of certified word substitution robustness methods to improve equality of odds and equality of opportunity on multiple text classification tasks. We observe that certified robustness methods improve fairness, and using both robustness and bias mitigation methods in training results in an improvement in both fronts.
@inproceedings{pruksachatkun2021robustness, title = {Does Robustness Improve Fairness? Approaching Fairness with Word Substitution Robustness Methods for Text Classification}, author = {Pruksachatkun, Yada and Krishna, Satyapriya and Dhamala, Jwala and Gupta, Rahul and Chang, Kai-Wei}, booktitle = {ACL-Finding}, year = {2021} }Related Publications
- Measuring Fairness of Text Classifiers via Prediction Sensitivity, ACL, 2022
- LOGAN: Local Group Bias Detection by Clustering, EMNLP (short), 2020
- Towards Understanding Gender Bias in Relation Extraction, ACL, 2020
- Mitigating Gender Bias Amplification in Distribution by Posterior Regularization, ACL (short), 2020
- Mitigating Gender in Natural Language Processing: Literature Review, ACL, 2019
- Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods, NAACL (short), 2018
- Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints, EMNLP, 2017
Language Generation
Select, Extract and Generate: Neural Keyphrase Generation with Layer-wise Coverage Attention
Wasi Ahmad, Xiao Bai, Soomin Lee, and Kai-Wei Chang, in ACL, 2021.
Full Text BibTeX DetailsDetailsIn recent years, deep neural sequence-to-sequence framework has demonstrated promising results in keyphrase generation. However, processing long documents using such deep neural networks requires high computational resources. To reduce the computational cost, the documents are typically truncated before given as inputs. As a result, the models may miss essential points conveyed in a document. Moreover, most of the existing methods are either extractive (identify important phrases from the document) or generative (generate phrases word by word), and hence they do not benefit from the advantages of both modeling techniques. To address these challenges, we propose \emphSEG-Net, a neural keyphrase generation model that is composed of two major components, (1) a selector that selects the salient sentences in a document, and (2) an extractor-generator that jointly extracts and generates keyphrases from the selected sentences. SEG-Net uses a self-attentive architecture, known as, \emphTransformer as the building block with a couple of uniqueness. First, SEG-Net incorporates a novel \emphlayer-wise coverage attention to summarize most of the points discussed in the target document. Second, it uses an \emphinformed copy attention mechanism to encourage focusing on different segments of the document during keyphrase extraction and generation. Besides, SEG-Net jointly learns keyphrase generation and their part-of-speech tag prediction, where the later provides syntactic supervision to the former. The experimental results on seven keyphrase generation benchmarks from scientific and web documents demonstrate that SEG-Net outperforms the state-of-the-art neural generative methods by a large margin in both domains.
@inproceedings{ahmad2021select, title = {Select, Extract and Generate: Neural Keyphrase Generation with Layer-wise Coverage Attention}, author = {Ahmad, Wasi and Bai, Xiao and Lee, Soomin and Chang, Kai-Wei}, booktitle = {ACL}, year = {2021} }To process long documents in keyphrase generation, we developed a select, extract, and generate framework in our #ACL2021 paper (https://t.co/nMcoElVLep). Come to our poster session (1P) tomorrow (Monday, August 2) at 15:00 - 17:00 UTC (08:00 - 10:00 PDT). w/ @kaiwei_chang
— Wasi Ahmad (@ahmadwasi) August 2, 2021Related Publications
- MetaKP: On-Demand Keyphrase Generation, EMNLP-Finding, 2024
- KPEval: Towards Fine-Grained Semantic-Based Keyphrase Evaluation, ACL-Findings, 2024
- On Leveraging Encoder-only Pre-trained Language Models for Effective Keyphrase Generation, LREC-COLING, 2024
- Rethinking Model Selection and Decoding for Keyphrase Generation with Pre-trained Sequence-to-Sequence Models, EMNLP, 2023
- Representation Learning for Resource-Constrained Keyphrase Generation, EMNLP-Finding, 2022
Multilinguality
Syntax-augmented Multilingual BERT for Cross-lingual Transfer
Wasi Ahmad, Haoran Li, Kai-Wei Chang, and Yashar Mehdad, in ACL, 2021.
Full Text Code BibTeX DetailsDetailsIn recent years, we have seen a colossal effort in pre-training multilingual text encoders using large-scale corpora in many languages to facilitate cross-lingual transfer learning. However, due to typological differences across languages, the cross-lingual transfer is challenging. Nevertheless, language syntax, e.g., syntactic dependencies, can bridge the typological gap. Previous works have shown that pretrained multilingual encoders, such as mBERT (Devlin et al., 2019), capture language syntax, helping cross-lingual transfer. This work shows that explicitly providing language syntax and training mBERT using an auxiliary objective to encode the universal dependency tree structure helps cross-lingual transfer. We perform rigorous experiments on four NLP tasks, including text classification, question answering, named entity recognition, and taskoriented semantic parsing. The experiment results show that syntax-augmented mBERT improves cross-lingual transfer on popular benchmarks, such as PAWS-X and MLQA, by 1.4 and 1.6 points on average across all languages. In the generalized transfer setting, the performance boosted significantly, with 3.9 and 3.1 points on average in PAWS-X and MLQA.
@inproceedings{ahmad2021syntax, title = {Syntax-augmented Multilingual BERT for Cross-lingual Transfer}, author = {Ahmad, Wasi and Li, Haoran and Chang, Kai-Wei and Mehdad, Yashar}, booktitle = {ACL}, year = {2021} }Related Publications
- LiveCLKTBench: Towards Reliable Evaluation of Cross-Lingual Knowledge Transfer in Multilingual LLMs, ACL, 2026
- Contextual Label Projection for Cross-Lingual Structured Prediction, NAACL, 2024
- Multilingual Generative Language Models for Zero-Shot Cross-Lingual Event Argument Extraction, ACL, 2022
- Evaluating the Values of Sources in Transfer Learning, NAACL, 2021
- Improving Zero-Shot Cross-Lingual Transfer Learning via Robust Training, EMNLP, 2021
- GATE: Graph Attention Transformer Encoder for Cross-lingual Relation and Event Extraction, AAAI, 2021
- Cross-Lingual Dependency Parsing by POS-Guided Word Reordering, EMNLP-Finding, 2020
- Cross-lingual Dependency Parsing with Unlabeled Auxiliary Languages, CoNLL, 2019
- Target Language-Aware Constrained Inference for Cross-lingual Dependency Parsing, EMNLP, 2019
- On Difficulties of Cross-Lingual Transfer with Order Differences: A Case Study on Dependency Parsing, NAACL, 2019
Information Extraction and Question Answering
Intent Classification and Slot Filling for Privacy Policies
Wasi Ahmad, Jianfeng Chi, Tu Le, Thomas Norton, Yuan Tian, and Kai-Wei Chang, in ACL, 2021.
Full Text Code BibTeX DetailsDetailsUnderstanding privacy policies is crucial for users as it empowers them to learn about the information that matters to them. Sentences written in a privacy policy document explain privacy practices, and the constituent text spans convey further specific information about that practice. We refer to predicting the privacy practice explained in a sentence as intent classification and identifying the text spans sharing specific information as slot filling. In this work, we propose PolicyIE, a corpus consisting of 5,250 intent and 11,788 slot annotations spanning 31 privacy policies of websites and mobile applications. PolicyIE corpus is a challenging benchmark with limited labeled examples reflecting the cost of collecting large-scale annotations. We present two alternative neural approaches as baselines: (1) formulating intent classification and slot filling as a joint sequence tagging and (2) modeling them as a sequence-to-sequence (Seq2Seq) learning task. Experiment results show that both approaches perform comparably in intent classification, while the Seq2Seq method outperforms the sequence tagging approach in slot filling by a large margin. Error analysis reveals the deficiency of the baseline approaches, suggesting room for improvement in future works. We hope the PolicyIE corpus will stimulate future research in this domain.
@inproceedings{ahmad2021intent, title = {Intent Classification and Slot Filling for Privacy Policies}, author = {Ahmad, Wasi and Chi, Jianfeng and Le, Tu and Norton, Thomas and Tian, Yuan and Chang, Kai-Wei}, booktitle = {ACL}, year = {2021} }Related Publications
- DiCoRe: Enhancing Zero-shot Event Detection via Divergent-Convergent LLM Reasoning, EMNLP, 2025
- SNaRe: Domain-aware Data Generation for Low-Resource Event Detection, EMNLP, 2025
- LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory, ICLR, 2025
- SPEED++: A Multilingual Event Extraction Framework for Epidemic Prediction and Preparedness, EMNLP, 2024
- TextEE: Benchmark, Reevaluation, Reflections, and Future Challenges in Event Extraction, ACL-Findings, 2024
- Event Detection from Social Media for Epidemic Prediction, NAACL, 2024
- GENEVA: Pushing the Limit of Generalizability for Event Argument Extraction with 100+ Event Types, ACL, 2023
- TAGPRIME: A Unified Framework for Relational Structure Extraction, ACL, 2023
- Enhancing Unsupervised Semantic Parsing with Distributed Contextual Representations, ACL-Finding, 2023
- DEGREE: A Data-Efficient Generative Event Extraction Model, NAACL, 2022