At UCLA-NLP, our mission is to develop reliable, fair, accountable, robust natural language understanding and generation technology to benefit everyone. See our recent papers here
ACL is one of the major conferences in the field of natural language processing (NLP). We will participate in the following activities this year.
Tutorial
We will present a tutorial on “Indirectly Supervised Natural Language Processing” in 14:00-17:30 on 7/9
Dear @ACLattendees: Prepare to be blown away at our mind-blowing tutorial "Indirectly Supervised NLP"! Join us at the "Metropolitan Centre" hall on July 9th, sharp at 2pm. Your attendance and comments are priceless. @muhao_chen @BenZhou96 , Qiang Ning, @kaiwei_chang @DanRothNLP pic.twitter.com/vt5D6O79bO
— Wenpeng_Yin (@Wenpeng_Yin) July 7, 2023
Workshop
We will host the 3rd Trustworthy Natual Language Processing Workshop on 7/14.
Accepted Papers
we will present papers on the following topics:
- Trustworthy NLP
- The Tail Wagging the Dog: Dataset Construction Biases of Social Bias Benchmarks, Nikil Roashan Selvam, Sunipa Dev, Daniel Khashabi, Tushar Khot, and Kai-Wei Chang, in ACL (short), 2023. Details
- Efficient Shapley Values Estimation by Amortization for Text Classification, Chenghao Yang, Fan Yin, He He, Kai-Wei Chang, Xiaofei Ma, and Bing Xiang, in ACL, 2023. Details
- Resolving Ambiguities in Text-to-Image Generative Models, Ninareh Mehrabi, Palash Goyal, Apurv Verma, Jwala Dhamala, Varun Kumar, Qian Hu, Kai-Wei Chang, Richard Zemel, Aram Galstyan, and Rahul Gupta, in ACL, 2023. Details
- PLUE: Language Understanding Evaluation Benchmark for Privacy Policies in English, Jianfeng Chi, Wasi Uddin Ahmad, Yuan Tian, and Kai-Wei Chang, in ACL (short), 2023. Details
- Vision-Language and Multimodal Model
- MetaVL: Transferring In-Context Learning Ability From Language Models to Vision-Language Models, Masoud Monajatipoor, Liunian Harold Li, Mozhdeh Rouhsedaghat, Lin Yang, and Kai-Wei Chang, in ACL (short), 2023. Details
- UniFine: A Unified and Fine-grained Approach for Zero-shot Vision-Language Understanding, Rui Sun, Zhecan Wang, Haoxuan You, Noel Codella, Kai-Wei Chang, and Shih-Fu Chang, in ACL-Finding, 2023. Details
- AVATAR: A Parallel Corpus for Java-Python Program Translation, Wasi Ahmad, Md Golam Rahman Tushar, Saikat Chakraborty, and Kai-Wei Chang, in ACL-Finding (short), 2023. Details
- Language and Reasoning
- A Survey of Deep Learning for Mathematical Reasoning, Pan Lu, Liang Qiu, Wenhao Yu, Sean Welleck, and Kai-Wei Chang, in ACL, 2023. Details
- Symbolic Chain-of-Thought Distillation: Small Models Can Also "Think" Step-by-Step, Liunian Harold Li, Jack Hessel, Youngjae Yu, Xiang Ren, Kai-Wei Chang, and Yejin Choi, in ACL, 2023. Details
- Semantic and Syantatic Analysis
- ParaAMR: A Large-Scale Syntactically Diverse Paraphrase Dataset by AMR Back-Translation, Kuan-Hao Huang, Varun Iyer, I.-Hung Hsu, Anoop Kumar, Kai-Wei Chang, and Aram Galstyan, in ACL, 2023. Details
- GENEVA: Pushing the Limit of Generalizability for Event Argument Extraction with 100+ Event Types, Tanmay Parekh, I.-Hung Hsu, Kuan-Hao Huang, Kai-Wei Chang, and Nanyun Peng, in ACL, 2023. Details
- TAGPRIME: A Unified Framework for Relational Structure Extraction, I.-Hung Hsu, Kuan-Hao Huang, Shuning Zhang, Wenxin Cheng, Prem Natarajan, Kai-Wei Chang, and Nanyun Peng, in ACL, 2023. Details
- PIP: Parse-Instructed Prefix for Syntactically Controlled Paraphrase Generation, Yixin Wan, Kuan-Hao Huang, and Kai-Wei Chang, in ACL-Finding (short), 2023. Details
- Enhancing Unsupervised Semantic Parsing with Distributed Contextual Representations, Zixuan Ling, Xiaoqing Zheng, Jianhan Xu, Jinshu Lin, Kai-Wei Chang, Cho-Jui Hsieh, and Xuanjing Huang, in ACL-Finding, 2023. Details
The Tail Wagging the Dog: Dataset Construction Biases of Social Bias Benchmarks
Nikil Roashan Selvam, Sunipa Dev, Daniel Khashabi, Tushar Khot, and Kai-Wei Chang, in ACL (short), 2023.
QA Sessions: POSTER SESSION 2: July 10 14:00 AM - July 10 15:30 PM Paper link in the virtual conferenceFull Text BibTeX Details Outstanding Paper AwardDetails
How reliably can we trust the scores obtained from social bias benchmarks as faithful indicators of problematic social biases in a given language model? In this work, we study this question by contrasting social biases with non-social biases stemming from choices made during dataset construction that might not even be discernible to the human eye. To do so, we empirically simulate various alternative constructions for a given benchmark based on innocuous modifications (such as paraphrasing or random-sampling) that maintain the essence of their social bias. On two well-known social bias benchmarks (Winogender and BiasNLI) we observe that these shallow modifications have a surprising effect on the resulting degree of bias across various models. We hope these troubling observations motivate more robust measures of social biases.
@inproceedings{roashan2023tail, author = {Selvam, Nikil Roashan and Dev, Sunipa and Khashabi, Daniel and Khot, Tushar and Chang, Kai-Wei}, title = {The Tail Wagging the Dog: Dataset Construction Biases of Social Bias Benchmarks}, presentation_id = {https://underline.io/events/395/posters/15337/poster/76963-the-tail-wagging-the-dog-dataset-construction-biases-of-social-bias-benchmarks}, booktitle = {ACL (short)}, year = {2023} }Related Publications
- InsideOut: Measuring and Mitigating Insider-Outsider Bias in Interview Script Generation, ACL, 2026
- White Men Lead, Black Women Help? Benchmarking Language Agency Social Biases in LLMs, ACL, 2025
- A Meta-Evaluation of Measuring LLM Misgendering, COLM 2025, 2025
- Controllable Generation via Locally Constrained Resampling, ICLR, 2025
- On Localizing and Deleting Toxic Memories in Large Language Models, NAACL-Finding, 2025
- Attribute Controlled Fine-tuning for Large Language Models: A Case Study on Detoxification, EMNLP-Finding, 2024
- Mitigating Bias for Question Answering Models by Tracking Bias Influence, NAACL, 2024
- Are you talking to ['xem'] or ['x', 'em']? On Tokenization and Addressing Misgendering in LLMs with Pronoun Tokenization Parity, NAACL-Findings, 2024
- Are Personalized Stochastic Parrots More Dangerous? Evaluating Persona Biases in Dialogue Systems, EMNLP-Finding, 2023
- Kelly is a Warm Person, Joseph is a Role Model: Gender Biases in LLM-Generated Reference Letters, EMNLP-Findings, 2023
- Factoring the Matrix of Domination: A Critical Review and Reimagination of Intersectionality in AI Fairness, AIES, 2023
- How well can Text-to-Image Generative Models understand Ethical Natural Language Interventions?, EMNLP (Short), 2022
- On the Intrinsic and Extrinsic Fairness Evaluation Metrics for Contextualized Language Representations, ACL (short), 2022
- "Nice Try, Kiddo": Investigating Ad Hominems in Dialogue Responses, NAACL, 2021
- Societal Biases in Language Generation: Progress and Challenges, ACL, 2021
- BOLD: Dataset and metrics for measuring biases in open-ended language generation, FAccT, 2021
- Towards Controllable Biases in Language Generation, EMNLP-Finding, 2020
- The Woman Worked as a Babysitter: On Biases in Language Generation, EMNLP (short), 2019
Efficient Shapley Values Estimation by Amortization for Text Classification
Chenghao Yang, Fan Yin, He He, Kai-Wei Chang, Xiaofei Ma, and Bing Xiang, in ACL, 2023.
QA Sessions: Interpretability and Analysis of Models for NLP 2: 7/11 5:45PM Paper link in the virtual conferenceFull Text BibTeX DetailsDetails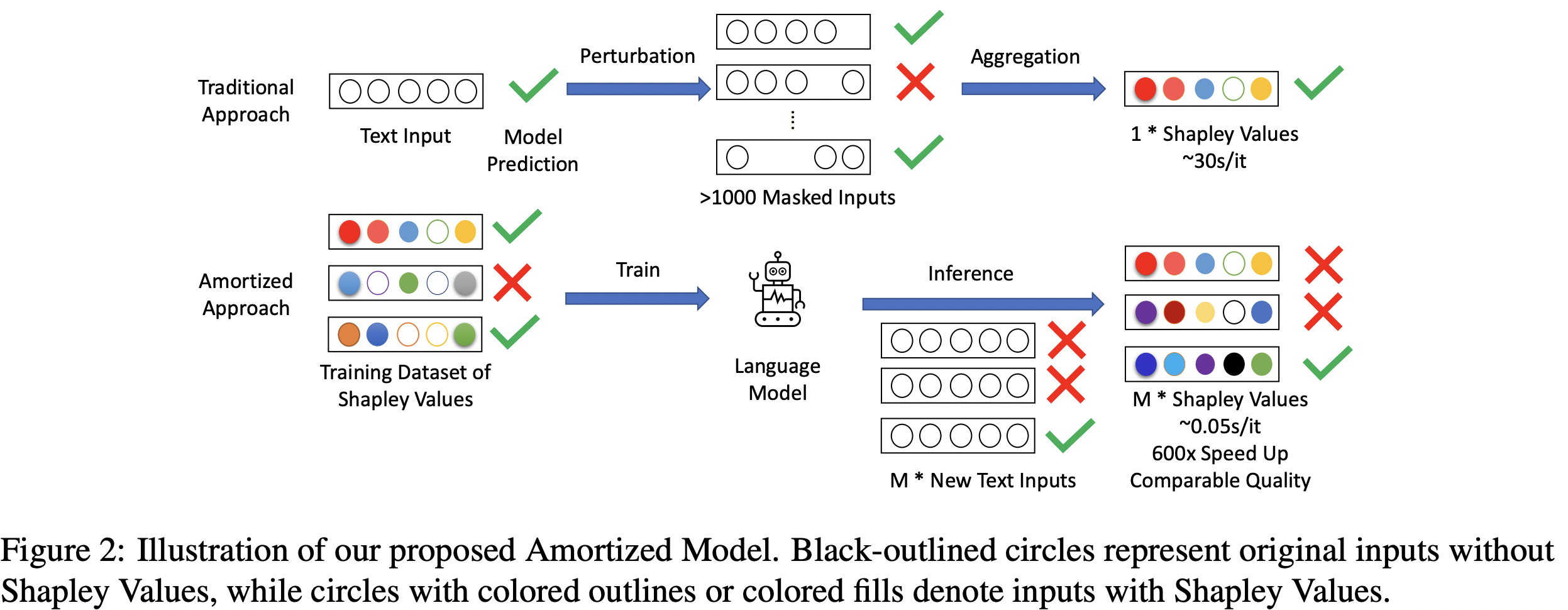
Despite the popularity of Shapley Values in explaining neural text classification models, computing them is prohibitive for large pretrained models due to a large number of model evaluations as it needs to perform multiple model evaluations over various perturbed text inputs. In practice, Shapley Values are often estimated stochastically with a smaller number of model evaluations. However, we find that the estimated Shapley Values are quite sensitive to random seeds – the top-ranked features often have little overlap under two different seeds, especially on examples with the longer input text. As a result, a much larger number of model evaluations is needed to reduce the sensitivity to an acceptable level. To mitigate the trade-off between stability and efficiency, we develop an amortized model that directly predicts Shapley Values of each input feature without additional model evaluation. It is trained on a set of examples with Shapley Values estimated from a large number of model evaluations to ensure stability. Experimental results on two text classification datasets demonstrate that, the proposed amortized model can estimate black-box explanation scores in milliseconds per sample in inference time and is up to 60 times more efficient than traditional methods.
@inproceedings{yang2023efficient, title = {Efficient Shapley Values Estimation by Amortization for Text Classification}, author = {Yang, Chenghao and Yin, Fan and He, He and Chang, Kai-Wei and Ma, Xiaofei and Xiang, Bing}, year = {2023}, presentation_id = {https://underline.io/events/395/sessions/15249/lecture/76179-efficient-shapley-values-estimation-by-amortization-for-text-classification}, booktitle = {ACL} }Resolving Ambiguities in Text-to-Image Generative Models
Ninareh Mehrabi, Palash Goyal, Apurv Verma, Jwala Dhamala, Varun Kumar, Qian Hu, Kai-Wei Chang, Richard Zemel, Aram Galstyan, and Rahul Gupta, in ACL, 2023.
QA Sessions: POSTER SESSION 4:July 11 11:00 AM - July 11 12:30 AM Paper link in the virtual conferenceFull Text BibTeX DetailsDetails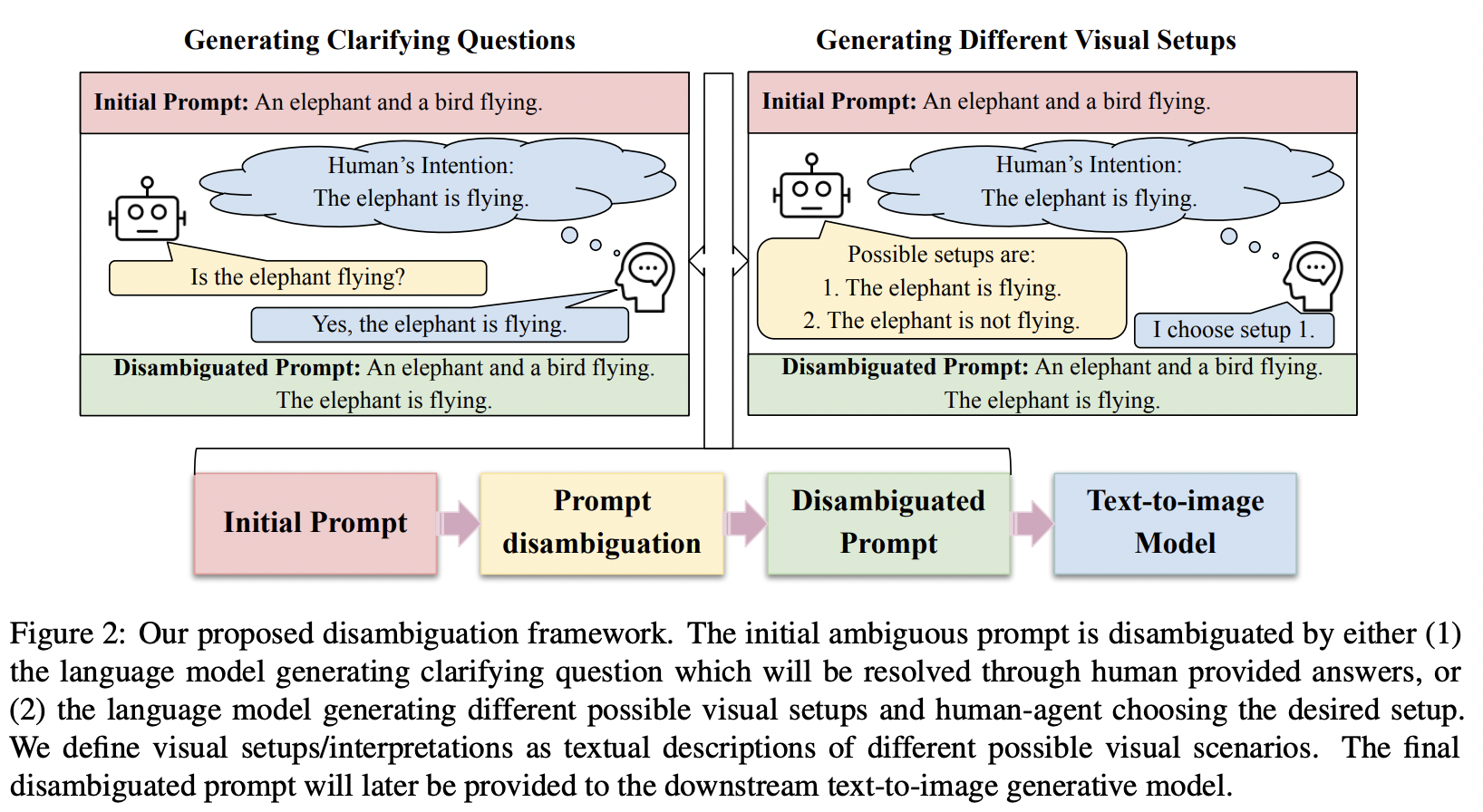
Natural language often contains ambiguities that can lead to misinterpretation and miscommunication. While humans can handle ambiguities effectively by asking clarifying questions and/or relying on contextual cues and common-sense knowledge, resolving ambiguities can be notoriously hard for machines. In this work, we study ambiguities that arise in text-to-image generative models. We curate a benchmark dataset covering different types of ambiguities that occur in these systems. We then propose a framework to mitigate ambiguities in the prompts given to the systems by soliciting clarifications from the user. Through automatic and human evaluations, we show the effectiveness of our framework in generating more faithful images aligned with human intention in the presence of ambiguities.
@inproceedings{mehrabi2023resolving, author = {Mehrabi, Ninareh and Goyal, Palash and Verma, Apurv and Dhamala, Jwala and Kumar, Varun and Hu, Qian and Chang, Kai-Wei and Zemel, Richard and Galstyan, Aram and Gupta, Rahul}, booktitle = {ACL}, title = {Resolving Ambiguities in Text-to-Image Generative Models}, presentation_id = {https://underline.io/events/395/posters/15237/poster/76575-resolving-ambiguities-in-text-to-image-generative-models}, year = {2023} }Related Publications
- Where Fact Ends and Fairness Begins: Redefining AI Bias Evaluation through Cognitive Biases, EMNLP-Finding, 2025
- The Male CEO and the Female Assistant: Evaluation and Mitigation of Gender Biases in Text-To-Image Generation of Dual Subjects, ACL, 2025
- JourneyBench: A Challenging One-Stop Vision-Language Understanding Benchmark of Generated Images, NeurIPS (Datasets and Benchmarks Track), 2024
- The Factuality Tax of Diversity-Intervened Text-to-Image Generation: Benchmark and Fact-Augmented Intervention, EMNLP, 2024
- MACAROON: Training Vision-Language Models To Be Your Engaged Partners, EMNLP-Finding, 2024
- Dataset Bias Mitigation in Multiple-Choice Visual Question Answering and Beyond, EMNLP-Findings, 2023
- UniFine: A Unified and Fine-grained Approach for Zero-shot Vision-Language Understanding, ACL-Finding, 2023
PLUE: Language Understanding Evaluation Benchmark for Privacy Policies in English
Jianfeng Chi, Wasi Uddin Ahmad, Yuan Tian, and Kai-Wei Chang, in ACL (short), 2023.
QA Sessions: VIRTUAL POSTER SESSION 3: July 12 11:00 AM - July 12 09:30 AM Paper link in the virtual conferenceFull Text BibTeX DetailsDetails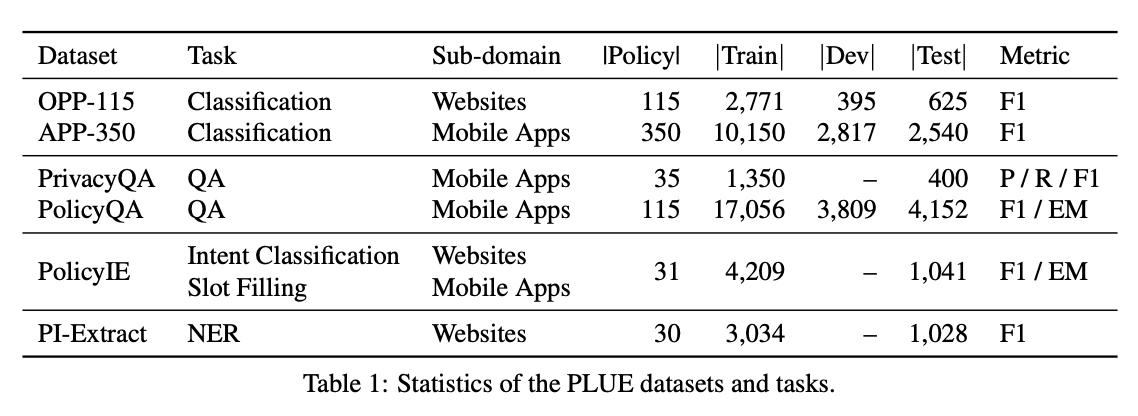
Privacy policies provide individuals with information about their rights and how their personal information is handled. Natural language understanding (NLU) technologies can support individuals and practitioners to understand better privacy practices described in lengthy and complex documents. However, existing efforts that use NLU technologies are limited by processing the language in a way exclusive to a single task focusing on certain privacy practices. To this end, we introduce the Privacy Policy Language Understanding Evaluation (PLUE) benchmark, a multi-task benchmark for evaluating the privacy policy language understanding across various tasks. We also collect a large corpus of privacy policies to enable privacy policy domain-specific language model pre-training. We evaluate several generic pre-trained language models and continue pre-training them on the collected corpus. We demonstrate that domain-specific continual pre-training offers performance improvements across all tasks.
@inproceedings{chi2023plue, author = {Chi, Jianfeng and Ahmad, Wasi Uddin and Tian, Yuan and Chang, Kai-Wei}, title = {PLUE: Language Understanding Evaluation Benchmark for Privacy Policies in English}, presentation_id = {https://underline.io/events/395/posters/15279/poster/76751-plue-language-understanding-evaluation-benchmark-for-privacy-policies-in-english}, booktitle = {ACL (short)}, year = {2023} }Related Publications
- MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding, ICLR, 2025
- ConTextual: Evaluating Context-Sensitive Text-Rich Visual Reasoning in Large Multimodal Models, ICML, 2024
- CASA: Causality-driven Argument Sufficiency Assessment, NAACL, 2024
- ParaAMR: A Large-Scale Syntactically Diverse Paraphrase Dataset by AMR Back-Translation, ACL, 2023
MetaVL: Transferring In-Context Learning Ability From Language Models to Vision-Language Models
Masoud Monajatipoor, Liunian Harold Li, Mozhdeh Rouhsedaghat, Lin Yang, and Kai-Wei Chang, in ACL (short), 2023.
QA Sessions: POSTER SESSION 2: July 10 14:00 AM - July 10 15:30 PM Paper link in the virtual conferenceFull Text BibTeX DetailsDetails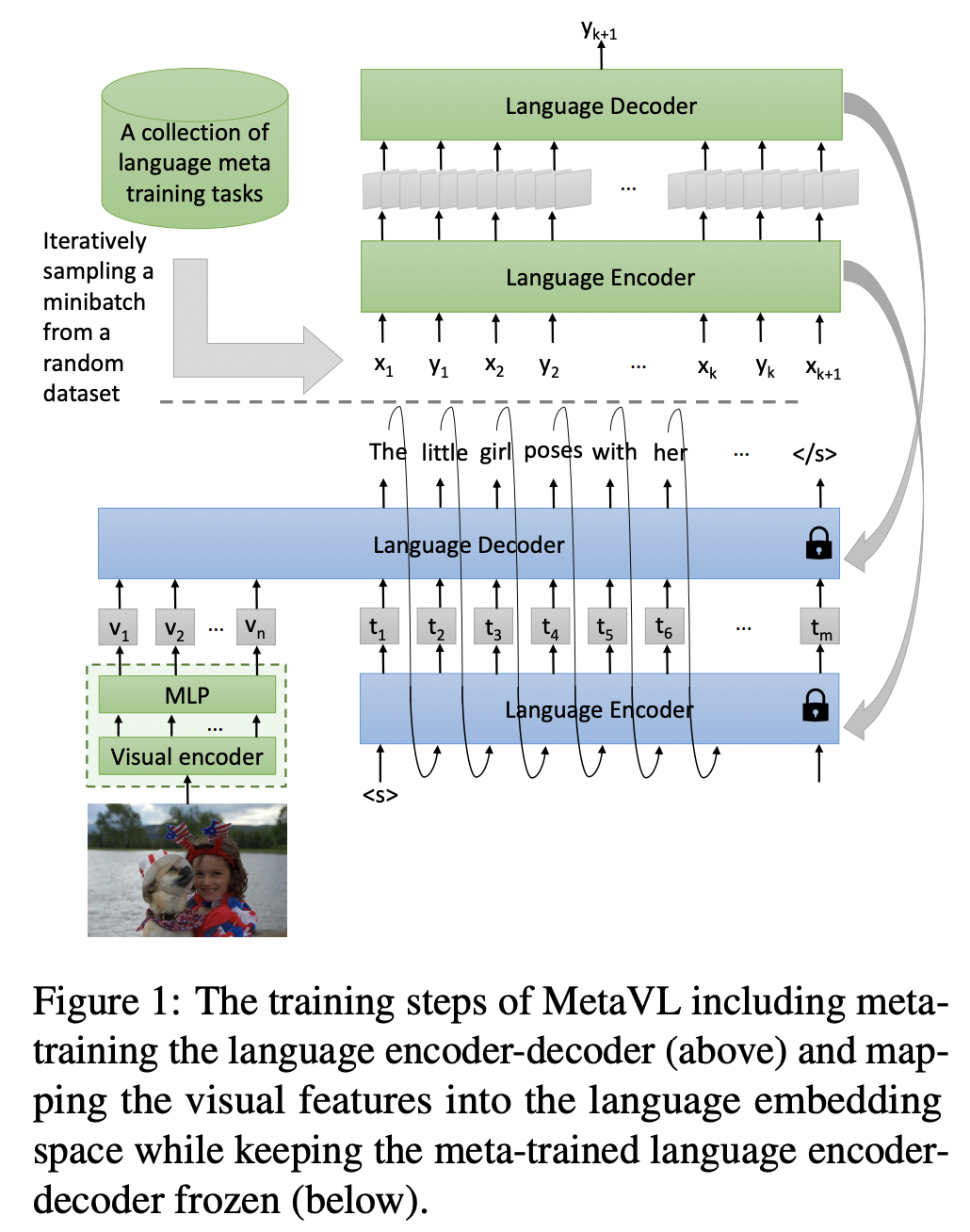
Large-scale language models have shown the ability to adapt to a new task via conditioning on a few demonstrations (i.e., in-context learning). However, in the vision-language domain, most large-scale pre-trained vision-language (VL) models do not possess the ability to conduct in-context learning. How can we enable in-context learning for VL models? In this paper, we study an interesting hypothesis: can we transfer the in-context learning ability from the language domain to VL domain? Specifically, we first meta-trains a language model to perform in-context learning on NLP tasks (as in MetaICL); then we transfer this model to perform VL tasks by attaching a visual encoder. Our experiments suggest that indeed in-context learning ability can be transferred cross modalities: our model considerably improves the in-context learning capability on VL tasks and can even compensate for the size of the model significantly. On VQA, OK-VQA, and GQA, our method could outperform the baseline model while having 20 times fewer parameters.
@inproceedings{monajatipoor2023metavl, author = {Monajatipoor, Masoud and Li, Liunian Harold and Rouhsedaghat, Mozhdeh and Yang, Lin and Chang, Kai-Wei}, title = {MetaVL: Transferring In-Context Learning Ability From Language Models to Vision-Language Models}, booktitle = {ACL (short)}, presentation_id = {https://underline.io/events/395/posters/15337/poster/76709-metavl-transferring-in-context-learning-ability-from-language-models-to-vision-language-models}, year = {2023} }Related Publications
- VisRet: Visualization Improves Knowledge-Intensive Text-to-Image Retrieval, ACL, 2026
- HoneyBee: Data Recipes for Vision-Language Reasoners, CVPR, 2026
- MotionEdit: Benchmarking and Learning Motion-Centric Image Editing, CVPR, 2026
- LaViDa: A Large Diffusion Language Model for Multimodal Understanding, NeurIPS, 2025
- PARTONOMY: Large Multimodal Models with Part-Level Visual Understanding, NeurIPS, 2025
- SlowFast-VGen: Slow-Fast Learning for Action-Driven Long Video Generation, ICLR, 2025
- Verbalized Representation Learning for Interpretable Few-Shot Generalization, ICCV, 2025
- STIV: Scalable Text and Image Conditioned Video Generation, ICCV, 2025
- Contrastive Visual Data Augmentation, ICML, 2025
- SYNTHIA: Novel Concept Design with Affordance Composition, ACL, 2025
- Towards a holistic framework for multimodal LLM in 3D brain CT radiology report generation, Nature Communications, 2025
- Enhancing Large Vision Language Models with Self-Training on Image Comprehension, NeurIPS, 2024
- CoBIT: A Contrastive Bi-directional Image-Text Generation Model, ICLR, 2024
- DesCo: Learning Object Recognition with Rich Language Descriptions, NeurIPS, 2023
- Text Encoders are Performance Bottlenecks in Contrastive Vision-Language Models, EMNLP, 2023
- "What's 'up' with vision-language models? Investigating their struggle to understand spatial relations.", EMNLP, 2023
- REVEAL: Retrieval-Augmented Visual-Language Pre-Training with Multi-Source Multimodal Knowledge, CVPR, 2023
- Grounded Language-Image Pre-training, CVPR, 2022
- How Much Can CLIP Benefit Vision-and-Language Tasks?, ICLR, 2022
UniFine: A Unified and Fine-grained Approach for Zero-shot Vision-Language Understanding
Rui Sun, Zhecan Wang, Haoxuan You, Noel Codella, Kai-Wei Chang, and Shih-Fu Chang, in ACL-Finding, 2023.
QA Sessions: VIRTUAL POSTER SESSION 3: July 12 11:00 AM - July 12 12:30 AM Paper link in the virtual conferenceFull Text BibTeX DetailsDetails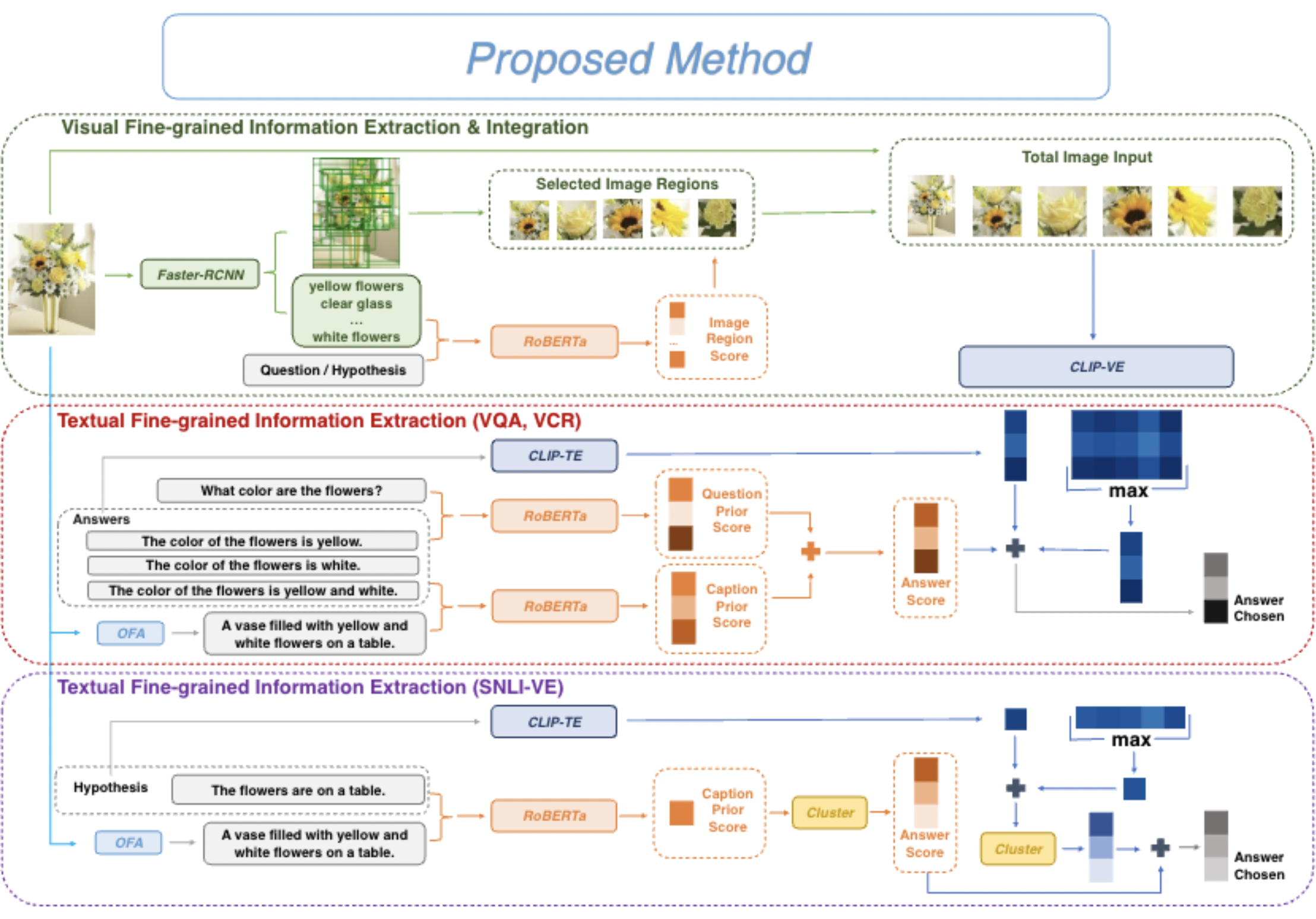
Vision-language tasks, such as VQA, SNLI-VE, and VCR are challenging because they require the model’s reasoning ability to understand the semantics of the visual world and natural language. Supervised methods working for vision-language tasks have been well-studied. However, solving these tasks in a zero-shot setting is less explored. Since Contrastive Language-Image Pre-training (CLIP) has shown remarkable zero-shot performance on image-text matching, previous works utilized its strong zero-shot ability by converting vision-language tasks into an image-text matching problem, and they mainly consider global-level matching (e.g., the whole image or sentence). However, we find visual and textual fine-grained information, e.g., keywords in the sentence and objects in the image, can be fairly informative for semantics understanding. Inspired by this, we propose a unified framework to take advantage of the fine-grained information for zero-shot vision-language learning, covering multiple tasks such as VQA, SNLI-VE, and VCR. Our experiments show that our framework outperforms former zero-shot methods on VQA and achieves substantial improvement on SNLI-VE and VCR. Furthermore, our ablation studies confirm the effectiveness and generalizability of our proposed method.
@inproceedings{sun2023unifine, author = {Sun, Rui and Wang, Zhecan and You, Haoxuan and Codella, Noel and Chang, Kai-Wei and Chang, Shih-Fu}, title = {UniFine: A Unified and Fine-grained Approach for Zero-shot Vision-Language Understanding}, booktitle = {ACL-Finding}, year = {2023}, presentation_id = {https://underline.io/events/395/posters/15279/poster/78004-unifine-a-unified-and-fine-grained-approach-for-zero-shot-vision-language-understanding} }Related Publications
- Where Fact Ends and Fairness Begins: Redefining AI Bias Evaluation through Cognitive Biases, EMNLP-Finding, 2025
- The Male CEO and the Female Assistant: Evaluation and Mitigation of Gender Biases in Text-To-Image Generation of Dual Subjects, ACL, 2025
- JourneyBench: A Challenging One-Stop Vision-Language Understanding Benchmark of Generated Images, NeurIPS (Datasets and Benchmarks Track), 2024
- The Factuality Tax of Diversity-Intervened Text-to-Image Generation: Benchmark and Fact-Augmented Intervention, EMNLP, 2024
- MACAROON: Training Vision-Language Models To Be Your Engaged Partners, EMNLP-Finding, 2024
- Dataset Bias Mitigation in Multiple-Choice Visual Question Answering and Beyond, EMNLP-Findings, 2023
- Resolving Ambiguities in Text-to-Image Generative Models, ACL, 2023
AVATAR: A Parallel Corpus for Java-Python Program Translation
Wasi Ahmad, Md Golam Rahman Tushar, Saikat Chakraborty, and Kai-Wei Chang, in ACL-Finding (short), 2023.
Full Text Code BibTeX DetailsDetails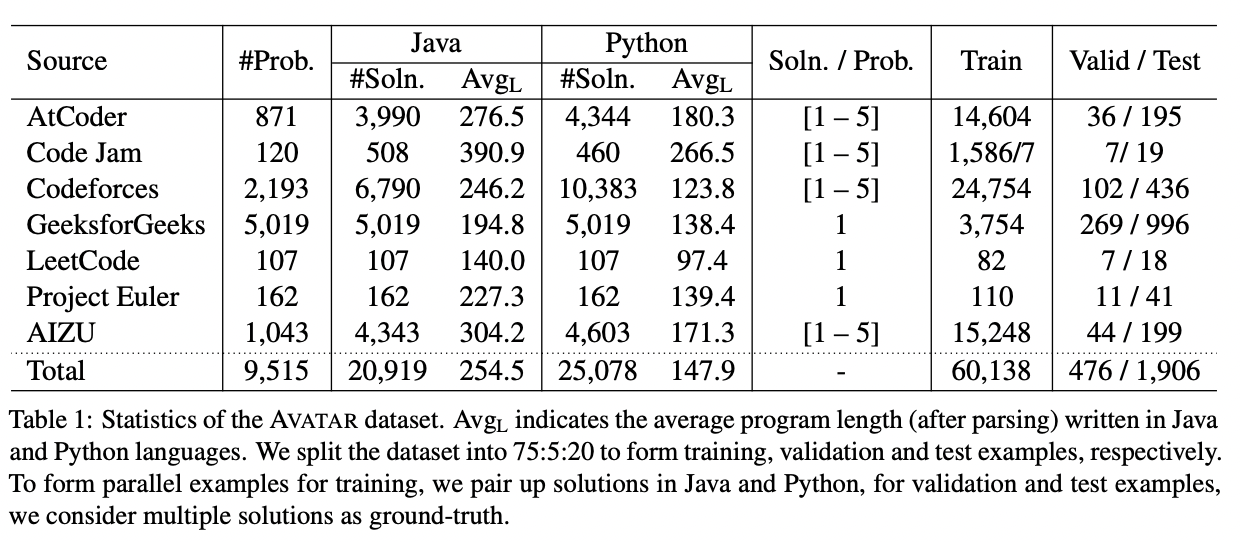
Program translation refers to migrating source code from one programming language to another. It has a tremendous practical value in software development as porting software across different languages is time-consuming and costly. Automating program translation is of paramount importance in software migration, and recently researchers explored unsupervised approaches due to the unavailability of parallel corpora. However, the availability of pre-trained language models for programming languages enable supervised fine-tuning with a small amount of labeled examples. In this work, we present a corpus of 8,475 programming problems and their solutions written in two popular languages, Java and Python. We collect the dataset from competitive programming sites, online platforms, and open source repositories. We present several baselines, including models trained from scratch or pre-trained on large-scale source code collection and fine-tuned on our proposed dataset. Experiment results show that while the models perform relatively well in terms of the lexical match, they lack in generating code that is accurate in terms of syntax and data-flow match.
@inproceedings{ahmad2021avatar, title = {AVATAR: A Parallel Corpus for Java-Python Program Translation}, author = {Ahmad, Wasi and Tushar, Md Golam Rahman and Chakraborty, Saikat and Chang, Kai-Wei}, booktitle = {ACL-Finding (short)}, year = {2023} }Related Publications
- AutoSUIT Bench - Automated Security UnIt Test Benchmark for LLM Coding, ACL-Findings, 2026
- METAL: A Multi-Agent Framework for Chart Generation with Test-Time Scaling, ACL, 2025
- MQT-LLaVA: Matryoshka Query Transformer for Large Vision-Language Models, NeurIPS, 2024
- DACO: Towards Application-Driven and Comprehensive Data Analysis via Code Generation, NeurIPS (Datasets and Benchmarks Track), 2024
- VDebugger: Harnessing Execution Feedback for Debugging Visual Programs, EMNLP-Finding, 2024
- Unified Pre-training for Program Understanding and Generation, NAACL, 2021
- Retrieval Augmented Code Generation and Summarization, EMNLP-Finding, 2021
A Survey of Deep Learning for Mathematical Reasoning
Pan Lu, Liang Qiu, Wenhao Yu, Sean Welleck, and Kai-Wei Chang, in ACL, 2023.
QA Sessions: POSTER SESSION 2: July 10 14:00 AM - July 10 15:30 PM Paper link in the virtual conferenceFull Text BibTeX DetailsDetails
Mathematical reasoning is a fundamental aspect of human intelligence and is applicable in various fields, including science, engineering, finance, and everyday life. The development of artificial intelligence (AI) systems capable of solving math problems and proving theorems has garnered significant interest in the fields of machine learning and natural language processing. For example, mathematics serves as a testbed for aspects of reasoning that are challenging for powerful deep learning models, driving new algorithmic and modeling advances. On the other hand, recent advances in large-scale neural language models have opened up new benchmarks and opportunities to use deep learning for mathematical reasoning. In this survey paper, we review the key tasks, datasets, and methods at the intersection of mathematical reasoning and deep learning over the past decade. We also evaluate existing benchmarks and methods, and discuss future research directions in this domain.
@inproceedings{lu2023survey, author = {Lu, Pan and Qiu, Liang and Yu, Wenhao and Welleck, Sean and Chang, Kai-Wei}, title = {A Survey of Deep Learning for Mathematical Reasoning}, booktitle = {ACL}, year = {2023}, presentation_id = {https://underline.io/events/395/posters/15337/poster/76360-a-survey-of-deep-learning-for-mathematical-reasoning} }On 7/10, Poster Session 2, @lupantech will present a survey of deep learning for mathematical reasoning (#DL4MATH)https://t.co/sT4aUCxBqW
— Kai-Wei Chang (@kaiwei_chang) July 9, 2023Related Publications
- On the Paradox of Learning to Reason from Data, IJCAI, 2023
- Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models, NeurIPS, 2023
- AVIS: Autonomous Visual Information Seeking with Large Language Models, NeurIPS, 2023
- Symbolic Chain-of-Thought Distillation: Small Models Can Also "Think" Step-by-Step, ACL, 2023
- Dynamic Prompt Learning via Policy Gradient for Semi-structured Mathematical Reasoning, ICLR, 2023
- Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering, NeurIPS, 2022
- Semantic Probabilistic Layers for Neuro-Symbolic Learning, NeurIPS, 2022
- Neuro-Symbolic Entropy Regularization, UAI, 2022
Symbolic Chain-of-Thought Distillation: Small Models Can Also "Think" Step-by-Step
Liunian Harold Li, Jack Hessel, Youngjae Yu, Xiang Ren, Kai-Wei Chang, and Yejin Choi, in ACL, 2023.
QA Sessions: POSTER SESSION 1, 7/10 11:00AM-12:30AM Paper link in the virtual conferenceFull Text BibTeX DetailsDetails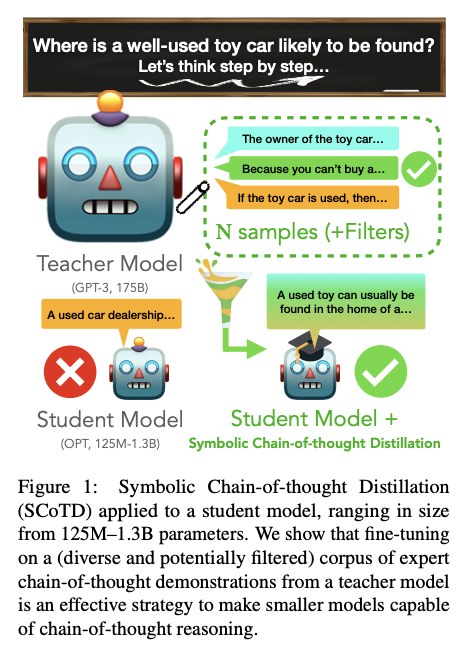
Chain-of-thought prompting (e.g., "Let’s think step-by-step") primes large language models to verbalize rationalization for their predictions. While chain-of-thought can lead to dramatic performance gains, benefits appear to emerge only for sufficiently large models (beyond 50B parameters). We show that orders-of-magnitude smaller models (125M – 1.3B parameters) can still benefit from chain-of-thought prompting. To achieve this, we introduce Symbolic Chain-of-Thought Distillation (SCoTD), a method to train a smaller student model on rationalizations sampled from a significantly larger teacher model. Experiments across several commonsense benchmarks show that: 1) SCoTD enhances the performance of the student model in both supervised and few-shot settings, and especially for challenge sets; 2) sampling many reasoning chains per instance from the teacher is paramount; and 3) after distillation, student chain-of-thoughts are judged by humans as comparable to the teacher, despite orders of magnitude fewer parameters. We test several hypotheses regarding what properties of chain-of-thought samples are important, e.g., diversity vs. teacher likelihood vs. open-endedness. We release our corpus of chain-of-thought samples and code.
@inproceedings{li2023symbolic, title = {Symbolic Chain-of-Thought Distillation: Small Models Can Also "Think" Step-by-Step}, author = {Li, Liunian Harold and Hessel, Jack and Yu, Youngjae and Ren, Xiang and Chang, Kai-Wei and Choi, Yejin}, booktitle = {ACL}, presentation_id = {https://underline.io/events/395/posters/15197/poster/77090-symbolic-chain-of-thought-distillation-small-models-can-also-think-step-by-step?tab=poster}, year = {2023} }Happy to share our #ACL2023 work, Symbolic Chain-of-Thought Distillation (SCoTD) https://t.co/Lw0mBq5iHw!
— Harold (@LiLiunian) July 10, 2023
We show that small models (125M—1.3B parameters) benefit from learning with chains-of-thought (rationalizations) sampled from large models. pic.twitter.com/d1pJi53mIARelated Publications
- On the Paradox of Learning to Reason from Data, IJCAI, 2023
- Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models, NeurIPS, 2023
- AVIS: Autonomous Visual Information Seeking with Large Language Models, NeurIPS, 2023
- A Survey of Deep Learning for Mathematical Reasoning, ACL, 2023
- Dynamic Prompt Learning via Policy Gradient for Semi-structured Mathematical Reasoning, ICLR, 2023
- Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering, NeurIPS, 2022
- Semantic Probabilistic Layers for Neuro-Symbolic Learning, NeurIPS, 2022
- Neuro-Symbolic Entropy Regularization, UAI, 2022
ParaAMR: A Large-Scale Syntactically Diverse Paraphrase Dataset by AMR Back-Translation
Kuan-Hao Huang, Varun Iyer, I.-Hung Hsu, Anoop Kumar, Kai-Wei Chang, and Aram Galstyan, in ACL, 2023.
QA Sessions: POSTER SESSION 3: July 11 09:00 AM - July 11 10:30 AM Paper link in the virtual conferenceFull Text BibTeX Details Area Chair’s AwardDetails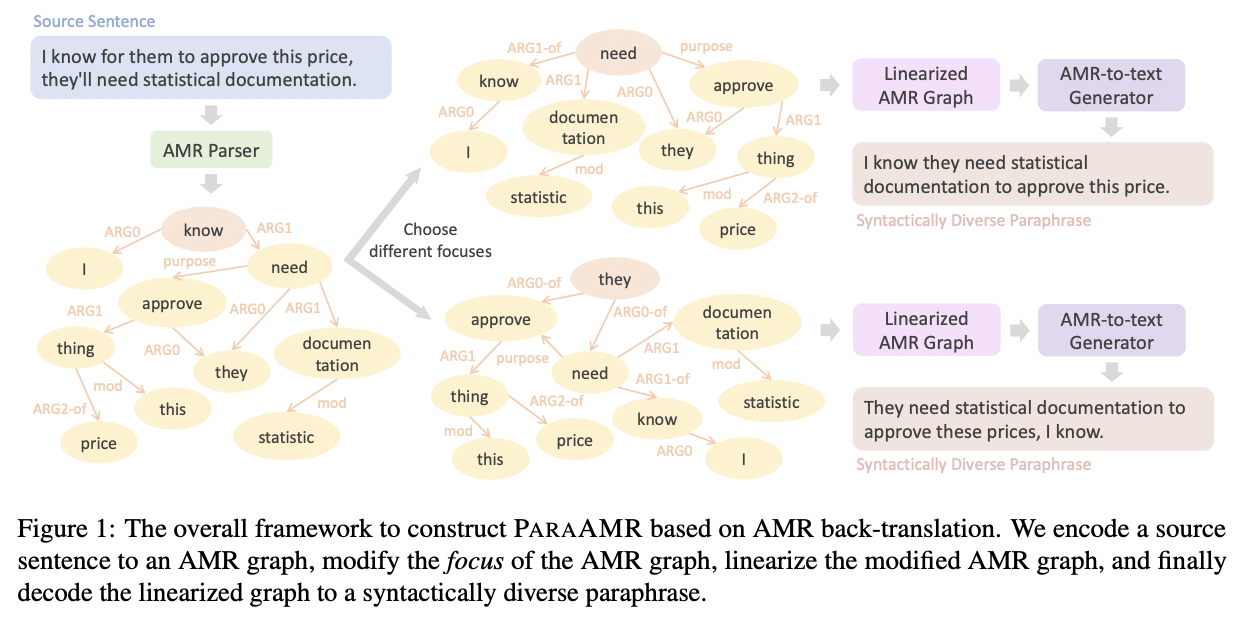
Paraphrase generation is a long-standing task in natural language processing (NLP). Supervised paraphrase generation models, which rely on human-annotated paraphrase pairs, are cost-inefficient and hard to scale up. On the other hand, automatically annotated paraphrase pairs (e.g., by machine back-translation), usually suffer from the lack of syntactic diversity – the generated paraphrase sentences are very similar to the source sentences in terms of syntax. In this work, we present ParaAMR, a large-scale syntactically diverse paraphrase dataset created by abstract meaning representation back-translation. Our quantitative analysis, qualitative examples, and human evaluation demonstrate that the paraphrases of ParaAMR are syntactically more diverse compared to existing large-scale paraphrase datasets while preserving good semantic similarity. In addition, we show that ParaAMR can be used to improve on three NLP tasks: learning sentence embeddings, syntactically controlled paraphrase generation, and data augmentation for few-shot learning. Our results thus showcase the potential of ParaAMR for improving various NLP applications.
@inproceedings{huang2023paraarm, author = {Huang, Kuan-Hao and Iyer, Varun and Hsu, I-Hung and Kumar, Anoop and Chang, Kai-Wei and Galstyan, Aram}, title = {ParaAMR: A Large-Scale Syntactically Diverse Paraphrase Dataset by AMR Back-Translation}, booktitle = {ACL}, presentation_id = {https://underline.io/events/395/posters/15227/poster/76600-paraamr-a-large-scale-syntactically-diverse-paraphrase-dataset-by-amr-back-translation}, year = {2023} }Related Publications
- MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding, ICLR, 2025
- ConTextual: Evaluating Context-Sensitive Text-Rich Visual Reasoning in Large Multimodal Models, ICML, 2024
- CASA: Causality-driven Argument Sufficiency Assessment, NAACL, 2024
- PLUE: Language Understanding Evaluation Benchmark for Privacy Policies in English, ACL (short), 2023
GENEVA: Pushing the Limit of Generalizability for Event Argument Extraction with 100+ Event Types
Tanmay Parekh, I.-Hung Hsu, Kuan-Hao Huang, Kai-Wei Chang, and Nanyun Peng, in ACL, 2023.
QA Sessions: POSTER SESSION 6, 7/12 9:00AM-10:30AM Paper link in the virtual conferenceFull Text Code BibTeX DetailsDetails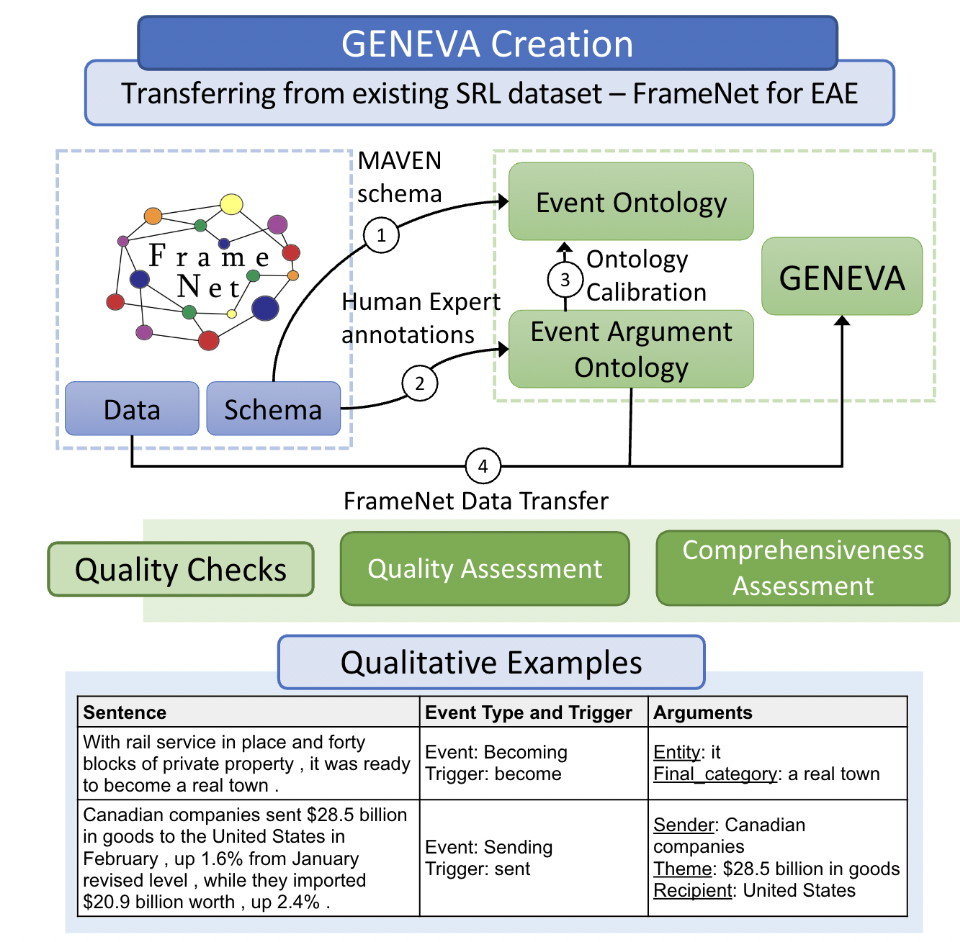
Recent works in Event Argument Extraction (EAE) have focused on improving model generalizability to cater to new events and domains. However, standard benchmarking datasets like ACE and ERE cover less than 40 event types and 25 entity-centric argument roles. Limited diversity and coverage hinder these datasets from adequately evaluating the generalizability of EAE models. In this paper, we first contribute by creating a large and diverse EAE ontology. This ontology is created by transforming FrameNet, a comprehensive semantic role labeling (SRL) dataset for EAE, by exploiting the similarity between these two tasks. Then, exhaustive human expert annotations are collected to build the ontology, concluding with 115 events and 220 argument roles, with a significant portion of roles not being entities. We utilize this ontology to further introduce GENEVA, a diverse generalizability benchmarking dataset comprising four test suites, aimed at evaluating models’ ability to handle limited data and unseen event type generalization. We benchmark six EAE models from various families. The results show that owing to non-entity argument roles, even the best-performing model can only achieve 39% F1 score, indicating how GENEVA provides new challenges for generalization in EAE. Overall, our large and diverse EAE ontology can aid in creating more comprehensive future resources, while GENEVA is a challenging benchmarking dataset encouraging further research for improving generalizability in EAE.
@inproceedings{parekh2023geneva, title = {GENEVA: Pushing the Limit of Generalizability for Event Argument Extraction with 100+ Event Types}, author = {Parekh, Tanmay and Hsu, I-Hung and Huang, Kuan-Hao and Chang, Kai-Wei and Peng, Nanyun}, booktitle = {ACL}, presentation_id = {https://underline.io/events/395/posters/15264/poster/77026-geneva-benchmarking-generalizability-for-event-argument-extraction-with-hundreds-of-event-types-and-argument-roles}, year = {2023} }Related Publications
- DiCoRe: Enhancing Zero-shot Event Detection via Divergent-Convergent LLM Reasoning, EMNLP, 2025
- SNaRe: Domain-aware Data Generation for Low-Resource Event Detection, EMNLP, 2025
- LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory, ICLR, 2025
- SPEED++: A Multilingual Event Extraction Framework for Epidemic Prediction and Preparedness, EMNLP, 2024
- TextEE: Benchmark, Reevaluation, Reflections, and Future Challenges in Event Extraction, ACL-Findings, 2024
- Event Detection from Social Media for Epidemic Prediction, NAACL, 2024
- TAGPRIME: A Unified Framework for Relational Structure Extraction, ACL, 2023
- Enhancing Unsupervised Semantic Parsing with Distributed Contextual Representations, ACL-Finding, 2023
- DEGREE: A Data-Efficient Generative Event Extraction Model, NAACL, 2022
- Intent Classification and Slot Filling for Privacy Policies, ACL, 2021
TAGPRIME: A Unified Framework for Relational Structure Extraction
I.-Hung Hsu, Kuan-Hao Huang, Shuning Zhang, Wenxin Cheng, Prem Natarajan, Kai-Wei Chang, and Nanyun Peng, in ACL, 2023.
QA Sessions: INFORMATION EXTRACTION 1, July 11 16:15 PM Paper link in the virtual conferenceFull Text BibTeX DetailsDetails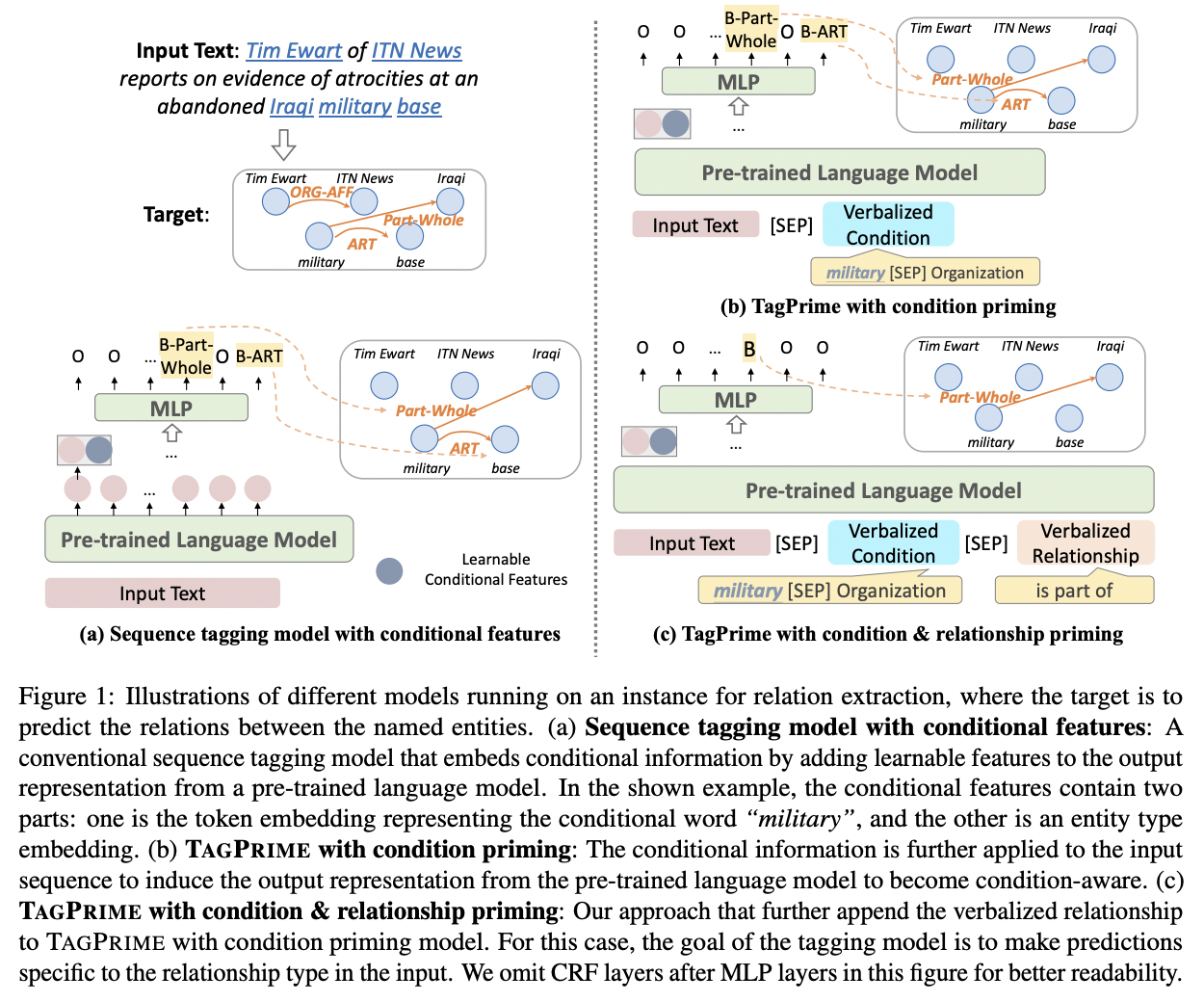
Many tasks in natural language processing require the extraction of relationship information for a given condition, such as event argument extraction, relation extraction, and task-oriented semantic parsing. Recent works usually propose sophisticated models for each task independently and pay less attention to the commonality of these tasks and to have a unified framework for all the tasks. In this work, we propose to take a unified view of all these tasks and introduce TAGPRIME to address relational structure extraction problems. TAGPRIME is a sequence tagging model that appends priming words about the information of the given condition (such as an event trigger) to the input text. With the self-attention mechanism in pre-trained language models, the priming words make the output contextualized representations contain more information about the given condition, and hence become more suitable for extracting specific relationships for the condition. Extensive experiments and analyses on three different tasks that cover ten datasets across five different languages demonstrate the generality and effectiveness of TAGPRIME.
@inproceedings{hsu2023tagprime, author = {Hsu, I-Hung and Huang, Kuan-Hao and Zhang, Shuning and Cheng, Wenxin and Natarajan, Prem and Chang, Kai-Wei and Peng, Nanyun}, title = {TAGPRIME: A Unified Framework for Relational Structure Extraction}, booktitle = {ACL}, presentation_id = {https://underline.io/events/395/sessions/15250/lecture/76330-tagprime-a-unified-framework-for-relational-structure-extraction}, year = {2023} }Related Publications
- DiCoRe: Enhancing Zero-shot Event Detection via Divergent-Convergent LLM Reasoning, EMNLP, 2025
- SNaRe: Domain-aware Data Generation for Low-Resource Event Detection, EMNLP, 2025
- LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory, ICLR, 2025
- SPEED++: A Multilingual Event Extraction Framework for Epidemic Prediction and Preparedness, EMNLP, 2024
- TextEE: Benchmark, Reevaluation, Reflections, and Future Challenges in Event Extraction, ACL-Findings, 2024
- Event Detection from Social Media for Epidemic Prediction, NAACL, 2024
- GENEVA: Pushing the Limit of Generalizability for Event Argument Extraction with 100+ Event Types, ACL, 2023
- Enhancing Unsupervised Semantic Parsing with Distributed Contextual Representations, ACL-Finding, 2023
- DEGREE: A Data-Efficient Generative Event Extraction Model, NAACL, 2022
- Intent Classification and Slot Filling for Privacy Policies, ACL, 2021
PIP: Parse-Instructed Prefix for Syntactically Controlled Paraphrase Generation
Yixin Wan, Kuan-Hao Huang, and Kai-Wei Chang, in ACL-Finding (short), 2023.
QA Sessions: VIRTUAL POSTER SESSION 3: July 12 11:00 AM - July 12 12:30 AM Paper link in the virtual conferenceFull Text BibTeX DetailsDetails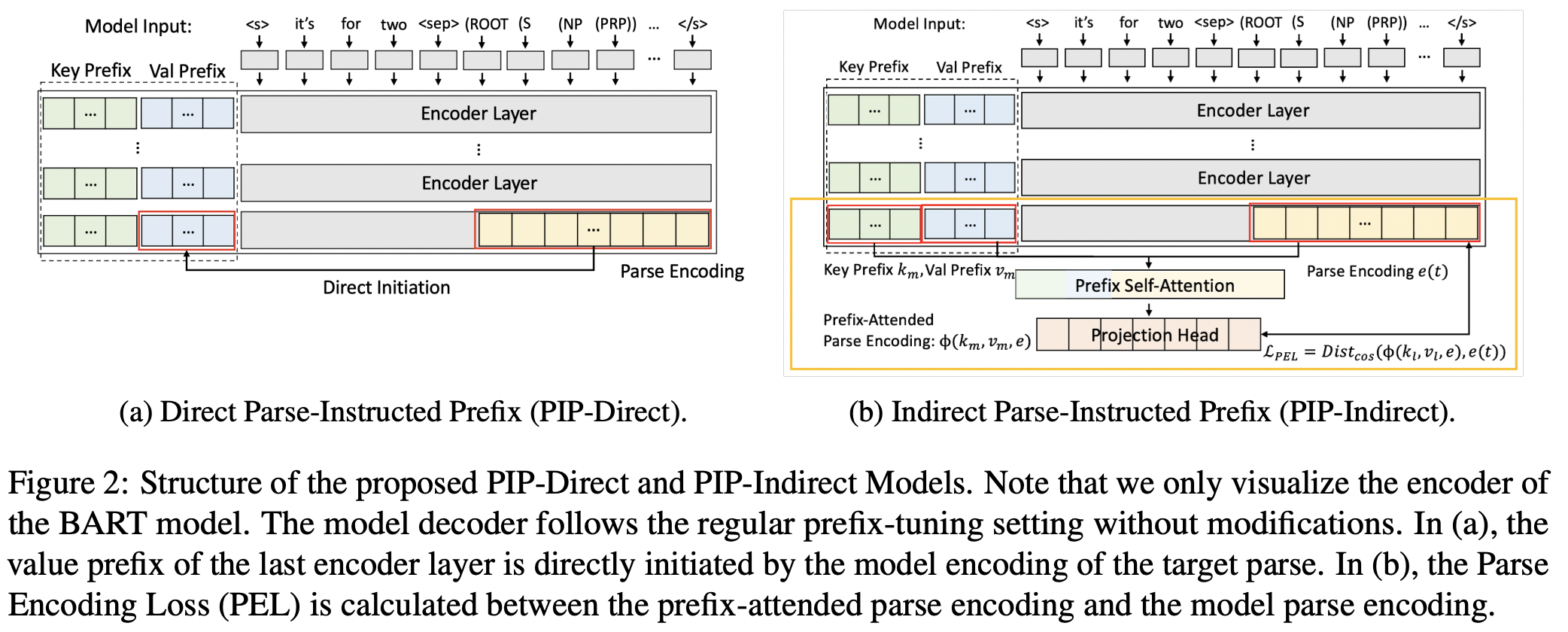
Syntactically controlled paraphrase generation requires language models to generate paraphrases for sentences according to specific syntactic structures. Existing fine-tuning methods for this task are costly as all the parameters of the model need to be updated during the training process. Inspired by recent studies on parameter-efficient learning, we propose Parse-Instructed Prefix (PIP), a novel adaptation of prefix-tuning to tune large pre-trained language models on syntactically controlled paraphrase generation task in a low-data setting with significantly less training cost. We introduce two methods to instruct a model’s encoder prefix to capture syntax-related knowledge: direct initiation (PIP-Direct) and indirect optimization (PIP-Indirect). In contrast to traditional fine-tuning methods for this task, PIP is a compute-efficient alternative with 10 times less learnable parameters. Compared to existing prefix-tuning methods, PIP excels at capturing syntax control information, achieving significantly higher performance at the same level of learnable parameter count.
@inproceedings{wan2023pip, author = {Wan, Yixin and Huang, Kuan-Hao and Chang, Kai-Wei}, title = {PIP: Parse-Instructed Prefix for Syntactically Controlled Paraphrase Generation}, booktitle = {ACL-Finding (short)}, presentation_id = {https://underline.io/events/395/posters/15279/poster/77944-pip-parse-instructed-prefix-for-syntactically-controlled-paraphrase-generation}, year = {2023} }Related Publications
- Dynamic Generation of Multi LLM Agents Communication Topologies with Graph Diffusion Models, ACL, 2026
- Magnet: Multi-turn Tool-use Data Synthesis and Distillation via Graph Translation, ACL, 2025
- Dynosaur: A Dynamic Growth Paradigm for Instruction-Tuning Data Curation, EMNLP, 2023
- Active Instruction Tuning: Improving Cross-Task Generalization by Training on Prompt Sensitive Tasks, EMNLP, 2023
Enhancing Unsupervised Semantic Parsing with Distributed Contextual Representations
Zixuan Ling, Xiaoqing Zheng, Jianhan Xu, Jinshu Lin, Kai-Wei Chang, Cho-Jui Hsieh, and Xuanjing Huang, in ACL-Finding, 2023.
QA Sessions: VIRTUAL POSTER SESSION 3: July 12 11:00 AM - July 12 12:30 AM Paper link in the virtual conferenceBibTeX DetailsDetailsWe extend a non-parametric Bayesian model of (Titov and Klementiev, 2011) to deal with homonymy and polysemy by leveraging distributed contextual word and phrase representations pre-trained on a large collection of unlabelled texts. Then, unsupervised semantic parsing is performed by decomposing sentences into fragments, clustering the fragments to abstract away syntactic variations of the same meaning, and predicting predicate-argument relations between the fragments. To better model the statistical dependencies between predicates and their arguments, we further conduct a hierarchical Pitman-Yor process. An improved Metropolis-Hastings merge-split sampler is proposed to speed up the mixing and convergence of Markov chains by leveraging pre-trained distributed representations. The experimental results show that the models achieve better accuracy on both question-answering and relation extraction tasks.
@inproceedings{ling2023enhancing, author = {Ling, Zixuan and Zheng, Xiaoqing and Xu, Jianhan and Lin, Jinshu and Chang, Kai-Wei and Hsieh, Cho-Jui and Huang, Xuanjing}, title = {Enhancing Unsupervised Semantic Parsing with Distributed Contextual Representations}, booktitle = {ACL-Finding}, presentation_id = {https://underline.io/events/395/posters/15279/poster/77281-enhancing-unsupervised-semantic-parsing-with-distributed-contextual-representations?tab=video}, year = {2023} }Related Publications
- DiCoRe: Enhancing Zero-shot Event Detection via Divergent-Convergent LLM Reasoning, EMNLP, 2025
- SNaRe: Domain-aware Data Generation for Low-Resource Event Detection, EMNLP, 2025
- LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory, ICLR, 2025
- SPEED++: A Multilingual Event Extraction Framework for Epidemic Prediction and Preparedness, EMNLP, 2024
- TextEE: Benchmark, Reevaluation, Reflections, and Future Challenges in Event Extraction, ACL-Findings, 2024
- Event Detection from Social Media for Epidemic Prediction, NAACL, 2024
- GENEVA: Pushing the Limit of Generalizability for Event Argument Extraction with 100+ Event Types, ACL, 2023
- TAGPRIME: A Unified Framework for Relational Structure Extraction, ACL, 2023
- DEGREE: A Data-Efficient Generative Event Extraction Model, NAACL, 2022
- Intent Classification and Slot Filling for Privacy Policies, ACL, 2021