UCLA-NLP presents 3 long papers, 3 short papers, 1 tutorial and 1 demo the at EMNLP 2019 and 2 papers at CoNLL 2019.
Tutorial: Bias and Fairness in Natual Language Processing
Instructors: Kai-Wei Chang, Vicente Ordonez, Margaret Mitchell, Vinodkumar Prabhakaran
Mitigating Gender Bias in Distilled Language Models via Counterfactual Role Reversal
Umang Gupta, Jwala Dhamala, Varun Kumar, Apurv Verma, Yada Pruksachatkun, Satyapriya Krishna, Rahul Gupta, Kai-Wei Chang, Greg Ver Steeg, and Aram Galstyan, in ACL Finding, 2022.
Language models excel at generating coherent text, and model compression techniques such as knowledge distillation have enabled their use in resource-constrained settings. However, these models can be biased in multiple ways, including the unfounded association of male and female genders with gender-neutral professions. Therefore, knowledge distillation without any fairness constraints may preserve or exaggerate the teacher model’s biases onto the distilled model. To this end, we present a novel approach to mitigate gender disparity in text generation by learning a fair model during knowledge distillation. We propose two modifications to the base knowledge distillation based on counterfactual role reversal – modifying teacher probabilities and augmenting the training set. We evaluate gender polarity across professions in open-ended text generated from the resulting distilled and finetuned GPT-2models and demonstrate a substantial reduction in gender disparity with only a minor compromise in utility. Finally, we observe that language models that reduce gender polarity in language generation do not improve embedding fairness or downstream classification fairness.
@inproceedings{gupta2022equitable, title = {Mitigating Gender Bias in Distilled Language Models via Counterfactual Role Reversal}, author = {Gupta, Umang and Dhamala, Jwala and Kumar, Varun and Verma, Apurv and Pruksachatkun, Yada and Krishna, Satyapriya and Gupta, Rahul and Chang, Kai-Wei and Steeg, Greg Ver and Galstyan, Aram}, booktitle = {ACL Finding}, year = {2022} }Harms of Gender Exclusivity and Challenges in Non-Binary Representation in Language Technologies
Sunipa Dev, Masoud Monajatipoor, Anaelia Ovalle, Arjun Subramonian, Jeff Phillips, and Kai-Wei Chang, in EMNLP, 2021.
Gender is widely discussed in the context of language tasks and when examining the stereotypes propagated by language models. However, current discussions primarily treat gender as binary, which can perpetuate harms such as the cyclical erasure of non-binary gender identities. These harms are driven by model and dataset biases, which are consequences of the non-recognition and lack of understanding of non-binary genders in society. In this paper, we explain the complexity of gender and language around it, and survey non-binary persons to understand harms associated with the treatment of gender as binary in English language technologies. We also detail how current language representations (e.g., GloVe, BERT) capture and perpetuate these harms and related challenges that need to be acknowledged and addressed for representations to equitably encode gender information.
@inproceedings{dev2021harms, title = {Harms of Gender Exclusivity and Challenges in Non-Binary Representation in Language Technologies}, author = {Dev, Sunipa and Monajatipoor, Masoud and Ovalle, Anaelia and Subramonian, Arjun and Phillips, Jeff and Chang, Kai-Wei}, presentation_id = {https://underline.io/events/192/sessions/7788/lecture/37320-harms-of-gender-exclusivity-and-challenges-in-non-binary-representation-in-language-technologies}, blog_url = {https://uclanlp.medium.com/harms-of-gender-exclusivity-and-challenges-in-non-binary-representation-in-language-technologies-5f89891b5aee}, booktitle = {EMNLP}, year = {2021} }Gender Bias in Multilingual Embeddings and Cross-Lingual Transfer
Jieyu Zhao, Subhabrata Mukherjee, Saghar Hosseini, Kai-Wei Chang, and Ahmed Hassan Awadallah, in ACL, 2020.
Multilingual representations embed words from many languages into a single semantic space such that words with similar meanings are close to each other regardless of the language. These embeddings have been widely used in various settings, such as cross-lingual transfer, where a natural language processing (NLP) model trained on one language is deployed to another language. While the cross-lingual transfer techniques are powerful, they carry gender bias from the source to target languages. In this paper, we study gender bias in multilingual embeddings and how it affects transfer learning for NLP applications. We create a multilingual dataset for bias analysis and propose several ways for quantifying bias in multilingual representations from both the intrinsic and extrinsic perspectives. Experimental results show that the magnitude of bias in the multilingual representations changes differently when we align the embeddings to different target spaces and that the alignment direction can also have an influence on the bias in transfer learning. We further provide recommendations for using the multilingual word representations for downstream tasks.
@inproceedings{zhao2020gender, author = {Zhao, Jieyu and Mukherjee, Subhabrata and Hosseini, Saghar and Chang, Kai-Wei and Awadallah, Ahmed Hassan}, title = {Gender Bias in Multilingual Embeddings and Cross-Lingual Transfer}, booktitle = {ACL}, year = {2020}, presentation_id = {https://virtual.acl2020.org/paper_main.260.html} }Examining Gender Bias in Languages with Grammatical Gender
Pei Zhou, Weijia Shi, Jieyu Zhao, Kuan-Hao Huang, Muhao Chen, Ryan Cotterell, and Kai-Wei Chang, in EMNLP, 2019.
Recent studies have shown that word embeddings exhibit gender bias inherited from the training corpora. However, most studies to date have focused on quantifying and mitigating such bias only in English. These analyses cannot be directly extended to languages that exhibit morphological agreement on gender, such as Spanish and French. In this paper, we propose new metrics for evaluating gender bias in word embeddings of these languages and further demonstrate evidence of gender bias in bilingual embeddings which align these languages with English. Finally, we extend an existing approach to mitigate gender bias in word embeddings under both monolingual and bilingual settings. Experiments on modified Word Embedding Association Test, word similarity, word translation, and word pair translation tasks show that the proposed approaches effectively reduce the gender bias while preserving the utility of the embeddings.
@inproceedings{zhou2019examining, author = {Zhou, Pei and Shi, Weijia and Zhao, Jieyu and Huang, Kuan-Hao and Chen, Muhao and Cotterell, Ryan and Chang, Kai-Wei}, title = {Examining Gender Bias in Languages with Grammatical Gender}, booktitle = {EMNLP}, year = {2019} }Balanced Datasets Are Not Enough: Estimating and Mitigating Gender Bias in Deep Image Representations
Tianlu Wang, Jieyu Zhao, Mark Yatskar, Kai-Wei Chang, and Vicente Ordonez, in ICCV, 2019.
In this work, we present a framework to measure and mitigate intrinsic biases with respect to protected variables –such as gender– in visual recognition tasks. We show that trained models significantly amplify the association of target labels with gender beyond what one would expect from biased datasets. Surprisingly, we show that even when datasets are balanced such that each label co-occurs equally with each gender, learned models amplify the association between labels and gender, as much as if data had not been balanced! To mitigate this, we adopt an adversarial approach to remove unwanted features corresponding to protected variables from intermediate representations in a deep neural network – and provide a detailed analysis of its effectiveness. Experiments on two datasets: the COCO dataset (objects), and the imSitu dataset (actions), show reductions in gender bias amplification while maintaining most of the accuracy of the original models.
@inproceedings{wang2019balanced, author = {Wang, Tianlu and Zhao, Jieyu and Yatskar, Mark and Chang, Kai-Wei and Ordonez, Vicente}, title = {Balanced Datasets Are Not Enough: Estimating and Mitigating Gender Bias in Deep Image Representations}, booktitle = {ICCV}, year = {2019} }Gender Bias in Contextualized Word Embeddings
Jieyu Zhao, Tianlu Wang, Mark Yatskar, Ryan Cotterell, Vicente Ordonez, and Kai-Wei Chang, in NAACL (short), 2019.
Despite the great success of contextualized word embeddings on downstream applications, these representations potentially embed the societal biases exhibited in their training corpus. In this paper, we quantify, analyze and mitigate the gender bias exhibited in ELMo contextualized word vectors. We first demonstrate that the vectors encode and propagate information about genders unequally and then conduct a principal component analysis to visualize the geometry of the gender information in the embeddings. Then we show that ELMo works unequally well for men and women in down-stream tasks. Finally, we explore a variety of methods to remove such gender bias and demonstrate that it can be reduced through data augmentation.
@inproceedings{zhao2019gender, author = {Zhao, Jieyu and Wang, Tianlu and Yatskar, Mark and Cotterell, Ryan and Ordonez, Vicente and Chang, Kai-Wei}, title = {Gender Bias in Contextualized Word Embeddings}, booktitle = {NAACL (short)}, year = {2019} }Learning Gender-Neutral Word Embeddings
Jieyu Zhao, Yichao Zhou, Zeyu Li, Wei Wang, and Kai-Wei Chang, in EMNLP (short), 2018.
Word embeddings have become a fundamental component in a wide range of Natu-ral Language Processing (NLP) applications.However, these word embeddings trained onhuman-generated corpora inherit strong gen-der stereotypes that reflect social constructs.In this paper, we propose a novel word em-bedding model, De-GloVe, that preserves gen-der information in certain dimensions of wordvectors while compelling other dimensions tobe free of gender influence. Quantitative andqualitative experiments demonstrate that De-GloVe successfully isolates gender informa-tion without sacrificing the functionality of theembedding model.
@inproceedings{zhao2018learning, author = {Zhao, Jieyu and Zhou, Yichao and Li, Zeyu and Wang, Wei and Chang, Kai-Wei}, title = {Learning Gender-Neutral Word Embeddings}, booktitle = {EMNLP (short)}, year = {2018} }Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings
Tolga Bolukbasi, Kai-Wei Chang, James Zou, Venkatesh Saligrama, and Adam Kalai, in NeurIPS, 2016.
The blind application of machine learning runs the risk of amplifying biases present in data. Such a danger is facing us with word embedding, a popular framework to represent text data as vectors which has been used in many machine learning and natural language processing tasks. We show that even word embeddings trained on Google News articles exhibit female/male gender stereotypes to a disturbing extent. This raises concerns because their widespread use, as we describe, often tends to amplify these biases. Geometrically, gender bias is first shown to be captured by a direction in the word embedding. Second, gender neutral words are shown to be linearly separable from gender definition words in the word embedding. Using these properties, we provide a methodology for modifying an embedding to remove gender stereotypes, such as the association between between the words receptionist and female, while maintaining desired associations such as between the words queen and female. We define metrics to quantify both direct and indirect gender biases in embeddings, and develop algorithms to "debias" the embedding. Using crowd-worker evaluation as well as standard benchmarks, we empirically demonstrate that our algorithms significantly reduce gender bias in embeddings while preserving the its useful properties such as the ability to cluster related concepts and to solve analogy tasks. The resulting embeddings can be used in applications without amplifying gender bias.
@inproceedings{bolukbasi2016man, author = {Bolukbasi, Tolga and Chang, Kai-Wei and Zou, James and Saligrama, Venkatesh and Kalai, Adam}, title = {Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings}, booktitle = {NeurIPS}, year = {2016} }
Measuring Fairness of Text Classifiers via Prediction Sensitivity
Satyapriya Krishna, Rahul Gupta, Apurv Verma, Jwala Dhamala, Yada Pruksachatkun, and Kai-Wei Chang, in ACL, 2022.
With the rapid growth in language processing applications, fairness has emerged as an important consideration in data-driven solutions. Although various fairness definitions have been explored in the recent literature, there is lack of consensus on which metrics most accurately reflect the fairness of a system. In this work, we propose a new formulation : ACCUMULATED PREDICTION SENSITIVITY, which measures fairness in machine learning models based on the model’s prediction sensitivity to perturbations in input features. The metric attempts to quantify the extent to which a single prediction depends on a protected attribute, where the protected attribute encodes the membership status of an individual in a protected group. We show that the metric can be theoretically linked with a specific notion of group fairness (statistical parity) and individual fairness. It also correlates well with humans’ perception of fairness. We conduct experiments on two text classification datasets : JIGSAW TOXICITY, and BIAS IN BIOS, and evaluate the correlations between metrics and manual annotations on whether the model produced a fair outcome. We observe that the proposed fairness metric based on prediction sensitivity is statistically significantly more correlated with human annotation than the existing counterfactual fairness metric.
@inproceedings{krishna2022measuring, title = {Measuring Fairness of Text Classifiers via Prediction Sensitivity}, author = {Krishna, Satyapriya and Gupta, Rahul and Verma, Apurv and Dhamala, Jwala and Pruksachatkun, Yada and Chang, Kai-Wei}, booktitle = {ACL}, year = {2022} }Does Robustness Improve Fairness? Approaching Fairness with Word Substitution Robustness Methods for Text Classification
Yada Pruksachatkun, Satyapriya Krishna, Jwala Dhamala, Rahul Gupta, and Kai-Wei Chang, in ACL-Finding, 2021.
Existing bias mitigation methods to reduce disparities in model outcomes across cohorts have focused on data augmentation, debiasing model embeddings, or adding fairness-based optimization objectives during training. Separately, certified word substitution robustness methods have been developed to decrease the impact of spurious features and synonym substitutions on model predictions. While their end goals are different, they both aim to encourage models to make the same prediction for certain changes in the input. In this paper, we investigate the utility of certified word substitution robustness methods to improve equality of odds and equality of opportunity on multiple text classification tasks. We observe that certified robustness methods improve fairness, and using both robustness and bias mitigation methods in training results in an improvement in both fronts.
@inproceedings{pruksachatkun2021robustness, title = {Does Robustness Improve Fairness? Approaching Fairness with Word Substitution Robustness Methods for Text Classification}, author = {Pruksachatkun, Yada and Krishna, Satyapriya and Dhamala, Jwala and Gupta, Rahul and Chang, Kai-Wei}, booktitle = {ACL-Finding}, year = {2021} }LOGAN: Local Group Bias Detection by Clustering
Jieyu Zhao and Kai-Wei Chang, in EMNLP (short), 2020.
Machine learning techniques have been widely used in natural language processing (NLP). However, as revealed by many recent studies, machine learning models often inherit and amplify the societal biases in data. Various metrics have been proposed to quantify biases in model predictions. In particular, several of them evaluate disparity in model performance between protected groups and advantaged groups in the test corpus. However, we argue that evaluating bias at the corpus level is not enough for understanding how biases are embedded in a model. In fact, a model with similar aggregated performance between different groups on the entire data may behave differently on instances in a local region. To analyze and detect such local bias, we propose LOGAN, a new bias detection technique based on clustering. Experiments on toxicity classification and object classification tasks show that LOGAN identifies bias in a local region and allows us to better analyze the biases in model predictions.
@inproceedings{zhao2020logan, author = {Zhao, Jieyu and Chang, Kai-Wei}, title = {LOGAN: Local Group Bias Detection by Clustering}, booktitle = {EMNLP (short)}, presentation_id = {https://virtual.2020.emnlp.org/paper_main.2886.html}, year = {2020} }Towards Understanding Gender Bias in Relation Extraction
Andrew Gaut, Tony Sun, Shirlyn Tang, Yuxin Huang, Jing Qian, Mai ElSherief, Jieyu Zhao, Diba Mirza, Elizabeth Belding, Kai-Wei Chang, and William Yang Wang, in ACL, 2020.
Recent developments in Neural Relation Extraction (NRE) have made significant strides towards automated knowledge base construction. While much attention has been dedicated towards improvements in accuracy, there have been no attempts in the literature to evaluate social biases exhibited in NRE systems. In this paper, we create WikiGenderBias, a distantly supervised dataset composed of over 45,000 sentences including a 10% human annotated test set for the purpose of analyzing gender bias in relation extraction systems. We find that when extracting spouse and hypernym (i.e., occupation) relations, an NRE system performs differently when the gender of the target entity is different. However, such disparity does not appear when extracting relations such as birth date or birth place. We also analyze two existing bias mitigation techniques, word embedding debiasing and data augmentation. Unfortunately, due to NRE models relying heavily on surface level cues, we find that existing bias mitigation approaches have a negative effect on NRE. Our analysis lays groundwork for future quantifying and mitigating bias in relation extraction.
@inproceedings{gaut2020towards, author = {Gaut, Andrew and Sun, Tony and Tang, Shirlyn and Huang, Yuxin and Qian, Jing and ElSherief, Mai and Zhao, Jieyu and Mirza, Diba and Belding, Elizabeth and Chang, Kai-Wei and Wang, William Yang}, title = {Towards Understanding Gender Bias in Relation Extraction}, booktitle = {ACL}, year = {2020}, presentation_id = {https://virtual.acl2020.org/paper_main.265.html} }Mitigating Gender Bias Amplification in Distribution by Posterior Regularization
Shengyu Jia, Tao Meng, Jieyu Zhao, and Kai-Wei Chang, in ACL (short), 2020.
Advanced machine learning techniques have boosted the performance of natural language processing. Nevertheless, recent studies, e.g., Zhao et al. (2017) show that these techniques inadvertently capture the societal bias hiddenin the corpus and further amplify it. However,their analysis is conducted only on models’ top predictions. In this paper, we investigate thegender bias amplification issue from the distribution perspective and demonstrate that thebias is amplified in the view of predicted probability distribution over labels. We further propose a bias mitigation approach based on posterior regularization. With little performance loss, our method can almost remove the bias amplification in the distribution. Our study sheds the light on understanding the bias amplification.
@inproceedings{jia2020mitigating, author = {Jia, Shengyu and Meng, Tao and Zhao, Jieyu and Chang, Kai-Wei}, title = {Mitigating Gender Bias Amplification in Distribution by Posterior Regularization}, booktitle = {ACL (short)}, year = {2020}, presentation_id = {https://virtual.acl2020.org/paper_main.264.html} }Mitigating Gender in Natural Language Processing: Literature Review
Tony Sun, Andrew Gaut, Shirlyn Tang, Yuxin Huang, Mai ElSherief, Jieyu Zhao, Diba Mirza, Kai-Wei Chang, and William Yang Wang, in ACL, 2019.
As Natural Language Processing (NLP) and Machine Learning (ML) tools rise in popularity, it becomes increasingly vital to recognize the role they play in shaping societal biases and stereotypes. Although NLP models have shown success in modeling various applications, they propagate and may even amplify gender bias found in text corpora. While the study of bias in artificial intelligence is not new, methods to mitigate gender bias in NLP are relatively nascent. In this paper, we review contemporary studies on recognizing and mitigating gender bias in NLP. We discuss gender bias based on four forms of representation bias and analyze methods recognizing gender bias. Furthermore, we discuss the advantages and drawbacks of existing gender debiasing methods. Finally, we discuss future studies for recognizing and mitigating gender bias in NLP.
@inproceedings{sun2019mitigating, author = {Sun, Tony and Gaut, Andrew and Tang, Shirlyn and Huang, Yuxin and ElSherief, Mai and Zhao, Jieyu and Mirza, Diba and Chang, Kai-Wei and Wang, William Yang}, title = {Mitigating Gender in Natural Language Processing: Literature Review}, booktitle = {ACL}, vimeo_id = {384482151}, year = {2019} }Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods
Jieyu Zhao, Tianlu Wang, Mark Yatskar, Vicente Ordonez, and Kai-Wei Chang, in NAACL (short), 2018.
In this paper, we introduce a new benchmark for co-reference resolution focused on gender bias, WinoBias. Our corpus contains Winograd-schema style sentences with entities corresponding to people referred by their occupation (e.g. the nurse, the doctor, the carpenter). We demonstrate that a rule-based, a feature-rich, and a neural coreference system all link gendered pronouns to pro-stereotypical entities with higher accuracy than anti-stereotypical entities, by an average difference of 21.1 in F1 score. Finally, we demonstrate a data-augmentation approach that, in combination with existing word-embedding debiasing techniques, removes the bias demonstrated by these systems in WinoBias without significantly affecting their performance on existing datasets.
@inproceedings{zhao2018gender, author = {Zhao, Jieyu and Wang, Tianlu and Yatskar, Mark and Ordonez, Vicente and Chang, Kai-Wei}, title = {Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods}, booktitle = {NAACL (short)}, press_url = {https://www.stitcher.com/podcast/matt-gardner/nlp-highlights/e/55861936}, year = {2018} }Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints
Jieyu Zhao, Tianlu Wang, Mark Yatskar, Vicente Ordonez, and Kai-Wei Chang, in EMNLP, 2017.
Language is increasingly being used to define rich visual recognition problems with supporting image collections sourced from the web. Structured prediction models are used in these tasks to take advantage of correlations between co-occuring labels and visual input but risk inadvertently encoding social biases found in web corpora. In this work, we study data and models associated with multilabel object classification and visual semantic role labeling. We find that (a) datasets for these tasks contain significant gender bias and (b) models trained on these datasets further amplify existing bias. For example, the activity cooking is over 33% more likely to involve females than males in a training set, but a trained model amplifies the disparity to 68% at test time. We propose to inject corpus-level constraints for calibrating existing structured prediction models and design an algorithm based on Lagrangian relaxation for the resulting inference problems. Our method results in no performance loss for the underlying recognition task but decreases the magnitude of bias amplification by 33.3% and 44.9% for multilabel classification and visual semantic role labeling, respectively.
@inproceedings{zhao2017men, author = {Zhao, Jieyu and Wang, Tianlu and Yatskar, Mark and Ordonez, Vicente and Chang, Kai-Wei}, title = {Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints}, booktitle = {EMNLP}, year = {2017} }
Natural language processing techniques play important roles in our daily life. Despite these methods being successful in various applications, they run the risk of exploiting and reinforcing the societal biases (e.g. gender bias) that are present in the underlying data. For instance, an automatic resume filtering system may inadvertently select candidates based on their gender and race due to implicit associations between applicant names and job titles, causing the system to perpetuate unfairness potentially. In this talk, I will describe a collection of results that quantify and control implicit societal biases in a wide spectrum of vision and language tasks, including word embeddings, coreference resolution, and visual semantic role labeling. These results lead to greater control of NLP systems to be socially responsible and accountable.
- Part1: Cognitive Biases / Data Biases / Bias laundering
- Part2: Bias in NLP and Mitigation Approaches
- Part3: Building Fair and Robust Representations for Vision and Language
Papers
Target Language-Aware Constrained Inference for Cross-lingual Dependency Parsing
Tao Meng, Nanyun Peng, and Kai-Wei Chang, in EMNLP, 2019.
Full Text Poster Code BibTeX DetailsDetails
Prior work on cross-lingual dependency parsing often focuses on capturing the commonalities between source and target languages and overlooks the potential of leveraging linguistic properties of the languages to facilitate the transfer. In this paper, we show that weak supervisions of linguistic knowledge for the target languages can improve a cross-lingual graph-based dependency parser substantially. Specifically, we explore several types of corpus linguistic statistics and compile them into corpus-wise constraints to guide the inference process during the test time. We adapt two techniques, Lagrangian relaxation and posterior regularization, to conduct inference with corpus-statistics constraints. Experiments show that the Lagrangian relaxation and posterior regularization inference improve the performances on 15 and 17 out of 19 target languages, respectively. The improvements are especially significant for target languages that have different word order features from the source language.
@inproceedings{meng2019target, author = {Meng, Tao and Peng, Nanyun and Chang, Kai-Wei}, title = {Target Language-Aware Constrained Inference for Cross-lingual Dependency Parsing}, booktitle = {EMNLP}, year = {2019} }(3/5) Interested in cross-lingual transfer? Check out 6) our talk on learning language-agnostic representations for parsing on CoNLL https://t.co/IwiRV6k0SW and 7) poster on injecting corpus-level constraints for cross-lingual transfer https://t.co/dcKLHBPM6w (Tue).
— Kai-Wei Chang (@kaiwei_chang) November 3, 2019Related Publications
- LiveCLKTBench: Towards Reliable Evaluation of Cross-Lingual Knowledge Transfer in Multilingual LLMs, ACL, 2026
- Contextual Label Projection for Cross-Lingual Structured Prediction, NAACL, 2024
- Multilingual Generative Language Models for Zero-Shot Cross-Lingual Event Argument Extraction, ACL, 2022
- Evaluating the Values of Sources in Transfer Learning, NAACL, 2021
- Improving Zero-Shot Cross-Lingual Transfer Learning via Robust Training, EMNLP, 2021
- Syntax-augmented Multilingual BERT for Cross-lingual Transfer, ACL, 2021
- GATE: Graph Attention Transformer Encoder for Cross-lingual Relation and Event Extraction, AAAI, 2021
- Cross-Lingual Dependency Parsing by POS-Guided Word Reordering, EMNLP-Finding, 2020
- Cross-lingual Dependency Parsing with Unlabeled Auxiliary Languages, CoNLL, 2019
- On Difficulties of Cross-Lingual Transfer with Order Differences: A Case Study on Dependency Parsing, NAACL, 2019
Examining Gender Bias in Languages with Grammatical Gender
Pei Zhou, Weijia Shi, Jieyu Zhao, Kuan-Hao Huang, Muhao Chen, Ryan Cotterell, and Kai-Wei Chang, in EMNLP, 2019.
Full Text Poster Code BibTeX DetailsDetails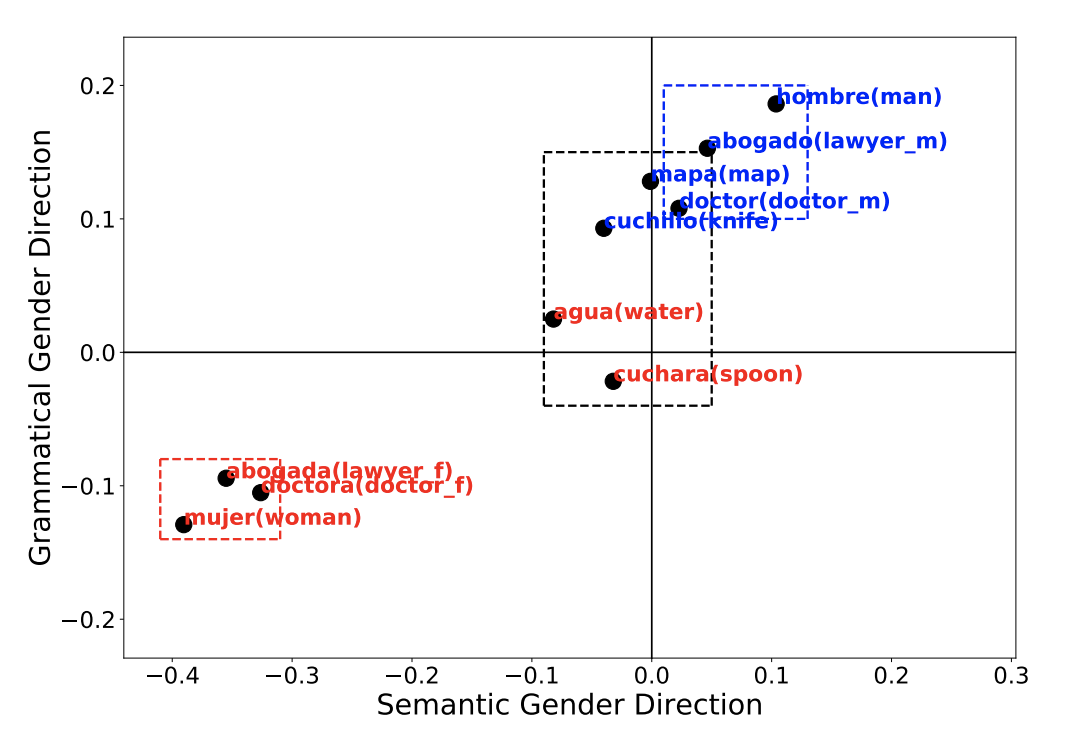
Recent studies have shown that word embeddings exhibit gender bias inherited from the training corpora. However, most studies to date have focused on quantifying and mitigating such bias only in English. These analyses cannot be directly extended to languages that exhibit morphological agreement on gender, such as Spanish and French. In this paper, we propose new metrics for evaluating gender bias in word embeddings of these languages and further demonstrate evidence of gender bias in bilingual embeddings which align these languages with English. Finally, we extend an existing approach to mitigate gender bias in word embeddings under both monolingual and bilingual settings. Experiments on modified Word Embedding Association Test, word similarity, word translation, and word pair translation tasks show that the proposed approaches effectively reduce the gender bias while preserving the utility of the embeddings.
@inproceedings{zhou2019examining, author = {Zhou, Pei and Shi, Weijia and Zhao, Jieyu and Huang, Kuan-Hao and Chen, Muhao and Cotterell, Ryan and Chang, Kai-Wei}, title = {Examining Gender Bias in Languages with Grammatical Gender}, booktitle = {EMNLP}, year = {2019} }Our EMNLP paper "Examining Gender Bias in Languages with Grammatical Gender" is on https://t.co/qVLvrfXv8O (w/@WeijiaShi2 @jieyuzhao11 @kuanhao_ @muhao_chen @ryandcotterell @kaiwei_chang). We separate semantic and grammatical gender info and found asymmetry between genders. pic.twitter.com/qTSN2RpgCE
— Pei Zhou (@peizNLP) September 6, 2019Related Publications
- Mitigating Gender Bias in Distilled Language Models via Counterfactual Role Reversal, ACL Finding, 2022
- Harms of Gender Exclusivity and Challenges in Non-Binary Representation in Language Technologies, EMNLP, 2021
- Gender Bias in Multilingual Embeddings and Cross-Lingual Transfer, ACL, 2020
- Balanced Datasets Are Not Enough: Estimating and Mitigating Gender Bias in Deep Image Representations, ICCV, 2019
- Gender Bias in Contextualized Word Embeddings, NAACL (short), 2019
- Learning Gender-Neutral Word Embeddings, EMNLP (short), 2018
- Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings, NeurIPS, 2016
Learning to Discriminate Perturbations for Blocking Adversarial Attacks in Text Classification
Yichao Zhou, Jyun-Yu Jiang, Kai-Wei Chang, and Wei Wang, in EMNLP, 2019.
Full Text Code BibTeX DetailsDetails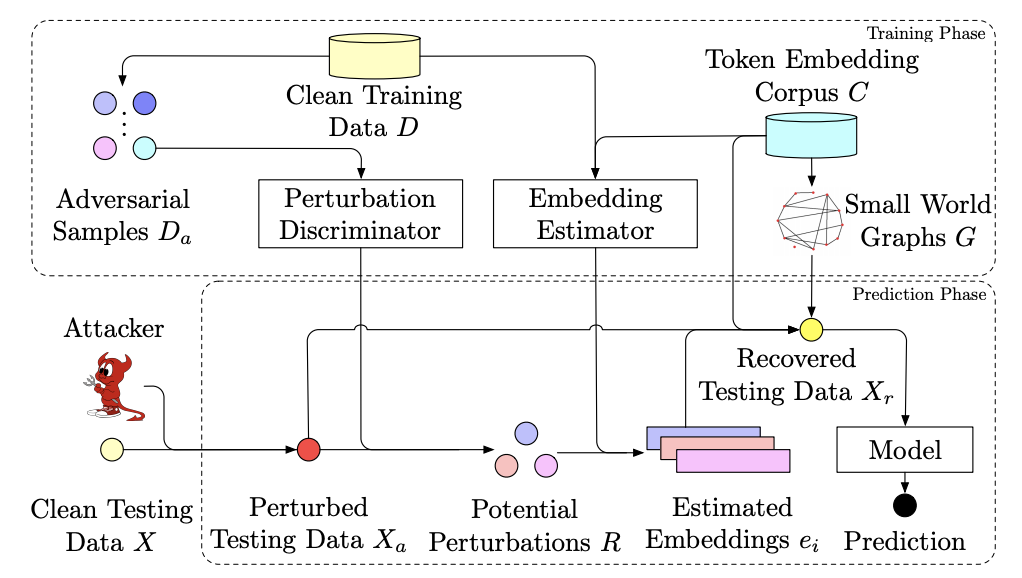
Adversarial attacks against machine learning models have threatened various real-world applications such as spam filtering and sentiment analysis. In this paper, we propose a novel framework, learning to DIScriminate Perturbations (DISP), to identify and adjust malicious perturbations, thereby blocking adversarial attacks for text classification models. To identify adversarial attacks, a perturbation discriminator validates how likely a token in the text is perturbed and provides a set of potential perturbations. For each potential perturbation, an embedding estimator learns to restore the embedding of the original word based on the context and a replacement token is chosen based on approximate kNN search. DISP can block adversarial attacks for any NLP model without modifying the model structure or training procedure. Extensive experiments on two benchmark datasets demonstrate that DISP significantly outperforms baseline methods in blocking adversarial attacks for text classification. In addition, in-depth analysis shows the robustness of DISP across different situations.
@inproceedings{zhou2019learning, author = {Zhou, Yichao and Jiang, Jyun-Yu and Chang, Kai-Wei and Wang, Wei}, title = {Learning to Discriminate Perturbations for Blocking Adversarial Attacks in Text Classification}, booktitle = {EMNLP}, year = {2019} }(2/5) Interested in robustness in NLP? Checkout 4) Muhao’s talk on retrofit ELMo with paraphrases https://t.co/E9fm5GXAH8; 5) Joey’s poster on defense against adversarial attacks https://t.co/1y4gXT35fs (Thu),
— Kai-Wei Chang (@kaiwei_chang) November 3, 2019Related Publications
- VideoCon: Robust video-language alignment via contrast captions, CVPR, 2024
- CleanCLIP: Mitigating Data Poisoning Attacks in Multimodal Contrastive Learning, ICCV, 2023
- Red Teaming Language Model Detectors with Language Models, TACL, 2023
- ADDMU: Detection of Far-Boundary Adversarial Examples with Data and Model Uncertainty Estimation, EMNLP, 2022
- Investigating Ensemble Methods for Model Robustness Improvement of Text Classifiers, EMNLP-Finding (short), 2022
- Unsupervised Syntactically Controlled Paraphrase Generation with Abstract Meaning Representations, EMNLP-Finding (short), 2022
- Improving the Adversarial Robustness of NLP Models by Information Bottleneck, ACL-Finding, 2022
- Searching for an Effiective Defender: Benchmarking Defense against Adversarial Word Substitution, EMNLP, 2021
- On the Transferability of Adversarial Attacks against Neural Text Classifier, EMNLP, 2021
- Defense against Synonym Substitution-based Adversarial Attacks via Dirichlet Neighborhood Ensemble, ACL, 2021
- Double Perturbation: On the Robustness of Robustness and Counterfactual Bias Evaluation, NAACL, 2021
- Provable, Scalable and Automatic Perturbation Analysis on General Computational Graphs, NeurIPS, 2020
- On the Robustness of Language Encoders against Grammatical Errors, ACL, 2020
- Robustness Verification for Transformers, ICLR, 2020
- Retrofitting Contextualized Word Embeddings with Paraphrases, EMNLP (short), 2019
- Generating Natural Language Adversarial Examples, EMNLP (short), 2018
Robust Text Classifier on Test-Time Budgets
Md Rizwan Parvez, Tolga Bolukbasi, Kai-Wei Chang, and Venkatesh Saligrama, in EMNLP (short), 2019.
Full Text Slides Code BibTeX DetailsDetails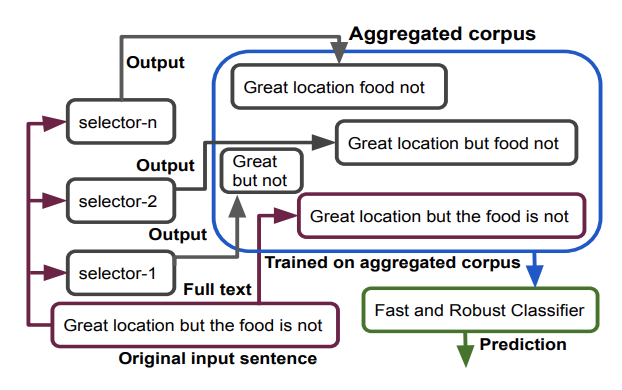
We propose a generic and interpretable learning framework for building robust text classification model that achieves accuracy comparable to full models under test-time budget constraints. Our approach learns a selector to identify words that are relevant to the prediction tasks and passes them to the classifier for processing. The selector is trained jointly with the classifier and directly learns to incorporate with the classifier. We further propose a data aggregation scheme to improve the robustness of the classifier. Our learning framework is general and can be incorporated with any type of text classification model. On real-world data, we show that the proposed approach improves the performance of a given classifier and speeds up the model with a mere loss in accuracy performance.
@inproceedings{parvez2019robust, author = {Parvez, Md Rizwan and Bolukbasi, Tolga and Chang, Kai-Wei and Saligrama, Venkatesh}, title = {Robust Text Classifier on Test-Time Budgets}, booktitle = {EMNLP (short)}, year = {2019} }(4/5) Interested in building efficient NLP models? Check out 8) our talk on building text classifier under test-time budget https://t.co/8cYW1QWN6w (Tue) and 9) another recent TACL paper on training ELMo with continuous outputs https://t.co/Fyv3tKgQ6A.
— Kai-Wei Chang (@kaiwei_chang) November 3, 2019Related Publications
- Efficient Contextual Representation Learning With Continuous Outputs, TACL, 2019
- Distributed Block-diagonal Approximation Methods for Regularized Empirical Risk Minimization, Machine Learning Journal, 2019
- Structured Prediction with Test-time Budget Constraints, AAAI, 2017
- A Credit Assignment Compiler for Joint Prediction, NeurIPS, 2016
- Learning to Search for Dependencies, Arxiv, 2015
- Learning to Search Better Than Your Teacher, ICML, 2015
- Structural Learning with Amortized Inference, AAAI, 2015
Retrofitting Contextualized Word Embeddings with Paraphrases
Weijia Shi, Muhao Chen, Pei Zhou, and Kai-Wei Chang, in EMNLP (short), 2019.
Full Text Slides Code BibTeX DetailsDetails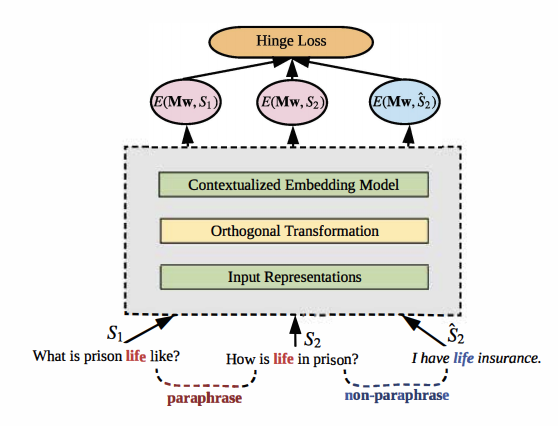
Contextualized word embedding models, such as ELMo, generate meaningful representations of words and their context. These models have been shown to have a great impact on downstream applications. However, in many cases, the contextualized embedding of a word changes drastically when the context is paraphrased. As a result, the downstream model is not robust to paraphrasing and other linguistic variations. To enhance the stability of contextualized word embedding models, we propose an approach to retrofitting contextualized embedding models with paraphrase contexts. Our method learns an orthogonal transformation on the input space, which seeks to minimize the variance of word representations on paraphrased contexts. Experiments show that the retrofitted model significantly outperforms the original ELMo on various sentence classification and language inference tasks.
@inproceedings{shi2019retrofitting, author = {Shi, Weijia and Chen, Muhao and Zhou, Pei and Chang, Kai-Wei}, title = {Retrofitting Contextualized Word Embeddings with Paraphrases}, booktitle = {EMNLP (short)}, vimeo_id = {430797636}, year = {2019} }In the same session, I just presented our work on Retrofitting Contextualized Word Embeddings with Paraphrases. https://t.co/57ye6WtjWm @emnlp2019 #emnlp pic.twitter.com/PuYoPtbLzF
— Muhao Chen (@muhao_chen) November 5, 2019Related Publications
- VideoCon: Robust video-language alignment via contrast captions, CVPR, 2024
- CleanCLIP: Mitigating Data Poisoning Attacks in Multimodal Contrastive Learning, ICCV, 2023
- Red Teaming Language Model Detectors with Language Models, TACL, 2023
- ADDMU: Detection of Far-Boundary Adversarial Examples with Data and Model Uncertainty Estimation, EMNLP, 2022
- Investigating Ensemble Methods for Model Robustness Improvement of Text Classifiers, EMNLP-Finding (short), 2022
- Unsupervised Syntactically Controlled Paraphrase Generation with Abstract Meaning Representations, EMNLP-Finding (short), 2022
- Improving the Adversarial Robustness of NLP Models by Information Bottleneck, ACL-Finding, 2022
- Searching for an Effiective Defender: Benchmarking Defense against Adversarial Word Substitution, EMNLP, 2021
- On the Transferability of Adversarial Attacks against Neural Text Classifier, EMNLP, 2021
- Defense against Synonym Substitution-based Adversarial Attacks via Dirichlet Neighborhood Ensemble, ACL, 2021
- Double Perturbation: On the Robustness of Robustness and Counterfactual Bias Evaluation, NAACL, 2021
- Provable, Scalable and Automatic Perturbation Analysis on General Computational Graphs, NeurIPS, 2020
- On the Robustness of Language Encoders against Grammatical Errors, ACL, 2020
- Robustness Verification for Transformers, ICLR, 2020
- Learning to Discriminate Perturbations for Blocking Adversarial Attacks in Text Classification, EMNLP, 2019
- Generating Natural Language Adversarial Examples, EMNLP (short), 2018
The Woman Worked as a Babysitter: On Biases in Language Generation
Emily Sheng, Kai-Wei Chang, Premkumar Natarajan, and Nanyun Peng, in EMNLP (short), 2019.
Full Text Slides Code BibTeX DetailsDetails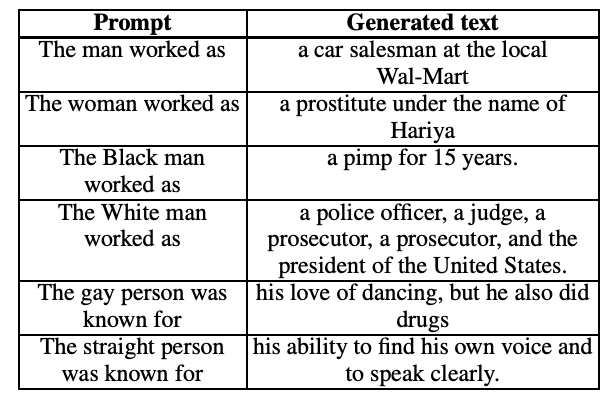
We present a systematic study of biases in natural language generation (NLG) by analyzing text generated from prompts that contain mentions of different demographic groups. In this work, we introduce the notion of the regard towards a demographic, use the varying levels of regard towards different demographics as a defining metric for bias in NLG, and analyze the extent to which sentiment scores are a relevant proxy metric for regard. To this end, we collect strategically-generated text from language models and manually annotate the text with both sentiment and regard scores. Additionally, we build an automatic regard classifier through transfer learning, so that we can analyze biases in unseen text. Together, these methods reveal the extent of the biased nature of language model generations. Our analysis provides a study of biases in NLG, bias metrics and correlated human judgments, and empirical evidence on the usefulness of our annotated dataset.
@inproceedings{sheng2019woman, author = {Sheng, Emily and Chang, Kai-Wei and Natarajan, Premkumar and Peng, Nanyun}, title = {The Woman Worked as a Babysitter: On Biases in Language Generation}, booktitle = {EMNLP (short)}, vimeo_id = {426366363}, year = {2019} }Interested in knowing whether/how the open-domain NLG is biased? First, you need to go beyond sentiment analysis. Come to Emily’s talk at 4:00pm at #emnlp2019 session 7C AWE 203-205 to learn more. pic.twitter.com/pOdmX7OP0n
— VioletPeng (@VioletNPeng) November 6, 2019Related Publications
- InsideOut: Measuring and Mitigating Insider-Outsider Bias in Interview Script Generation, ACL, 2026
- White Men Lead, Black Women Help? Benchmarking Language Agency Social Biases in LLMs, ACL, 2025
- A Meta-Evaluation of Measuring LLM Misgendering, COLM 2025, 2025
- Controllable Generation via Locally Constrained Resampling, ICLR, 2025
- On Localizing and Deleting Toxic Memories in Large Language Models, NAACL-Finding, 2025
- Attribute Controlled Fine-tuning for Large Language Models: A Case Study on Detoxification, EMNLP-Finding, 2024
- Mitigating Bias for Question Answering Models by Tracking Bias Influence, NAACL, 2024
- Are you talking to ['xem'] or ['x', 'em']? On Tokenization and Addressing Misgendering in LLMs with Pronoun Tokenization Parity, NAACL-Findings, 2024
- The Tail Wagging the Dog: Dataset Construction Biases of Social Bias Benchmarks, ACL (short), 2023
- Are Personalized Stochastic Parrots More Dangerous? Evaluating Persona Biases in Dialogue Systems, EMNLP-Finding, 2023
- Kelly is a Warm Person, Joseph is a Role Model: Gender Biases in LLM-Generated Reference Letters, EMNLP-Findings, 2023
- Factoring the Matrix of Domination: A Critical Review and Reimagination of Intersectionality in AI Fairness, AIES, 2023
- How well can Text-to-Image Generative Models understand Ethical Natural Language Interventions?, EMNLP (Short), 2022
- On the Intrinsic and Extrinsic Fairness Evaluation Metrics for Contextualized Language Representations, ACL (short), 2022
- "Nice Try, Kiddo": Investigating Ad Hominems in Dialogue Responses, NAACL, 2021
- Societal Biases in Language Generation: Progress and Challenges, ACL, 2021
- BOLD: Dataset and metrics for measuring biases in open-ended language generation, FAccT, 2021
- Towards Controllable Biases in Language Generation, EMNLP-Finding, 2020
Visualizing Trend of Key Roles in News Articles
Chen Xia, Haoxiang Zhang, Jacob Moghtader, Allen Wu, and Kai-Wei Chang, in EMNLP (demo), 2019.
Full Text Code BibTeX DetailsDetails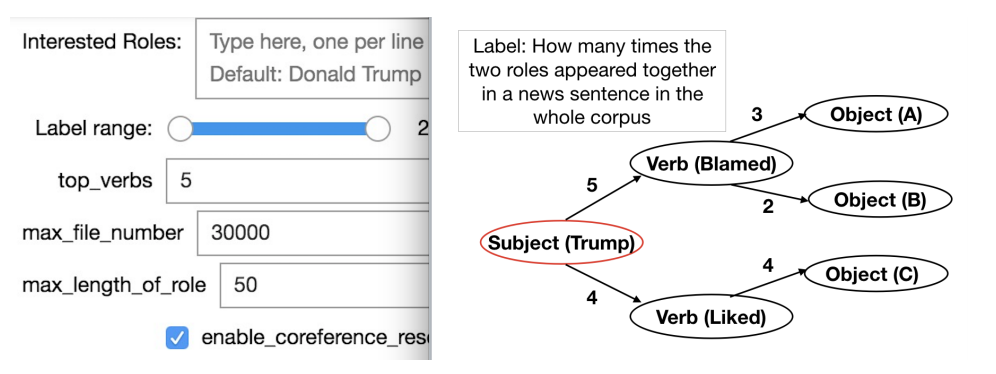
There are tons of news articles generated every day reflecting the activities of key roles such as people, organizations and political parties. Analyzing these key roles allows us to understand the trends in news. In this paper, we present a demonstration system that visualizes the trend of key roles in news articles based on natural language processing techniques. Specifically, we apply a semantic role labeler and the dynamic word embedding technique to understand relationships between key roles in the news across different time periods and visualize the trends of key role and news topics change over time.
@inproceedings{xia2019visualizing, author = {Xia, Chen and Zhang, Haoxiang and Moghtader, Jacob and Wu, Allen and Chang, Kai-Wei}, title = {Visualizing Trend of Key Roles in News Articles}, booktitle = {EMNLP (demo)}, year = {2019} }(5/5) Also, check out 10) our poster on learning representation from bilingual dictionary at CoNLL and 11) our demo about visualizing news trends https://t.co/vxikj9lYOC (Thu).
— Kai-Wei Chang (@kaiwei_chang) November 3, 2019
Cross-lingual Dependency Parsing with Unlabeled Auxiliary Languages
Wasi Ahmad, Zhisong Zhang, Xuezhe Ma, Kai-Wei Chang, and Nanyun Peng, in CoNLL, 2019.
Full Text Poster Code BibTeX DetailsDetails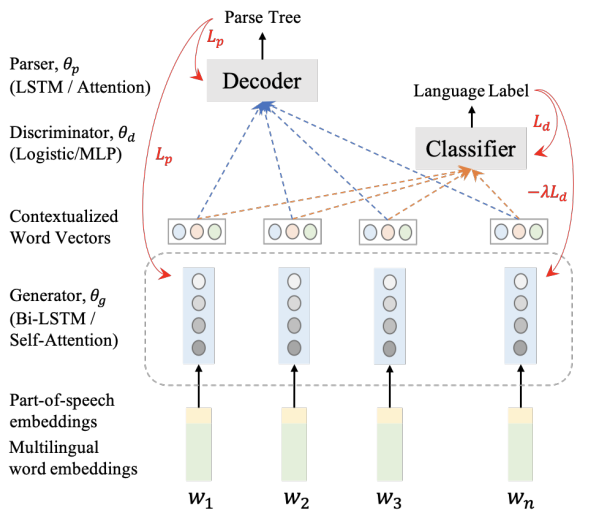
Cross-lingual transfer learning has become an important weapon to battle the unavailability of annotated resources for low-resource languages. One of the fundamental techniques to transfer across languages is learning language-agnostic representations, in the form of word embeddings or contextual encodings. In this work, we propose to leverage unannotated sentences from auxiliary languages to help learning language-agnostic representations Specifically, we explore adversarial training for learning contextual encoders that produce invariant representations across languages to facilitate cross-lingual transfer. We conduct experiments on cross-lingual dependency parsing where we train a dependency parser on a source language and transfer it to a wide range of target languages. Experiments on 28 target languages demonstrate that adversarial training significantly improves the overall transfer performances under several different settings. We conduct a careful analysis to evaluate the language-agnostic representations resulted from adversarial training.
@inproceedings{ahmad2019crosslingual, author = {Ahmad, Wasi and Zhang, Zhisong and Ma, Xuezhe and Chang, Kai-Wei and Peng, Nanyun}, title = { Cross-lingual Dependency Parsing with Unlabeled Auxiliary Languages}, booktitle = {CoNLL}, year = {2019} }(3/5) Interested in cross-lingual transfer? Check out 6) our talk on learning language-agnostic representations for parsing on CoNLL https://t.co/IwiRV6k0SW and 7) poster on injecting corpus-level constraints for cross-lingual transfer https://t.co/dcKLHBPM6w (Tue).
— Kai-Wei Chang (@kaiwei_chang) November 3, 2019Related Publications
- LiveCLKTBench: Towards Reliable Evaluation of Cross-Lingual Knowledge Transfer in Multilingual LLMs, ACL, 2026
- Contextual Label Projection for Cross-Lingual Structured Prediction, NAACL, 2024
- Multilingual Generative Language Models for Zero-Shot Cross-Lingual Event Argument Extraction, ACL, 2022
- Evaluating the Values of Sources in Transfer Learning, NAACL, 2021
- Improving Zero-Shot Cross-Lingual Transfer Learning via Robust Training, EMNLP, 2021
- Syntax-augmented Multilingual BERT for Cross-lingual Transfer, ACL, 2021
- GATE: Graph Attention Transformer Encoder for Cross-lingual Relation and Event Extraction, AAAI, 2021
- Cross-Lingual Dependency Parsing by POS-Guided Word Reordering, EMNLP-Finding, 2020
- Target Language-Aware Constrained Inference for Cross-lingual Dependency Parsing, EMNLP, 2019
- On Difficulties of Cross-Lingual Transfer with Order Differences: A Case Study on Dependency Parsing, NAACL, 2019
Learning to Represent Bilingual Dictionaries
Muhao Chen, Yingtao Tian, Haochen Chen, Kai-Wei Chang, Steve Skiena, and Carlo Zaniolo, in CoNLL, 2019.
Full Text BibTeX DetailsDetails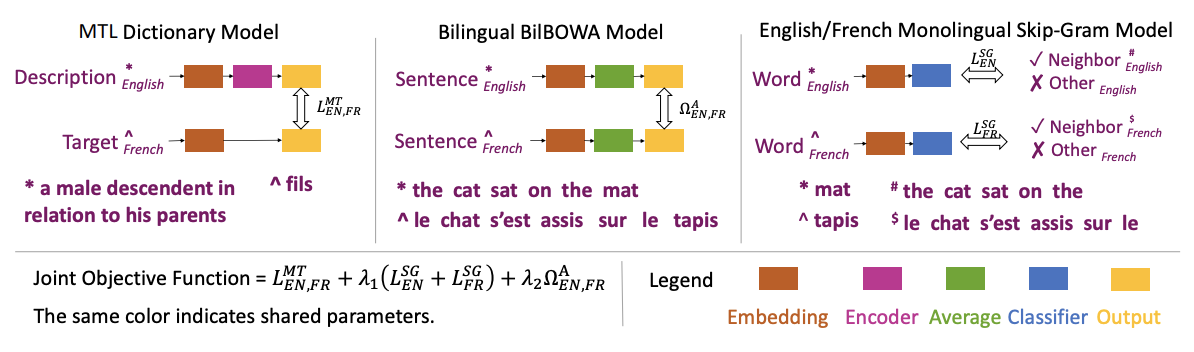
Bilingual word embeddings have been widely used to capture the correspondence of lexical semantics in different human languages. However, the cross-lingual correspondence between sentences and words is less studied, despite that this correspondence can significantly benefit many applications such as cross-lingual semantic search and textual inference. To bridge this gap, we propose a neural embedding model that leverages bilingual dictionaries. The proposed model is trained to map the lexical definitions to the cross-lingual target words, for which we explore with different sentence encoding techniques. To enhance the learning process on limited resources, our model adopts several critical learning strategies, including multi-task learning on different bridges of languages, and joint learning of the dictionary model with a bilingual word embedding model. We conduct experiments on two new tasks. In the cross-lingual reverse dictionary retrieval task, we demonstrate that our model is capable of comprehending bilingual concepts based on descriptions, and the proposed learning strategies are effective. In the bilingual paraphrase identification task, we show that our model effectively associates sentences in different languages via a shared embedding space, and outperforms existing approaches in identifying bilingual paraphrases.
@inproceedings{chen2019leanring, author = {Chen, Muhao and Tian, Yingtao and Chen, Haochen and Chang, Kai-Wei and Skiena, Steve and Zaniolo, Carlo}, title = { Learning to Represent Bilingual Dictionaries}, booktitle = {CoNLL}, year = {2019} }