At UCLA-NLP, our mission is to develop fair, accountable, robust natural language processing technology to benefit everyone. We will present papers at EMNLP 2020 on the following topics.
Link to our papers in the virtual conference
Fairness in Natural Language Processing
Natural Language Processing (NLP) models are widely used in our daily lives. Despite these methods achieve high performance in various applications, they run the risk of exploiting and reinforcing the societal biases (e.g. gender bias) that are present in the underlying data. At EMNLP, we present our studies on 1) how to detect bias in a local region of instances, 2) how to control bias in language generation.
LOGAN: Local Group Bias Detection by Clustering
Jieyu Zhao and Kai-Wei Chang, in EMNLP (short), 2020.
QA Sessions: Gather-1I: Nov 17, 02:00-04:00 UTC / 18:00-20:00 PST -1d Paper link in the virtual conferenceFull Text Code BibTeX DetailsDetails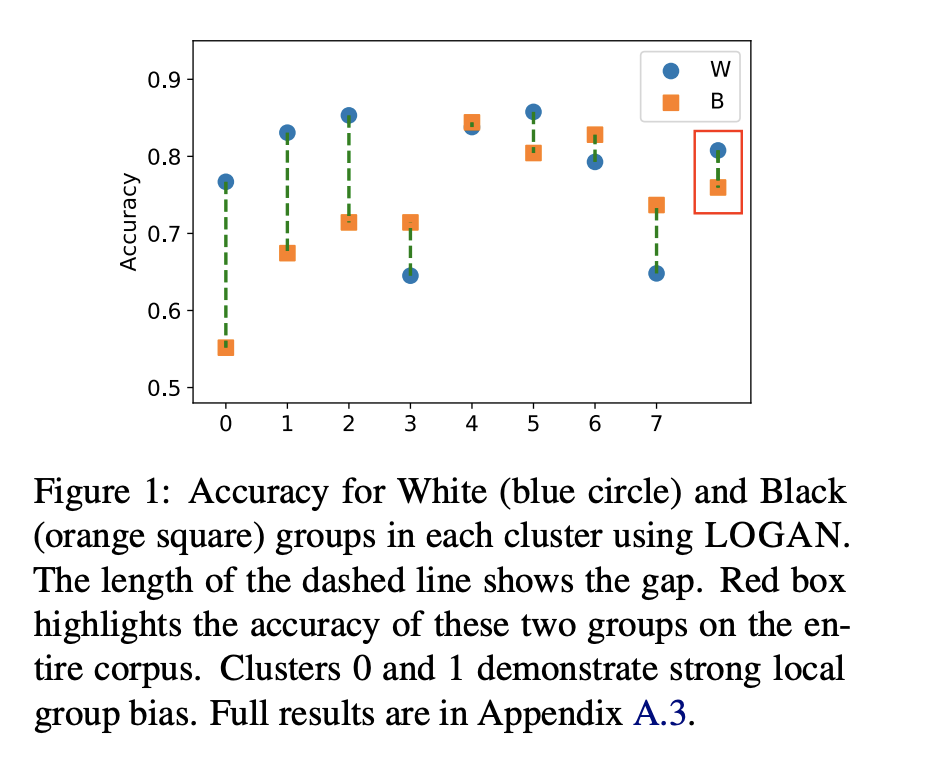
Machine learning techniques have been widely used in natural language processing (NLP). However, as revealed by many recent studies, machine learning models often inherit and amplify the societal biases in data. Various metrics have been proposed to quantify biases in model predictions. In particular, several of them evaluate disparity in model performance between protected groups and advantaged groups in the test corpus. However, we argue that evaluating bias at the corpus level is not enough for understanding how biases are embedded in a model. In fact, a model with similar aggregated performance between different groups on the entire data may behave differently on instances in a local region. To analyze and detect such local bias, we propose LOGAN, a new bias detection technique based on clustering. Experiments on toxicity classification and object classification tasks show that LOGAN identifies bias in a local region and allows us to better analyze the biases in model predictions.
@inproceedings{zhao2020logan, author = {Zhao, Jieyu and Chang, Kai-Wei}, title = {LOGAN: Local Group Bias Detection by Clustering}, booktitle = {EMNLP (short)}, presentation_id = {https://virtual.2020.emnlp.org/paper_main.2886.html}, year = {2020} }1/2 Existing studies on measuring bias often consider performance gap between cohorts over the entire test set. But, does it show the whole story? In our #EMNLP20 paper “LOGAN: Local Group Bias Detection by Clustering” (https://t.co/wnpL4Ern8l), joint work with @kaiwei_chang,
— Jieyu Zhao (@jieyuzhao11) November 16, 2020Related Publications
- Measuring Fairness of Text Classifiers via Prediction Sensitivity, ACL, 2022
- Does Robustness Improve Fairness? Approaching Fairness with Word Substitution Robustness Methods for Text Classification, ACL-Finding, 2021
- Towards Understanding Gender Bias in Relation Extraction, ACL, 2020
- Mitigating Gender Bias Amplification in Distribution by Posterior Regularization, ACL (short), 2020
- Mitigating Gender in Natural Language Processing: Literature Review, ACL, 2019
- Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods, NAACL (short), 2018
- Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints, EMNLP, 2017
Towards Controllable Biases in Language Generation
Emily Sheng, Kai-Wei Chang, Premkumar Natarajan, and Nanyun Peng, in EMNLP-Finding, 2020.
Full Text Code BibTeX DetailsDetails
We present a general approach towards controllable societal biases in natural language generation (NLG). Building upon the idea of adversarial triggers, we develop a method to induce societal biases in generated text when input prompts contain mentions of specific demographic groups. We then analyze two scenarios: 1) inducing negative biases for one demographic and positive biases for another demographic, and 2) equalizing biases between demographics. The former scenario enables us to detect the types of biases present in the model. Specifically, we show the effectiveness of our approach at facilitating bias analysis by finding topics that correspond to demographic inequalities in generated text and comparing the relative effectiveness of inducing biases for different demographics. The second scenario is useful for mitigating biases in downstream applications such as dialogue generation. In our experiments, the mitigation technique proves to be effective at equalizing the amount of biases across demographics while simultaneously generating less negatively biased text overall.
@inproceedings{sheng2020towards, title = {Towards Controllable Biases in Language Generation}, author = {Sheng, Emily and Chang, Kai-Wei and Natarajan, Premkumar and Peng, Nanyun}, booktitle = {EMNLP-Finding}, year = {2020} }Excited to finally share our work “Towards Controllable Biases in Language Generation” (https://t.co/Y7TbcSOsbX), to appear in Findings of #emnlp2020, and done with @kaiwei_chang, Prem Natarajan, and @VioletNPeng :)
— Emily Sheng (@ewsheng) October 8, 2020Related Publications
- A Meta-Evaluation of Measuring LLM Misgendering, COLM 2025, 2025
- White Men Lead, Black Women Help? Benchmarking Language Agency Social Biases in LLMs, ACL, 2025
- Controllable Generation via Locally Constrained Resampling, ICLR, 2025
- On Localizing and Deleting Toxic Memories in Large Language Models, NAACL-Finding, 2025
- Attribute Controlled Fine-tuning for Large Language Models: A Case Study on Detoxification, EMNLP-Finding, 2024
- Mitigating Bias for Question Answering Models by Tracking Bias Influence, NAACL, 2024
- Are you talking to ['xem'] or ['x', 'em']? On Tokenization and Addressing Misgendering in LLMs with Pronoun Tokenization Parity, NAACL-Findings, 2024
- Are Personalized Stochastic Parrots More Dangerous? Evaluating Persona Biases in Dialogue Systems, EMNLP-Finding, 2023
- Kelly is a Warm Person, Joseph is a Role Model: Gender Biases in LLM-Generated Reference Letters, EMNLP-Findings, 2023
- The Tail Wagging the Dog: Dataset Construction Biases of Social Bias Benchmarks, ACL (short), 2023
- Factoring the Matrix of Domination: A Critical Review and Reimagination of Intersectionality in AI Fairness, AIES, 2023
- How well can Text-to-Image Generative Models understand Ethical Natural Language Interventions?, EMNLP (Short), 2022
- On the Intrinsic and Extrinsic Fairness Evaluation Metrics for Contextualized Language Representations, ACL (short), 2022
- Societal Biases in Language Generation: Progress and Challenges, ACL, 2021
- "Nice Try, Kiddo": Investigating Ad Hominems in Dialogue Responses, NAACL, 2021
- BOLD: Dataset and metrics for measuring biases in open-ended language generation, FAccT, 2021
- The Woman Worked as a Babysitter: On Biases in Language Generation, EMNLP (short), 2019
Cross-Lingual Transfer
Cross-Lingual Dependency Parsing by POS-Guided Word Reordering
Lu Liu, Yi Zhou, Jianhan Xu, Xiaoqing Zheng, Kai-Wei Chang, and Xuanjing Huang, in EMNLP-Finding, 2020.
Full Text BibTeX DetailsDetails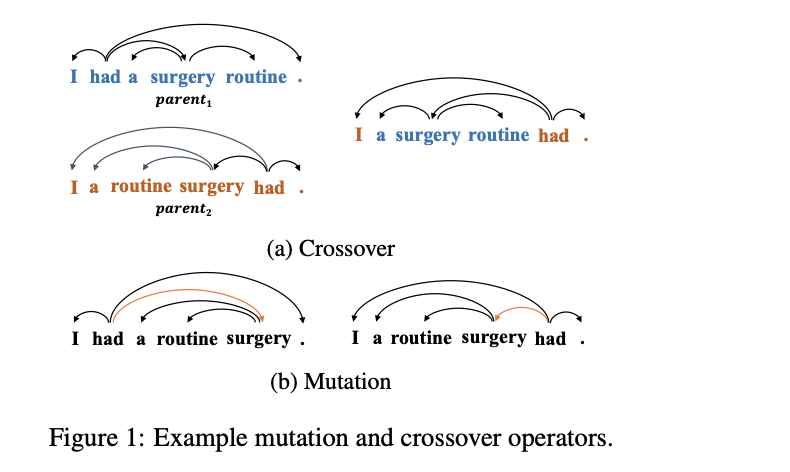
We propose a novel approach to cross-lingual dependency parsing based on word reordering. The words in each sentence of a source language corpus are rearranged to meet the word order in a target language under the guidance of a part-of-speech based language model (LM). To obtain the highest reordering score under the LM, a population-based optimization algorithm and its genetic operators are designed to deal with the combinatorial nature of such word reordering. A parser trained on the reordered corpus then can be used to parse sentences in the target language. We demonstrate through extensive experimentation that our approach achieves better or comparable results across 25 target languages (1.73% increase in average), and outperforms a baseline by a significant margin on the languages that are greatly different from the source one. For example, when transferring the English parser to Hindi and Latin, our approach outperforms the baseline by 15.3% and 6.7% respectively.
@inproceedings{liu2020cross-lingual, author = {Liu, Lu and Zhou, Yi and Xu, Jianhan and Zheng, Xiaoqing and Chang, Kai-Wei and Huang, Xuanjing}, title = {Cross-Lingual Dependency Parsing by POS-Guided Word Reordering}, booktitle = {EMNLP-Finding}, year = {2020} }Related Publications
- Contextual Label Projection for Cross-Lingual Structured Prediction, NAACL, 2024
- Multilingual Generative Language Models for Zero-Shot Cross-Lingual Event Argument Extraction, ACL, 2022
- Improving Zero-Shot Cross-Lingual Transfer Learning via Robust Training, EMNLP, 2021
- Syntax-augmented Multilingual BERT for Cross-lingual Transfer, ACL, 2021
- Evaluating the Values of Sources in Transfer Learning, NAACL, 2021
- GATE: Graph Attention Transformer Encoder for Cross-lingual Relation and Event Extraction, AAAI, 2021
- Cross-lingual Dependency Parsing with Unlabeled Auxiliary Languages, CoNLL, 2019
- Target Language-Aware Constrained Inference for Cross-lingual Dependency Parsing, EMNLP, 2019
- On Difficulties of Cross-Lingual Transfer with Order Differences: A Case Study on Dependency Parsing, NAACL, 2019
NLP for Social Good
PolicyQA: A Reading Comprehension Dataset for Privacy Policies
Wasi Ahmad, Jianfeng Chi, Yuan Tian, and Kai-Wei Chang, in EMNLP-Finding (short), 2020.
Full Text Code BibTeX DetailsDetails
Privacy policy documents are long and verbose. A question answering (QA) system can assist users in finding the information that is relevant and important to them. Prior studies in this domain frame the QA task as retrieving the most relevant text segment or a list of sentences from the policy document given a question. On the contrary, we argue that providing users with a short text span from policy documents reduces the burden of searching the target information from a lengthy text segment. In this paper, we present PolicyQA, a dataset that contains 25,017 reading comprehension style examples curated from an existing corpus of 115 website privacy policies. PolicyQA provides 714 human-annotated questions written for a wide range of privacy practices. We evaluate two existing neural QA models and perform rigorous analysis to reveal the advantages and challenges offered by PolicyQA.
@inproceedings{ahmad2020policyqa, author = {Ahmad, Wasi and Chi, Jianfeng and Tian, Yuan and Chang, Kai-Wei}, title = {PolicyQA: A Reading Comprehension Dataset for Privacy Policies}, booktitle = {EMNLP-Finding (short)}, year = {2020} }Related Publications
- Relation-Guided Pre-Training for Open-Domain Question Answering, EMNLP-Finding, 2021
- An Integer Linear Programming Framework for Mining Constraints from Data, ICML, 2021
- Generating Syntactically Controlled Paraphrases without Using Annotated Parallel Pairs, EACL, 2021
- Clinical Temporal Relation Extraction with Probabilistic Soft Logic Regularization and Global Inference, AAAI, 2021
- GPT-GNN: Generative Pre-Training of Graph Neural Networks, KDD, 2020
- SentiBERT: A Transferable Transformer-Based Architecture for Compositional Sentiment Semantics, ACL, 2020
- Building Language Models for Text with Named Entities, ACL, 2018
- Learning from Explicit and Implicit Supervision Jointly For Algebra Word Problems, EMNLP, 2016