At UCLA-NLP, our mission is to develop fair, accountable, robust natural language processing technology to benefit everyone. We will present papers at ACL 2020 on the following topics.
- Fairness in NLP
- Analyze and Understand NLP Models
- Energy Efficient Pre-training
- Enhance Contextulaized Encoder
Link to our papers in the virtual conference
Fairness in Natural Language Processing
Natural Language Processing (NLP) models are widely used in our daily lives. Despite these methods achieve high performance in various applications, they run the risk of exploiting and reinforcing the societal biases (e.g. gender bias) that are present in the underlying data. At ACL, we present our studies on 1) how gender bias is propagated in cross-lingual transfer, 2) how bias is amplified in the distribution of model predictions, and 3) gender bias in relation extraction.
Gender Bias in Multilingual Embeddings and Cross-Lingual Transfer
Jieyu Zhao, Subhabrata Mukherjee, Saghar Hosseini, Kai-Wei Chang, and Ahmed Hassan Awadallah, in ACL, 2020.
QA Sessions: 6A Ethics, 10B Ethics Paper link in the virtual conferenceFull Text Slides BibTeX DetailsDetails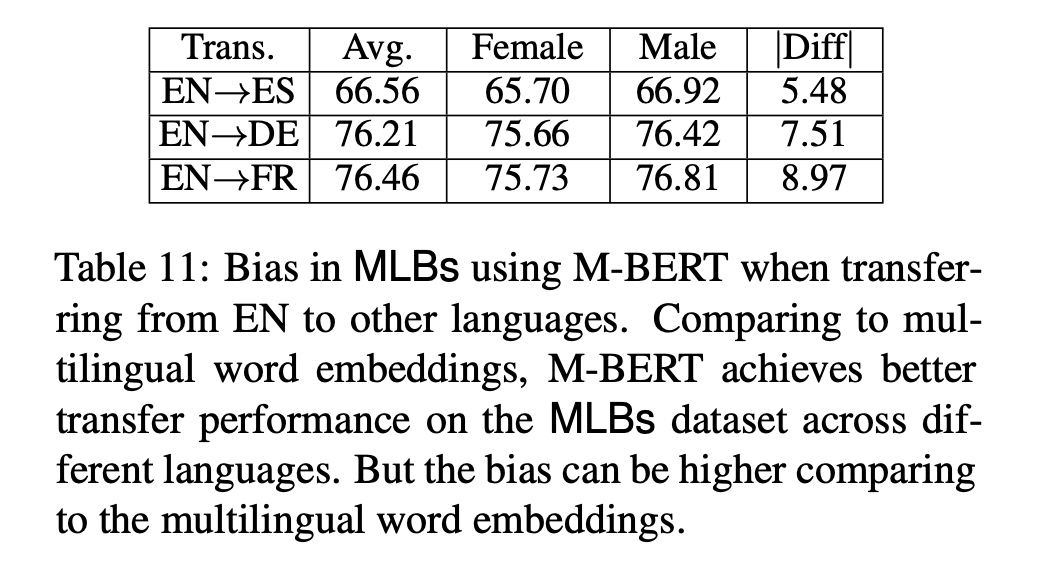
Multilingual representations embed words from many languages into a single semantic space such that words with similar meanings are close to each other regardless of the language. These embeddings have been widely used in various settings, such as cross-lingual transfer, where a natural language processing (NLP) model trained on one language is deployed to another language. While the cross-lingual transfer techniques are powerful, they carry gender bias from the source to target languages. In this paper, we study gender bias in multilingual embeddings and how it affects transfer learning for NLP applications. We create a multilingual dataset for bias analysis and propose several ways for quantifying bias in multilingual representations from both the intrinsic and extrinsic perspectives. Experimental results show that the magnitude of bias in the multilingual representations changes differently when we align the embeddings to different target spaces and that the alignment direction can also have an influence on the bias in transfer learning. We further provide recommendations for using the multilingual word representations for downstream tasks.
@inproceedings{zhao2020gender, author = {Zhao, Jieyu and Mukherjee, Subhabrata and Hosseini, Saghar and Chang, Kai-Wei and Awadallah, Ahmed Hassan}, title = {Gender Bias in Multilingual Embeddings and Cross-Lingual Transfer}, booktitle = {ACL}, year = {2020}, presentation_id = {https://virtual.acl2020.org/paper_main.260.html} }1/3 Happy to share our new paper "Gender Bias in Multilingual Embeddings and Cross-Lingual Transfer" with @subho_mpi,@sagharh, @kaiwei_chang and Ahmed Hassan Awadallah at #acl2020nlp https://t.co/YPjwz0Tjs2
— Jieyu Zhao (@jieyuzhao11) May 7, 2020Related Publications
- Mitigating Gender Bias in Distilled Language Models via Counterfactual Role Reversal, ACL Finding, 2022
- Harms of Gender Exclusivity and Challenges in Non-Binary Representation in Language Technologies, EMNLP, 2021
- Examining Gender Bias in Languages with Grammatical Gender, EMNLP, 2019
- Balanced Datasets Are Not Enough: Estimating and Mitigating Gender Bias in Deep Image Representations, ICCV, 2019
- Gender Bias in Contextualized Word Embeddings, NAACL (short), 2019
- Learning Gender-Neutral Word Embeddings, EMNLP (short), 2018
- Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings, NeurIPS, 2016
Towards Understanding Gender Bias in Relation Extraction
Andrew Gaut, Tony Sun, Shirlyn Tang, Yuxin Huang, Jing Qian, Mai ElSherief, Jieyu Zhao, Diba Mirza, Elizabeth Belding, Kai-Wei Chang, and William Yang Wang, in ACL, 2020.
QA Sessions: 6A Ethics, 7B Ethics Paper link in the virtual conferenceFull Text BibTeX DetailsDetails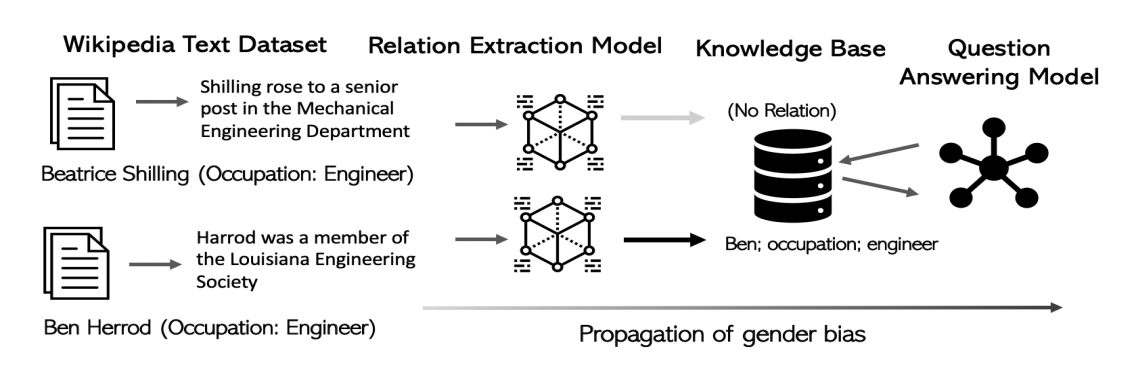
Recent developments in Neural Relation Extraction (NRE) have made significant strides towards automated knowledge base construction. While much attention has been dedicated towards improvements in accuracy, there have been no attempts in the literature to evaluate social biases exhibited in NRE systems. In this paper, we create WikiGenderBias, a distantly supervised dataset composed of over 45,000 sentences including a 10% human annotated test set for the purpose of analyzing gender bias in relation extraction systems. We find that when extracting spouse and hypernym (i.e., occupation) relations, an NRE system performs differently when the gender of the target entity is different. However, such disparity does not appear when extracting relations such as birth date or birth place. We also analyze two existing bias mitigation techniques, word embedding debiasing and data augmentation. Unfortunately, due to NRE models relying heavily on surface level cues, we find that existing bias mitigation approaches have a negative effect on NRE. Our analysis lays groundwork for future quantifying and mitigating bias in relation extraction.
@inproceedings{gaut2020towards, author = {Gaut, Andrew and Sun, Tony and Tang, Shirlyn and Huang, Yuxin and Qian, Jing and ElSherief, Mai and Zhao, Jieyu and Mirza, Diba and Belding, Elizabeth and Chang, Kai-Wei and Wang, William Yang}, title = {Towards Understanding Gender Bias in Relation Extraction}, booktitle = {ACL}, year = {2020}, presentation_id = {https://virtual.acl2020.org/paper_main.265.html} }Our work “Towards Understanding Gender Bias in Relation Extraction” was accepted to #acl2020. We release WikiGenderBias, the first dataset for gender bias evaluation in relation extraction! Shoutout to amazing undergraduate students, collaborators and mentors!
— Mai ElSherief (@mai_elsherief) April 4, 2020Related Publications
- Measuring Fairness of Text Classifiers via Prediction Sensitivity, ACL, 2022
- Does Robustness Improve Fairness? Approaching Fairness with Word Substitution Robustness Methods for Text Classification, ACL-Finding, 2021
- LOGAN: Local Group Bias Detection by Clustering, EMNLP (short), 2020
- Mitigating Gender Bias Amplification in Distribution by Posterior Regularization, ACL (short), 2020
- Mitigating Gender in Natural Language Processing: Literature Review, ACL, 2019
- Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods, NAACL (short), 2018
- Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints, EMNLP, 2017
Mitigating Gender Bias Amplification in Distribution by Posterior Regularization
Shengyu Jia, Tao Meng, Jieyu Zhao, and Kai-Wei Chang, in ACL (short), 2020.
QA Sessions: 6A Ethics, 10B Ethics Paper link in the virtual conferenceFull Text Slides Code BibTeX DetailsDetails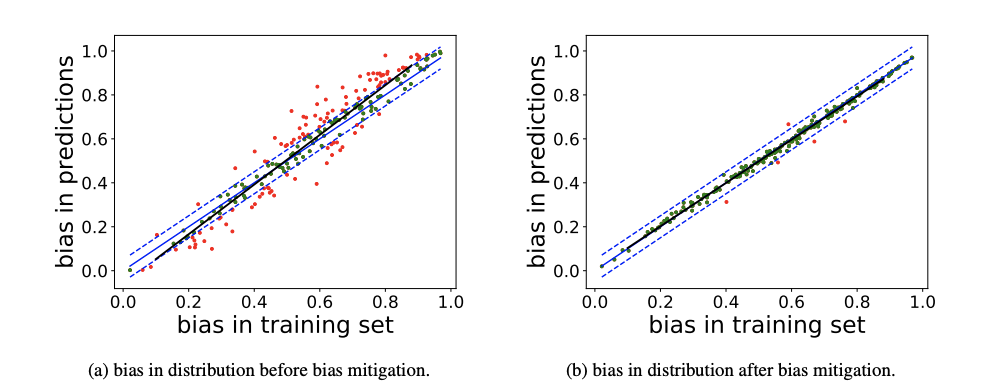
Advanced machine learning techniques have boosted the performance of natural language processing. Nevertheless, recent studies, e.g., Zhao et al. (2017) show that these techniques inadvertently capture the societal bias hiddenin the corpus and further amplify it. However,their analysis is conducted only on models’ top predictions. In this paper, we investigate thegender bias amplification issue from the distribution perspective and demonstrate that thebias is amplified in the view of predicted probability distribution over labels. We further propose a bias mitigation approach based on posterior regularization. With little performance loss, our method can almost remove the bias amplification in the distribution. Our study sheds the light on understanding the bias amplification.
@inproceedings{jia2020mitigating, author = {Jia, Shengyu and Meng, Tao and Zhao, Jieyu and Chang, Kai-Wei}, title = {Mitigating Gender Bias Amplification in Distribution by Posterior Regularization}, booktitle = {ACL (short)}, year = {2020}, presentation_id = {https://virtual.acl2020.org/paper_main.264.html} }[1/3] Our EMNLP17 paper (https://t.co/JVuBNCoi7X) demonstrates bias amplification in model’s top predictions. How about in distribution? Check our #acl2020nlp paper "Mitigating Gender Bias Amplification in Distribution by Posterior Regularization". https://t.co/JVuBNCoi7X. pic.twitter.com/Om6j0xxC3d
— Jieyu Zhao (@jieyuzhao11) June 20, 2020Related Publications
- Measuring Fairness of Text Classifiers via Prediction Sensitivity, ACL, 2022
- Does Robustness Improve Fairness? Approaching Fairness with Word Substitution Robustness Methods for Text Classification, ACL-Finding, 2021
- LOGAN: Local Group Bias Detection by Clustering, EMNLP (short), 2020
- Towards Understanding Gender Bias in Relation Extraction, ACL, 2020
- Mitigating Gender in Natural Language Processing: Literature Review, ACL, 2019
- Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods, NAACL (short), 2018
- Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints, EMNLP, 2017
Analyze and Understand NLP Models
It is essential to analyze and understand the capability of NLP technology. At ACL, we present the following papers on 1) analyzing the robustness of contextualized language encoders against grammatical errors, 2) understanding what are captured by pre-trained visually grounded language models like VisualBERT, and 3) benchmarking transformer-based approaches for source code summarization.
On the Robustness of Language Encoders against Grammatical Errors
Fan Yin, Quanyu Long, Tao Meng, and Kai-Wei Chang, in ACL, 2020.
QA Sessions: 6B Interpretability, 8A Interpretability Paper link in the virtual conferenceFull Text Slides Code BibTeX DetailsDetails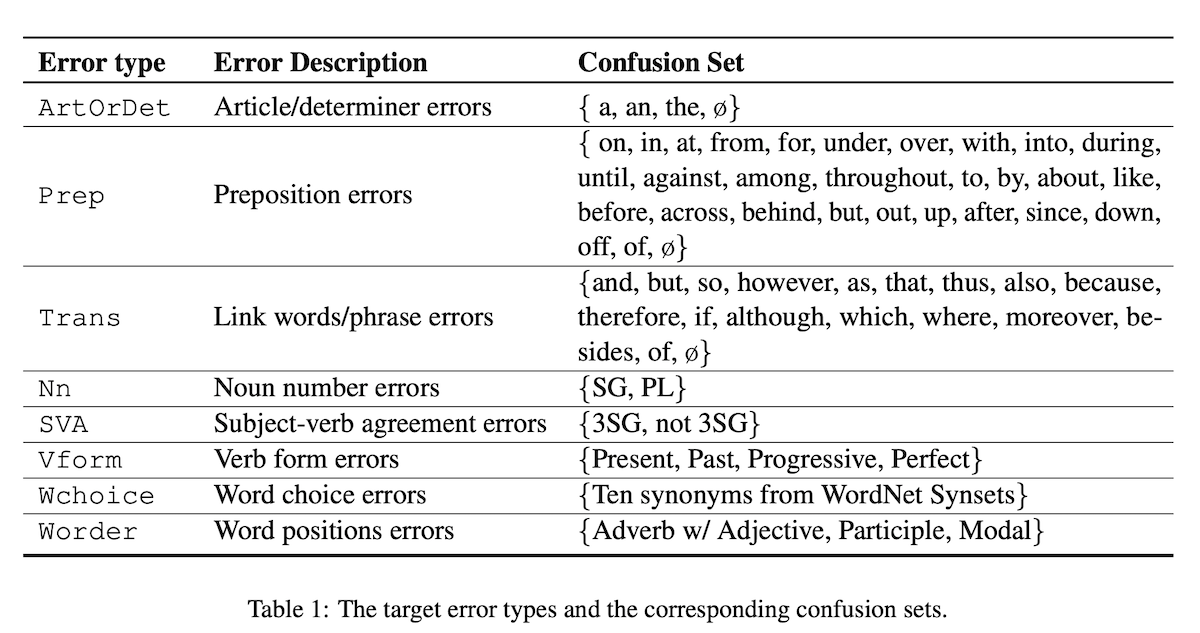
We conduct a thorough study to diagnose the behaviors of pre-trained language encoders (ELMo, BERT, and RoBERTa) when confronted with natural grammatical errors. Specifically, we collect real grammatical errors from non-native speakers and conduct adversarial attacks to simulate these errors on clean text data. We use this approach to facilitate debugging models on downstream applications. Results confirm that the performance of all tested models is affected but the degree of impact varies. To interpret model behaviors, we further design a linguistic acceptability task to reveal their abilities in identifying ungrammatical sentences and the position of errors. We find that fixed contextual encoders with a simple classifier trained on the prediction of sentence correctness are able to locate error positions. We also design a cloze test for BERT and discover that BERT captures the interaction between errors and specific tokens in context. Our results shed light on understanding the robustness and behaviors of language encoders against grammatical errors.
@inproceedings{yin2020robustness, author = {Yin, Fan and Long, Quanyu and Meng, Tao and Chang, Kai-Wei}, title = {On the Robustness of Language Encoders against Grammatical Errors}, booktitle = {ACL}, presentation_id = {https://virtual.acl2020.org/paper_main.310.html}, year = {2020} }How grammatical errors affect language encoders?🧐Our #acl2020nlp: "On the Robustness of Language Encoders against Grammatical Errors"(https://t.co/0mw3hYkNhE w/Fan Yin, Quanyu Long, Tao Meng) diagnoses encoders by simulating grammatical errors with adversarial attacks. #NLProc
— Kai-Wei Chang (@kaiwei_chang) June 11, 2020Related Publications
- VideoCon: Robust video-language alignment via contrast captions, CVPR, 2024
- CleanCLIP: Mitigating Data Poisoning Attacks in Multimodal Contrastive Learning, ICCV, 2023
- Red Teaming Language Model Detectors with Language Models, TACL, 2023
- ADDMU: Detection of Far-Boundary Adversarial Examples with Data and Model Uncertainty Estimation, EMNLP, 2022
- Investigating Ensemble Methods for Model Robustness Improvement of Text Classifiers, EMNLP-Finding (short), 2022
- Unsupervised Syntactically Controlled Paraphrase Generation with Abstract Meaning Representations, EMNLP-Finding (short), 2022
- Improving the Adversarial Robustness of NLP Models by Information Bottleneck, ACL-Finding, 2022
- Searching for an Effiective Defender: Benchmarking Defense against Adversarial Word Substitution, EMNLP, 2021
- On the Transferability of Adversarial Attacks against Neural Text Classifier, EMNLP, 2021
- Defense against Synonym Substitution-based Adversarial Attacks via Dirichlet Neighborhood Ensemble, ACL, 2021
- Double Perturbation: On the Robustness of Robustness and Counterfactual Bias Evaluation, NAACL, 2021
- Provable, Scalable and Automatic Perturbation Analysis on General Computational Graphs, NeurIPS, 2020
- Robustness Verification for Transformers, ICLR, 2020
- Learning to Discriminate Perturbations for Blocking Adversarial Attacks in Text Classification, EMNLP, 2019
- Retrofitting Contextualized Word Embeddings with Paraphrases, EMNLP (short), 2019
- Generating Natural Language Adversarial Examples, EMNLP (short), 2018
What Does BERT with Vision Look At?
Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, and Kai-Wei Chang, in ACL (short), 2020.
QA Sessions: 9A THEME-1, 10A THEME-2 Paper link in the virtual conferenceFull Text Slides Code BibTeX DetailsDetails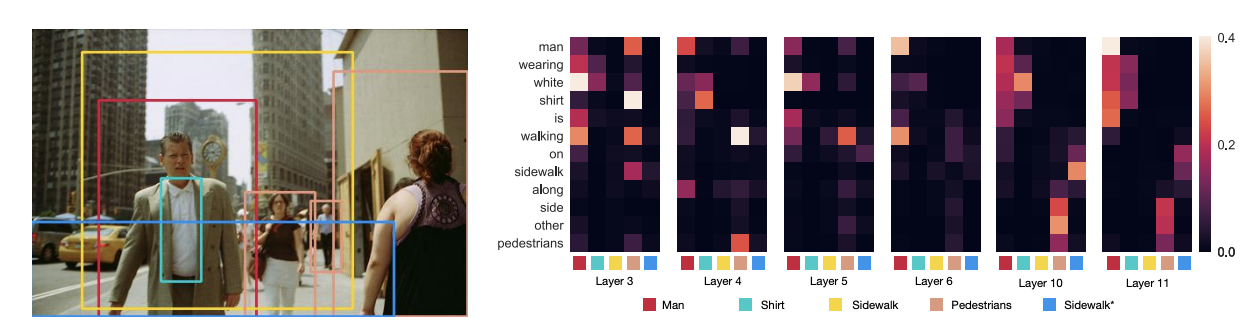
Pre-trained visually grounded language models such as ViLBERT, LXMERT, and UNITER have achieved significant performance improvement on vision-and-language tasks but what they learn during pre-training remains unclear. In this work, we demonstrate that certain attention heads of a visually grounded language model actively ground elements of language to image regions. Specifically, some heads can map entities to image regions, performing the task known as entity grounding. Some heads can even detect the syntactic relations between non-entity words and image regions, tracking, for example, associations between verbs and regions corresponding to their arguments. We denote this ability as \emphsyntactic grounding. We verify grounding both quantitatively and qualitatively, using Flickr30K Entities as a testbed.
@inproceedings{li2020what, author = {Li, Liunian Harold and Yatskar, Mark and Yin, Da and Hsieh, Cho-Jui and Chang, Kai-Wei}, title = {What Does BERT with Vision Look At?}, booktitle = {ACL (short)}, presentation_id = {https://virtual.acl2020.org/paper_main.469.html}, year = {2020} }See the full version of this paper.hot off the press -- VisualBert: A simple and performant baseline for vision and language. Language + image region proposals -> stack of Transformers + pretrain on captions = SOTA or near on 4 V&L problems. https://t.co/uQ4O2Jhe2S @LiLiunian +Cho-Jui Hsieh +Da Yin @kaiwei_chang
— Mark Yatskar (@yatskar) August 12, 2019A Transformer-based Approach for Source Code Summarization
Wasi Ahmad, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang, in ACL (short), 2020.
QA Sessions: 9A Summarization, 10B Summarization Paper link in the virtual conferenceFull Text Slides Code BibTeX DetailsDetails
Generating a readable summary that describes the functionality of a program is known as source code summarization. In this task, learning code representation by modeling the pairwise relationship between code tokens to capture their long-range dependencies is crucial. To learn code representation for summarization, we explore the Transformer model that uses a self-attention mechanism and has shown to be effective in capturing long-range dependencies. In this work, we show that despite the approach is simple, it outperforms the state-of-the-art techniques by a significant margin. We perform extensive analysis and ablation studies that reveal several important findings, e.g., the absolute encoding of source code tokens’ position hinders, while relative encoding significantly improves the summarization performance. We have made our code publicly available to facilitate future research.
@inproceedings{ahmad2020transformer, author = {Ahmad, Wasi and Chakraborty, Saikat and Ray, Baishakhi and Chang, Kai-Wei}, title = {A Transformer-based Approach for Source Code Summarization}, booktitle = {ACL (short)}, year = {2020}, presentation_id = {https://virtual.acl2020.org/paper_main.449.html} }Related Publications
- Context Attentive Document Ranking and Query Suggestion, SIGIR, 2019
- Multifaceted Protein-Protein Interaction Prediction Based on Siamese Residual RCNN, ISMB, 2019
- Multi-Task Learning for Document Ranking and Query Suggestion, ICLR, 2018
- Intent-aware Query Obfuscation for Privacy Protection in Personalized Web Search, SIGIR, 2018
- Counterexamples for Robotic Planning Explained in Structured Language, ICRA, 2018
- Word and sentence embedding tools to measure semantic similarity of Gene Ontology terms by their definitions, Journal of Computational Biology, 2018
Energy Efficient Pre-Training
Contextual representation models greatly improve various NLP tasks. However they are difficult to train due to their large parameter size and high computational complexity. We present a paper to drastically reduce the trainable parameters and training time.
Efficient Contextual Representation Learning With Continuous Outputs
Liunian Harold Li, Patrick H. Chen, Cho-Jui Hsieh, and Kai-Wei Chang, in TACL, 2019.
QA Sessions: 4B Machine Learning, 5B Machine Learning Paper link in the virtual conferenceFull Text Slides BibTeX DetailsDetails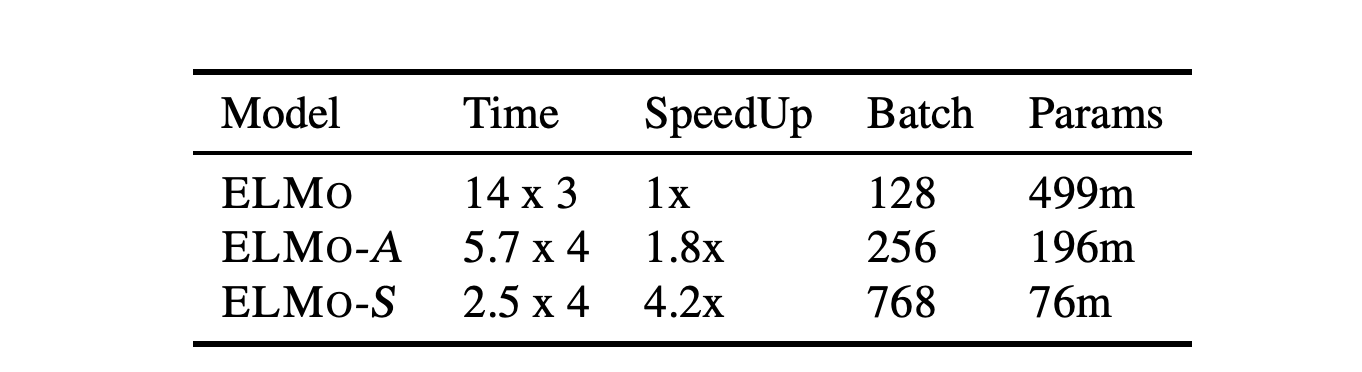
Contextual representation models have achieved great success in improving various downstream natural language processing tasks. However, these language-model-based encoders are difficult to train due to their large parameter size and high computational complexity. By carefully examining the training procedure, we observe that the softmax layer, which predicts a distribution of the target word, often induces significant overhead, especially when the vocabulary size is large. Therefore, we revisit the design of the output layer and consider directly predicting the pre-trained embedding of the target word for a given context. When applied to ELMo, the proposed approach achieves a 4 times speedup and eliminates 80% trainable parameters while achieving competitive performance on downstream tasks. Further analysis shows that the approach maintains the speed advantage under various settings, even when the sentence encoder is scaled up.
@inproceedings{li2019efficient, author = {Li, Liunian Harold and Chen, Patrick H. and Hsieh, Cho-Jui and Chang, Kai-Wei}, title = {Efficient Contextual Representation Learning With Continuous Outputs}, booktitle = {TACL}, year = {2019} }(4/5) Interested in building efficient NLP models? Check out 8) our talk on building text classifier under test-time budget https://t.co/8cYW1QWN6w (Tue) and 9) another recent TACL paper on training ELMo with continuous outputs https://t.co/Fyv3tKgQ6A.
— Kai-Wei Chang (@kaiwei_chang) November 3, 2019Related Publications
- Robust Text Classifier on Test-Time Budgets, EMNLP (short), 2019
- Distributed Block-diagonal Approximation Methods for Regularized Empirical Risk Minimization, Machine Learning Journal, 2019
- Structured Prediction with Test-time Budget Constraints, AAAI, 2017
- A Credit Assignment Compiler for Joint Prediction, NeurIPS, 2016
- Learning to Search for Dependencies, Arxiv, 2015
- Learning to Search Better Than Your Teacher, ICML, 2015
- Structural Learning with Amortized Inference, AAAI, 2015
Enhance Contextulaized Encoder
We present the following two papers to enhance contextualized encoders by 1) injecting pronunciation embedding for Pun Recognition, and 2) by incorporating tree structure to capture compositional sentiment semantics for sentiment analysis.
SentiBERT: A Transferable Transformer-Based Architecture for Compositional Sentiment Semantics
Da Yin, Tao Meng, and Kai-Wei Chang, in ACL, 2020.
QA Sessions: 6B Sentiment Analysis, 8A Sentiment Analysis Paper link in the virtual conferenceFull Text Slides Code BibTeX DetailsDetails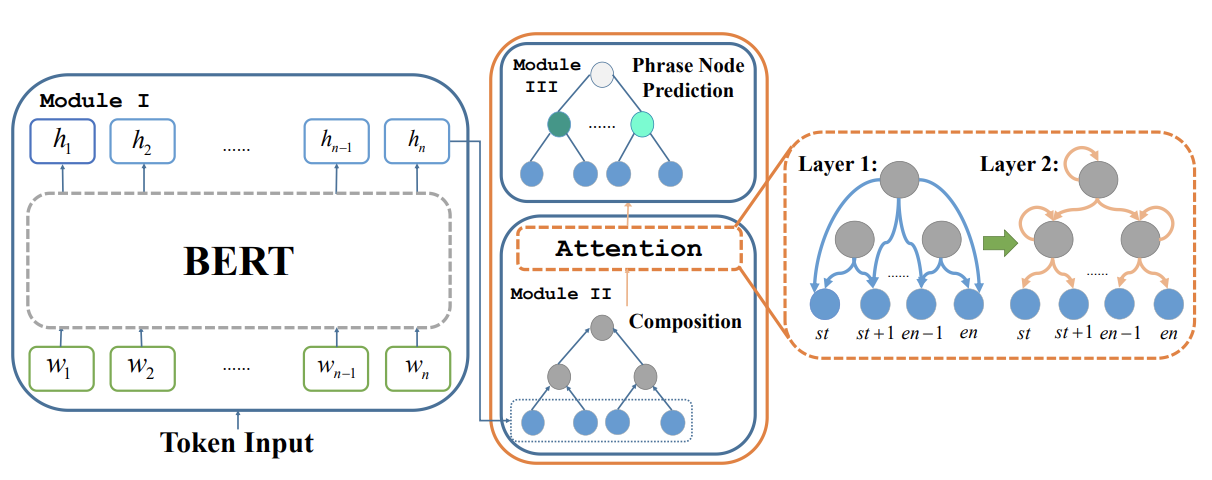
We propose SentiBERT, a variant of BERT that effectively captures compositional sentiment semantics. The model incorporates contextualized representation with binary constituency parse tree to capture semantic composition. Comprehensive experiments demonstrate that SentiBERT achieves competitive performance on phrase-level sentiment classification. We further demonstrate that the sentiment composition learned from the phrase-level annotations on SST can be transferred to other sentiment analysis tasks as well as related tasks, such as emotion classification tasks. Moreover, we conduct ablation studies and design visualization methods to understand SentiBERT. We show that SentiBERT is better than baseline approaches in capturing negation and the contrastive relation and model the compositional sentiment semantics.
@inproceedings{yin2020sentibert, author = {Yin, Da and Meng, Tao and Chang, Kai-Wei}, title = {SentiBERT: A Transferable Transformer-Based Architecture for Compositional Sentiment Semantics}, booktitle = {ACL}, year = {2020}, presentation_id = {https://virtual.acl2020.org/paper_main.341.html} }Related Publications
- Relation-Guided Pre-Training for Open-Domain Question Answering, EMNLP-Finding, 2021
- An Integer Linear Programming Framework for Mining Constraints from Data, ICML, 2021
- Generating Syntactically Controlled Paraphrases without Using Annotated Parallel Pairs, EACL, 2021
- Clinical Temporal Relation Extraction with Probabilistic Soft Logic Regularization and Global Inference, AAAI, 2021
- GPT-GNN: Generative Pre-Training of Graph Neural Networks, KDD, 2020
- PolicyQA: A Reading Comprehension Dataset for Privacy Policies, EMNLP-Finding (short), 2020
- Building Language Models for Text with Named Entities, ACL, 2018
- Learning from Explicit and Implicit Supervision Jointly For Algebra Word Problems, EMNLP, 2016
"The Boating Store Had Its Best Sail Ever": Pronunciation-attentive Contextualized Pun Recognition
Yichao Zhou, Jyun-Yu Jiang, Jieyu Zhao, Kai-Wei Chang, and Wei Wang, in ACL, 2020.
QA Sessions: 1B Application, 5B Application Paper link in the virtual conferenceFull Text Slides Code BibTeX DetailsDetails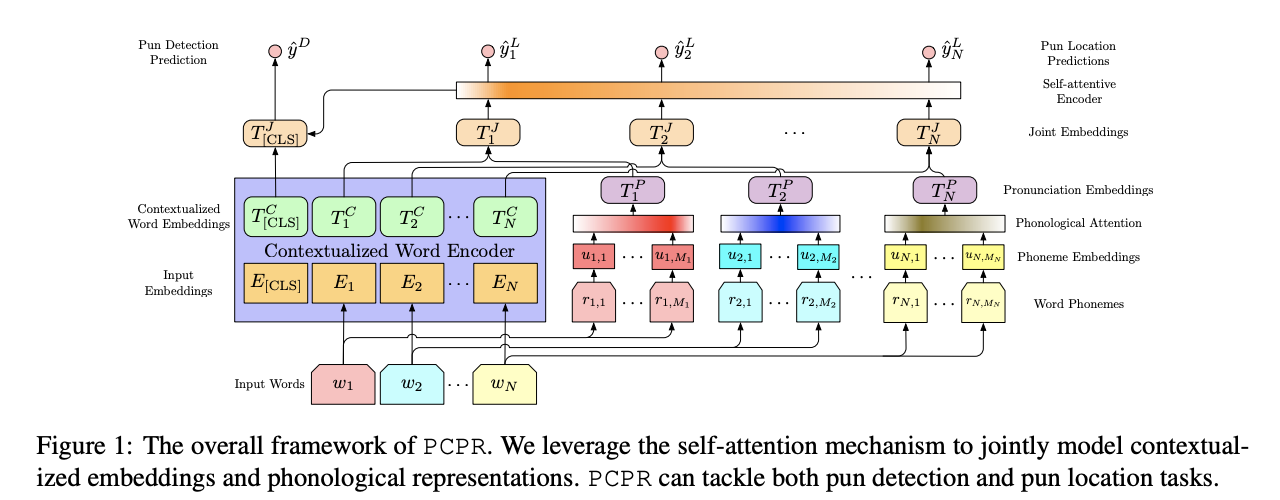
Humor plays an important role in human languages and it is essential to model humor when building intelligence systems. Among different forms of humor, puns perform wordplay for humorous effects by employing words with double entendre and high phonetic similarity. However, identifying and modeling puns are challenging as puns usually involved implicit semantic or phonological tricks. In this paper, we propose Pronunciation-attentive Contextualized Pun Recognition (PCPR) to perceive human humor, detect if a sentence contains puns and locate them in the sentence. PCPR derives contextualized representation for each word in a sentence by capturing the association between the surrounding context and its corresponding phonetic symbols. Extensive experiments are conducted on two benchmark datasets. Results demonstrate that the proposed approach significantly outperforms the state-of-the-art methods in pun detection and location tasks. In-depth analyses verify the effectiveness and robustness of PCPR.
@inproceedings{zhou2020boating, author = {Zhou, Yichao and Jiang, Jyun-Yu and Zhao, Jieyu and Chang, Kai-Wei and Wang, Wei}, title = {"The Boating Store Had Its Best Sail Ever": Pronunciation-attentive Contextualized Pun Recognition}, booktitle = {ACL}, presentation_id = {https://virtual.acl2020.org/paper_main.75.html}, year = {2020} }